




こんにちは、技術本部SRE部ZOZOSREチームの斉藤です。普段はZOZOTOWNのオンプレミスとクラウドの構築・運用に携わっています。またDBREとしてZOZOTOWNのデータベース全般の運用・保守も兼務しております。
ZOZOTOWNではSQL Serverを中心とした各種DBMSが稼働しています。その中で、Amazon RDS for SQL Server(以下、RDS)を使用したデータベースが存在します。これらは、トラフィックの増減が激しいZOZOTOWNのサービスにおいて、オンデマンドでスケール可能なデータベースとして運用されています。
本記事では、クライアントであるEC2(以下、Webサーバー)とRDSの間にデータベースプロキシをnginx TCP Load Balancerで構築し、ロードバランシングを実現した事例を紹介します。参照系データベースのアクセスに関してロードバランシングの一例としてご参考になればと思います。また、詳細は後述していますが、Amazon RDS Proxyにはバランシング機能がありません。「無いものは自前で作る」というZOZOの文化にも触れていただけたら幸いです。
目次
- 目次
- データベースプロキシを構築した背景と課題
- ソリューション選定
- nginx TCP Load Balancerを構築する
- nginx TCP Load Balancerを動作検証する
- 本番環境へ実装する
- まとめ
- おわりに
データベースプロキシを構築した背景と課題
RDSは、Webサーバーからのリクエストを直接受けており、セール時などの高トラフィックが予想される日は、RDSとWebサーバーをスケールアウトしてシステムを増強させています。RDS 1インスタンスあたりのWebサーバー接続数を計算し、各Webサーバーに対して、接続先を変更する必要がありました。また、RDSの障害で接続ができなくなってしまった場合、問題の起きたインスタンスからの切り離しを手動で行う必要がありました。運用を効率化するためには、ヘルスチェックとロードバランシングの機能を持ったサーバーが必要と判断し、導入することにしました。先述した以外にもロードバランシング機能を持つサーバーの導入は、いくつかのメリットがあると考えました。
ロードバランシング機能を持つサーバーのメリット
- 運用の効率化
- Webサーバーの接続先変更や切り離しにかかる運用コストが削減できる。
- 可用性の向上
- RDS障害時の接続先変更を自動化することで、エラーを最小限に抑えて稼働させ続けられる。
- コストの最適化
- RDS障害時の接続先変更を自動化することで、RDSのフェイルオーバーは不要となり、マルチAZが廃止でき、RDSコストを1/2にできる。
マルチAZが廃止できる理由について補足させていただきます。AZ障害が発生した場合に備え、マルチAZ無効状態で各AZにRDSインスタンスを配置した状態にしておきます。障害発生時は、正常なAZ側のRDSインスタンスに自動で接続が切り替われば、サービス継続が可能となります。従来の手動切り替えによる対応が不要にできれば、障害時のサービス継続性が向上し、マルチAZも不要となるので通常時のコスト削減に繋がります。
ソリューション選定
Amazon RDS Proxy
Amazon RDS Proxyにロードバランシングの機能が無いか調査しました。接続プーリングなどの魅力的な機能はあったもののロードバランシング機能はありませんでした。Amazon RDS Proxyのより詳細な情報は下記に記載されていますので興味のある方は Amazon RDS Proxyを参照してください。
Elastic Load Balancing Network Load Balancer (NLB)
(2023/06/20追記)AWSのElastic Load Balancing Network Load Balancer(以下、NLB)も候補の1つとして調査しました。NLBはターゲットの指定にFQDNが使用できず、動的にIPアドレスが変更されてしまうRDSには対応できませんでした。RDSの動的なIPアドレス変更の詳細情報は下記に記載されていますので興味のある方は Amazon RDS DB インスタンスに割り当てられた IP アドレスについてを参照してください。 (追記ここまで)
nginx TCP Load Balancer
nginxのロードバランシング機能を調査してみるとHTTP、TCP、UDPでロードバランシングが実現でき、パッシブヘルスチェックとアクティブヘルスチェックを使用できました。
(2023/06/20追記)また、詳細は「UNIXドメインソケットを設定」に記載していますが、FQDNを指定した名前解決が可能でRDSの動的なIPアドレス変更に対応できることがわかりました。(追記ここまで)
nginx TCP Load Balancerのより詳細な情報は下記に記載されていますので興味のある方は
TCP and UDP Load Balancingを参照してください。
今回はnginx TCP Load Balancerを使用してデータベースプロキシを構築することにしました。
nginx TCP Load Balancerを構築する
以下の手順でnginx TCP Load Balancerを構築していきます。
- Dockerコンテナでnginxインスタンスを作成
- nginx.confを編集してロードバランサーとして設定
- ヘルスチェックを設定
- UNIXドメインソケットを設定
- バランシングアルゴリズムの設定
- keepalive(idle interval count)を設定
Dockerコンテナでnginxインスタンスを作成
Docker Hubで公開されているnginx Open Sourceイメージを使用して、Dockerコンテナでnginxインスタンスを作成しました。
nginx.confを編集してロードバランサーとして設定
ロードバランサーを構成するにはstreamコンテキスト内にupstreamグループを作成します。
stream {
resolver xxx.xxx.xxx.xxx valid=5s;
error_log /dev/stderr info;
upstream rds-tcp {
least_conn;
server unix:/var/run/rds_1a_001.sock fail_timeout=10s max_fails=100 max_conns=0 weight=1;
server unix:/var/run/rds_1c_001.sock fail_timeout=10s max_fails=100 max_conns=0 weight=1;
}
server {
listen 1433 so_keepalive=10m:1m:10 reuseport;
proxy_socket_keepalive on;
proxy_connect_timeout 15s;
proxy_pass rds-tcp;
}
ヘルスチェックを設定
Webサーバーからのリクエストに対して、サーバーのレスポンスを監視するパッシブヘルスチェックを設定します。ヘルスチェックの設定はupstreamグループ内に記述したサーバーのパラメータで定義します。定義したパラメータの「fail_timeout」と「max_fails」がヘルスチェックの設定部分です。
upstream rds-tcp {
server unix:/var/run/rds_1a_001.sock fail_timeout=10s max_fails=100 max_conns=0 weight=1;
パラメータについては次の通りです。
- fail_timeout
- サーバーとの通信試行がmax_failsで指定された回数失敗すると、fail_timeoutに設定された期間サーバーが利用できないと見なします。
- max_fails
- サーバーとの通信試行の失敗回数を設定します。指定した回数リクエストに失敗するとfail_timeoutで設定された期間、サーバーが利用できないと見なします。
- max_conns
- プロキシサーバーへの同時接続の最大数を制限します。デフォルト値の0は、無制限を意味します。
- weight
- サーバーの重みを設定します。
UNIXドメインソケットを設定
無料版のnginxは起動時にしか名前解決がされません。RDS側の動的な変更に対応するため、UNIXドメインソケットを使用し、名前解決することにしました。UNIXドメインソケットの設定もstreamコンテキストに記述します。
(2023/06/20修正)nginxの名前解決は無料版と有料版で解決方法に違いがあります。UNIXドメインソケットを使用することで、無料版でも有料版と同等の動的な名前解決をできるようにしました。無料版のnginxは起動時にしか名前解決をしないことが課題でしたが、RDS側の動的なIPアドレス変更に対応できました。
(2023/06/20修正)streamコンテキストにresolverの設定を記述します。
stream {
resolver xxx.xxx.xxx.xxx valid=5s;
(2023/06/20修正)serverコンテキストにproxy先をset変数で定義します。
server {
listen unix:/var/run/rds_1a_001.sock;
set $rds_1a_001 "rds-1a-001.sample.ap-northeast-1.rds.amazonaws.com";
proxy_pass $rds_1a_001:1433;
}
バランシングアルゴリズムの設定
nginx TCP Load Balancerには3種類のバランシングアルゴリズムが用意されています。
- Round Robin
- 振り分け先のサーバーへのリクエストを均等に振り分ける方式(デフォルト)
- Least Connections
- アクティブな接続数が最も少ないサーバーに振り分けられるような方式
- hash
- 同じIPアドレスからのリクエストは、同じ振り分け先サーバーへ振り分ける方式
今回はLeast Connectionsを採用することにしました。バランシングアルゴリズムの設定もstreamコンテキストに記述します。
least_conn; server unix:/var/run/rds_1a_001.sock fail_timeout=10s max_fails=100 max_conns=0 weight=1; server unix:/var/run/rds_1c_001.sock fail_timeout=10s max_fails=100 max_conns=0 weight=1;
keepalive(idle interval count)を設定
アクティブ接続を最大で10分間継続させ、1分間隔で10回アイドル状態になっていないかのチェックを行うようにします。keepaliveのパラメータはlistenソケットに設定します。
server {
listen 1433 so_keepalive=10m:1m:10 reuseport;
proxy_socket_keepalive on;
proxy_connect_timeout 15s;
proxy_pass rds-tcp;
}
nginx TCP Load Balancerを動作検証する
RDSを2インスタンス用意し、Webサーバーから接続をバランシングしてみます。nginx TCP Load Balancerへ複数のWebサーバーからリクエストを投げ、RDS側で参照されるテーブルをロックします。リクエストタイムアウトが起きた場合、nginx TCP Load Balancerがどういった動作をするか確認します。
ロードバランサーの設定
- バランシングアルゴリズム
- Least Connectionsを採用します。
- ヘルスチェック
- 10秒間にリクエストが100failしたらRDSのダウンとみなすように設定します。
- 障害時、手動での接続切り替えに数十分ほど要していましたが、自動で検知と切り替えができれば数秒ほどで完了し、大幅に時間短縮できます。
- keepalive(idle interval count)
- アクティブ接続を最大で10分間継続させ、1分間隔で10回アイドル状態になっていないかのチェックを行います。
- 1分間隔のアイドルチェックにより、該当コネクションを利用するリクエストがゼロになっても1分間はそのコネクションを維持させます。これにより、コネクションの作成/破棄が頻繁に行われることによる負荷を削減します。
upstream rds-tcp {
least_conn;
server unix:/var/run/rds_1a_001.sock fail_timeout=10s max_fails=100 max_conns=0 weight=1;
server unix:/var/run/rds_1c_001.sock fail_timeout=10s max_fails=100 max_conns=0 weight=1;
}
server {
listen 1433 so_keepalive=10m:1m:10 reuseport;
proxy_socket_keepalive on;
proxy_connect_timeout 15s;
proxy_pass rds-tcp;
}
実際に動作検証する
いくつかのパターンで動作検証します。
- 通常の状態でリクエストを投げ、ロードバランシングが動作するか確認する
- 片方のRDSにテーブルロックをかけ、タイムアウトを発生させ、ヘルスチェックが動作するか確認する
- 両方のRDSにテーブルロックをかけ、タイムアウトを発生させ、動作確認する
- リクエストを停止させ、keepaliveが動作するか確認する
リクエストを開始する
通常の状態でリクエストを投げ、ロードバランシングが動作するか確認しました。各Webサーバーのセッションが均等にバランシングされました。

片方のRDSにテーブルロックをかける
片方のRDSにテーブルロックをかけて、タイムアウトを発生させ、ヘルスチェックが動作するか確認します。一瞬パラっとエラーが出た後は、一定間隔でパラパラと30秒タイムアウトが発生しました。これは、nginxのパッシブヘルスチェックによって、RDSのステータスを定期的に確認するためです。アクティブヘルスチェックと違い、実際のリクエストを使ってヘルスチェックするため、想定通りの挙動です。

両方のRDSにテーブルロックをかける
全リクエストがタイムアウトしましたが、ロック解除するとエラーなくリクエストが流れました。

リクエストを停止させる
Webサーバーからのリクエストを停止させてみます。停止直後はRDSへのコネクションが維持された状態になりました。
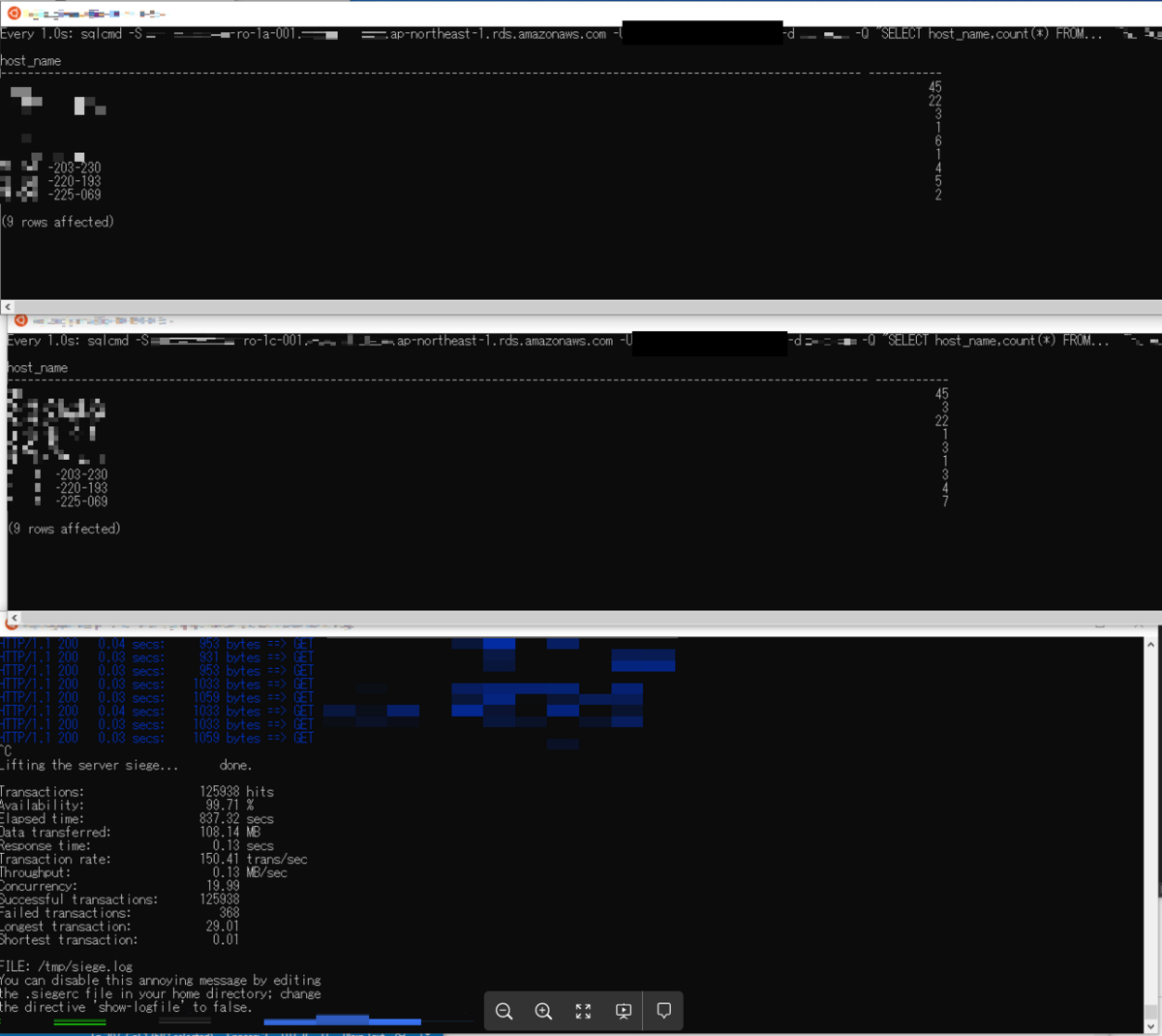
1分後にRDSへのコネクションは破棄されました。想定通りにkeepaliveが動作してくれました。

本番環境へ実装する
動作検証が成功したので、本番環境への実装を考えます。RDSとWebサーバーの柔軟なスケールアウトに対応する必要があるのと実装後の運用について考慮しました。
niginx TCP Load Balancerをコンテナで構築する
Amazon EKSのkubernetesクラスターを用いて構築することで、Proxyの柔軟なスケールアウトを可能にしました。予期しない高負荷に備え、Horizontal Pod Autoscalerでのオートスケールを実現しました。
アーキテクチャ図

Proxy設定をGitHubで管理する
設定変更の運用は、ArgoCDを用いてGitOps化し、リソース変更や運用をGitHubの操作でできるようにしました。
本番環境へ実装後の負荷状況
ZOZOTOWNの年間を通して、トラフィック量がトップクラスに多い期間が年末年始に開催される冬セールです。2022-2023期の冬セールで増強した1300台以上のWebサーバーからのリクエストを6台のProxyで捌くことができました。セール開始時にCPU使用率が上昇しましたが、許容範囲内に収まり、全体を通して安定的に稼働してくれました。
冬セール時のCPU使用率

まとめ
本記事では、WebサーバーとRDSの間にデータベースプロキシをnginx TCP Load Balancerで構築した際の事例を紹介させていただきました。課題として挙げていた、WebサーバーのRDS接続設定に関する運用効率の向上やRDSのコスト最適化に繋がったと感じています。
アクティブなupstream serverが全ダウンした際に、設定しておいたSQL Serverにリクエストを流すことができるbackupオプションというものがあります。引き続き、nginx TCP Load Balancerをパワーアップさせることができるオプションを検証していきたいです。
おわりに
ZOZOでは、一緒にサービスを作り上げてくれる仲間を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!