 2回目の投稿です。rks_mnkiです。
インフラエンジニア的なことをやっています。
2回目の投稿です。rks_mnkiです。
インフラエンジニア的なことをやっています。
さて今回は、「ブラウザ環境上の操作のみでシステムログを取得する環境構築」について、実際の設定内容などを踏まえながらご紹介したいと思います。
目次:
- 1.導入を進める背景、課題
- 2.システム要件
- 3.利用ツールの選定
- 4.システム全体の構成イメージ
- 5.各種コンポーネントの説明
- 6.Docker Composeによる実装
- 7.操作の流れをご紹介
- 8.まとめ
1.導入を進める背景、課題
弊社では、日々のシステム運用業務の中でインフラ以外の開発やカスタマーサポート部門でも、エラー調査や顧客からの問い合わせ対応などでログを必要とすることがあります。
その際、従来はシステムが稼働する本番環境上にある専用サーバに対して特殊な経路でリモートログインし、以下のような流れでログを取得していました。
- 取得したい対象サーバ名を記載したリストを作成
- 定期的に「なんらかの処理」が走って、対象サーバから決められたログが取得されている
- その中身を確認
ここで「なんらかの処理」と表現したのは、このログを取得する仕組みが大昔に作成されたものであり、正直あまり詳しく理解できていない為です。
また、Linux環境上での操作となるために、あまり慣れてない部門のメンバーでは対応しづらく、そのほかの問題もあって利用頻度は低い状態でした。
結局は、インフラ部門に対してログの提供依頼があり、その都度インフラにてログを取得するという対応が発生しています。
課題をまとめると、このようになります。
- 用意されているログ取得の仕組みが古すぎてメンテナンスされていない
- 現行の仕組みでは取得対象サーバを登録してから最長5分の待ち時間が発生
- Linux環境(コマンドライン操作)に慣れていないメンバーには使いづらい
- ログの容量が大きい環境では処理がタイムアウトになることも
↓↓
用意された仕組みは使われず、インフラへのログ提供依頼ケースが多くなる
そのため、ログ取得という「生産性の高くない」業務稼働がインフラ部門で一定の割合を占めてました。
あわせて、昔の仕組みを理解して改修するのは嫌だったので、それならイチから新たにログを取得できる仕組みを構築しようと考えました。
2.システム要件
構築するにあたり、まずは以下のようなシステム要件を検討しました。
- 基本的にブラウザ環境での操作で完結させる
- 取得したい対象期間を指定可能
- 利用ユーザが本番環境へのログインは不要
その他、以下の前提条件を定義。
- 対象サーバは1台のみ指定
- 各部署単位で必要なログの種類を選定し、それ以外は選択できないようにする
これ以外のケースでログが必要な場合は、これまで通り別途インフラへの対応を依頼頂く運用を想定しています。
3.利用ツールの選定
既にインフラでの業務で利用しているJenkinsでのジョブ実行をベースに検討。
- Jenkins+各種スクリプト
- promtail+loki+Grafana
- Nginx
今回は、とりあえず取得したログの中身をそのまま閲覧できればいいので、比較的シンプルに導入できそうなツールを検討しました。
4.システム全体の構成イメージ
以下のような構成を検討し、構築を進めました。
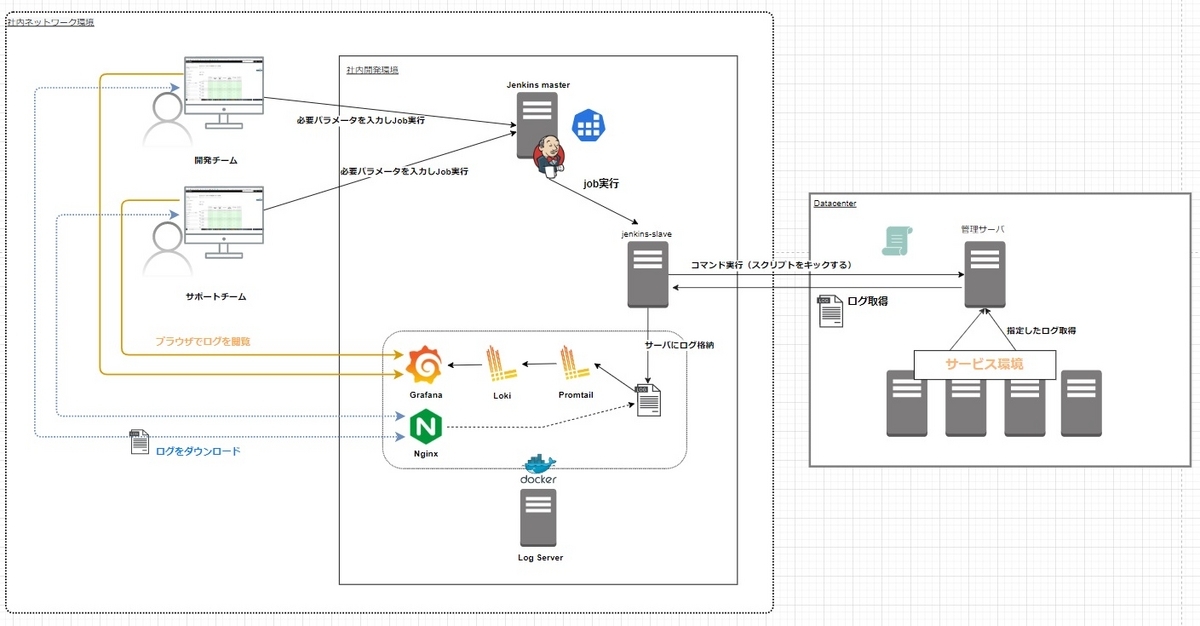
ログデータを取得するためのダウンロードサイトと、ログ閲覧用サイトは別々で提供するようにしました。
なお、このイメージ図では掲載できていないが、JenkinsジョブのURLなども含めてアクセス先URLリンクをまとめたサイトを1つ構築して、Nginxにて提供しています。
5.各種コンポーネントの説明
今回、長期間のログに関する傾向分析ではなく、必要な期間に限定したログの内容を参照する目的にフォーカスして構成しています。
Jenkinsジョブ
- 対象ホストやログ、期間を指定できるユーザインタフェースを提供
- サービス環境内の管理サーバに設置されたスクリプトを実行して、必要なログを取得
- 取得したログを「ログサーバ」に格納
【補足】
指定されたパラメータは、スクリプトに引き渡されて実行されます。
その中で、以下のコマンドにて「対象期間」に該当するログファイルを抽出しています。
find {対象ログのフルパス*} -newermt '{開始日付} 0:0:0' -and ! -newermt '{終了日付} 23:59:59'
この時、ログファイルの「タイムスタンプ(最終更新日時)」をもとに検索をかけるので、ログの中身で記録されている日時ではないことに注意です。
例)1週間単位でログローテーションされているケースが多い
-rw------- 1 root root 346K 3月 12 04:02 messages.5.gz -rw------- 1 root root 2.1M 3月 19 04:02 messages.4.gz -rw------- 1 root root 1.9M 3月 26 04:02 messages.3.gz -rw------- 1 root root 2.0M 4月 2 04:02 messages.2.gz -rw------- 1 root root 2.2M 4月 9 04:02 messages.1.gz -rw------- 1 root root 33M 4月 15 18:03 messages
上記における問題あるケースとして、対象期間を【4/4~4/6】で指定してしまうと、該当するタイムスタンプのログファイルが存在しないので、何もアクションされない事になります。
当然、ログの中身としては該当期間のものが出力されていますが、ファイル単位での検索処理となっているため、このような動きとなってしまいます。
そのため、ジョブ実行時にログが存在しないといったエラーになると、以下のようにメッセージを返すようにしています。
#### WARNING ####
No data. Please check HostName or change the specified period and try again.
Promtail
- 所定の位置に格納されたログを収集し、Lokiに転送
- 各ログの種別に応じてタグ付け
- Timestampの設定
サンプルコード
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
clients:
- url: http://loki:3100/loki/api/v1/push
scrape_configs:
- job_name: messages
static_configs:
- targets:
- localhost
labels:
job: messages
__path__: /mnt/data/collect_logs/*/*/messages*
デフォルト設定では、ログを収集した時刻(promtailが読み込んだ時刻)をタイムスタンプとして扱う事になります。これでは、ログが出力されている日時で検索したいケースに対応することができません。
そのため、ログに出力された日時をタイムスタンプとして扱えるように設定します。
具体的には、timestampに関する設定によりデータを解析し、Lokiにて保存されたログエントリのタイムスタンプを上書きします。
例)/var/log/messagesの場合:このログに出力されている日時をタイムスタンプとして認識させる。
Apr 9 05:54:04 {ホスト名} systemd[1]: session-51560.scope: Succeeded.
pipeline_stagesを以下のように設定。
pipeline_stages:
- match:
selector: '{job="messages"}'
stages:
- regex:
expression: "^(?s)(?P<time>.+? \\d\\d:\\d\\d:\\d\\d):? (?P<content>.*)$"
- timestamp:
source: time
format: 'Jan _2 15:04:05'
location: Asia/Tokyo
regexにて日時のタイムスタンプを正規表現で指定し、time変数に格納。
その下部にあるtimestampのsourceで先ほど設定したtime変数を指定し、formatでタイムスタンプ形式を指定。
この辺りは、公式サイトなどを参考にしながらトランアンドエラーにて設定した為、あまり詳しく理解できていませんので、適切な設定方法があればご指摘ください。。
Loki
- ログの集約と検索が行える
- Grafanaと連携
※基本的には、configはデフォルトのまま運用。
Grafana
- 可視化プラットフォーム
- Lokiから連携された時系列データを処理する
Nginx
- Webによるログのダウンロードサイトを提供
- URLリンクの管理サイトを提供
デフォルトのconfigを利用し、必要に応じてHTMLファイルを作成。
6.Docker Composeによる実装
今回、上記の各種コンポーネントに関する複数のコンテナを、Docker Composeにより一括で管理しています。
サンプル)docker-compose.yml
version: '3'
services:
nginx:
image: nginx
container_name: nginx
environment:
TZ: Asia/Tokyo
ports:
- "80:80"
volumes:
- /data/sample-log_collect/dev:/usr/share/nginx/html/download/sample-develop
- /data/sample-log_collect/cs:/usr/share/nginx/html/download/sample-support
- /log_aggregation/nginx/config/default.conf:/etc/nginx/conf.d/default.conf
- /log_aggregation/nginx/config/index.html:/usr/share/nginx/html/index.html
- /log_aggregation/nginx/config/main.css:/usr/share/nginx/html/main.css
- /log_aggregation/nginx/config/manual.html:/usr/share/nginx/html/manual.html
networks:
- sample-log_aggr
promtail:
image: grafana/promtail:2.3.0
container_name: promtail
environment:
TZ: Asia/Tokyo
command: -config.file=/mnt/config/promtail-config.yaml
volumes:
- type: bind
source: /data/sample-log_collect
target: /mnt/data/collect_logs
- type: bind
source: /log_aggregation/promtail/config/promtail-config.yaml
target: /mnt/config/promtail-config.yaml
networks:
- sample-log_aggr
loki:
image: grafana/loki:2.3.0
container_name: loki
environment:
TZ: Asia/Tokyo
ports:
- 3100:3100
command: -config.file=/mnt/config/loki-config.yaml
volumes:
- /log_aggregation/loki/config/loki-config.yaml:/mnt/config/loki-config.yaml
networks:
- sample-log_aggr
grafana:
image: grafana/grafana:latest
container_name: grafana
environment:
TZ: Asia/Tokyo
hostname: grafana
volumes:
- ./data/grafana:/var/lib/grafana
networks:
- sample-log_aggr
ports:
- 8080:3000
user: "0:"
networks:
sample-log_aggr:
name: sample-log_aggr
ipam:
driver: default
config:
- subnet: 10.***.***.0/24
なお、デフォルトだとdockerのログはdocker-compose logsコマンドで確認が必要ですが、正直使いづらく過去ログも保管しておきたいので、syslog経由でログを出力するように設定しています。
以下の設定を各コンテナごとに追記。
logging:
driver: syslog
options:
syslog-facility: daemon
tag: log-aggregation/{{.Name}}/{{.ID}}
すると、このようなログが生成されます。
ファイル名:/var/log/docker/log-aggregation.log
ログの中身:
Apr 15 17:46:07 HOST log-aggregation/loki/197fdf4139ac[207994]: level=info ts=2023-04-15T08:46:07.056567716Z caller=table_manager.go:476 msg="creating table" table=index_19073
準備が整いdocker compose up -dコマンドにて起動すると、以下のようなプロセスが生成されます。
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES ab60c21fffff grafana/grafana:latest "/run.sh" 34 hours ago Up 34 hours 0.0.0.0:8080->3000/tcp grafana ce89712d582a nginx "/docker-entrypoint.…" 34 hours ago Up 34 hours 0.0.0.0:80->80/tcp nginx 197fdf4139ac grafana/loki:2.3.0 "/usr/bin/loki -conf…" 34 hours ago Up 34 hours 0.0.0.0:3100->3100/tcp loki 691b10c43729 grafana/promtail:2.3.0 "/usr/bin/promtail -…" 34 hours ago Up 34 hours promtail
7.操作の流れをご紹介
- まず、対象サーバや期間を、取得したいログの種別を選択してJenkinsジョブを実行します。
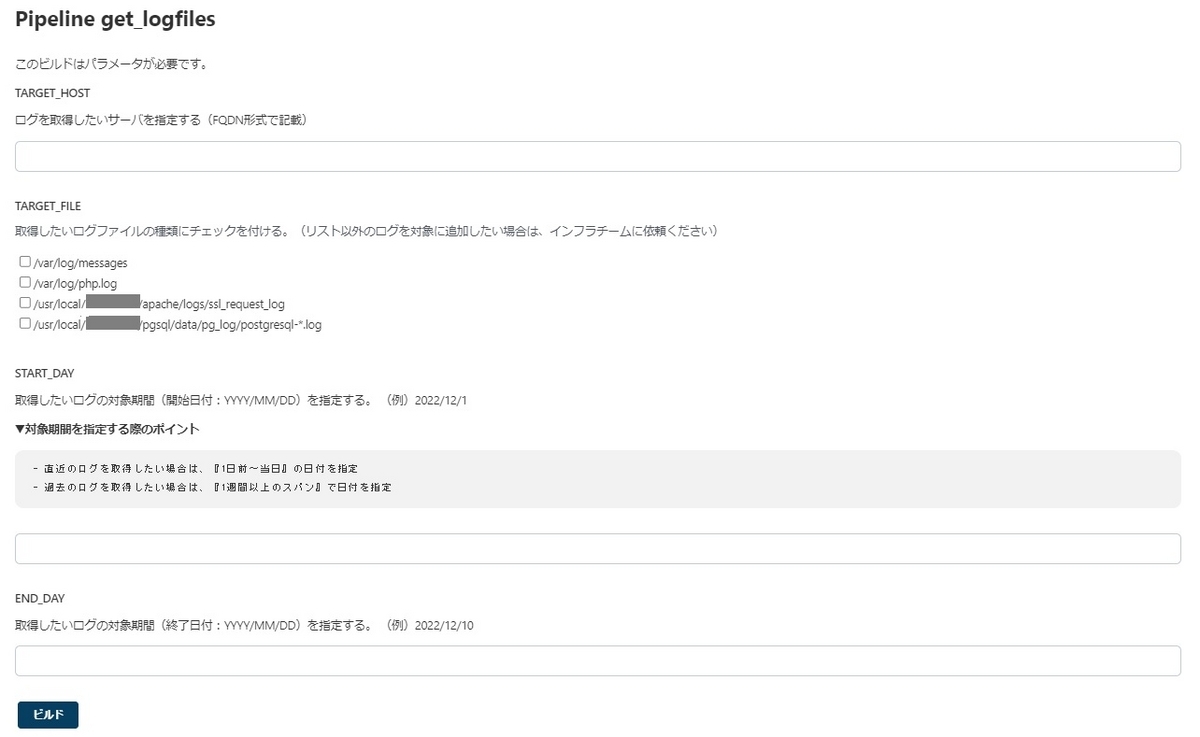
- ジョブが正常実行されたら、ブラウザ上より欲しいログファイルをダウンロードできるようになります。
対象ログファイルをクリックすると、ダウンロードされます。この場合、利用ユーザのローカル環境にログをダウンロードし、テキストエディタ等でログを確認するケースを想定しています。

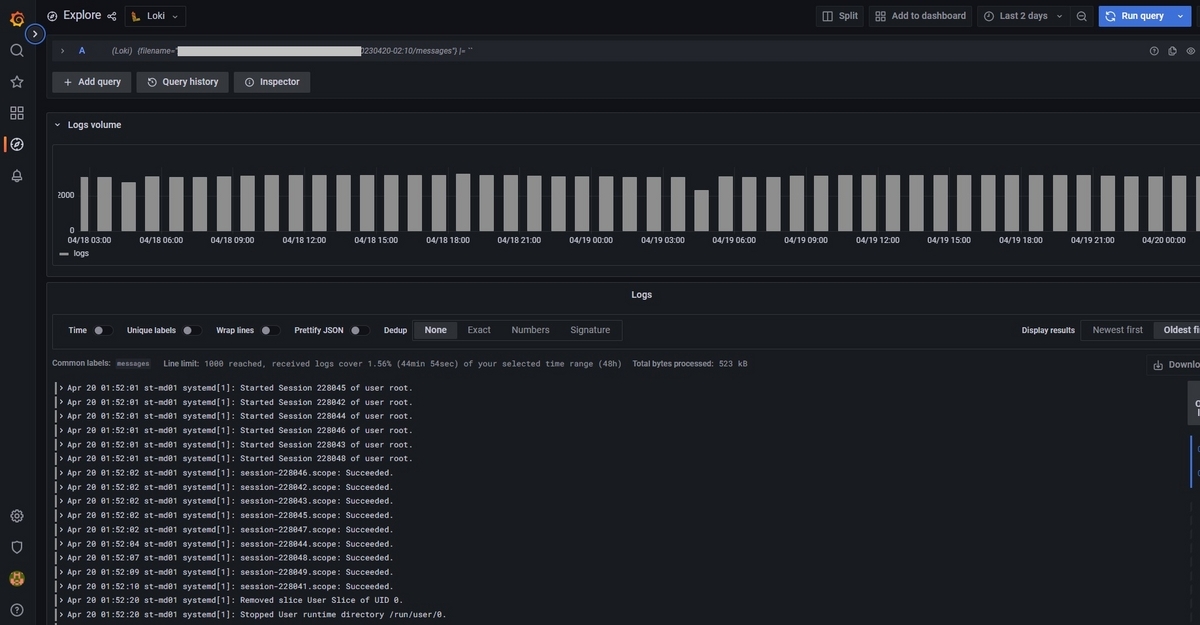
- または、Grafanaによるブラウザ上でのログの閲覧も可能です。
ダッシュボード画面も用意していますが、左メニューからExploreを選択すると、取り込んだログファイルを指定して、その内容を閲覧することができます。
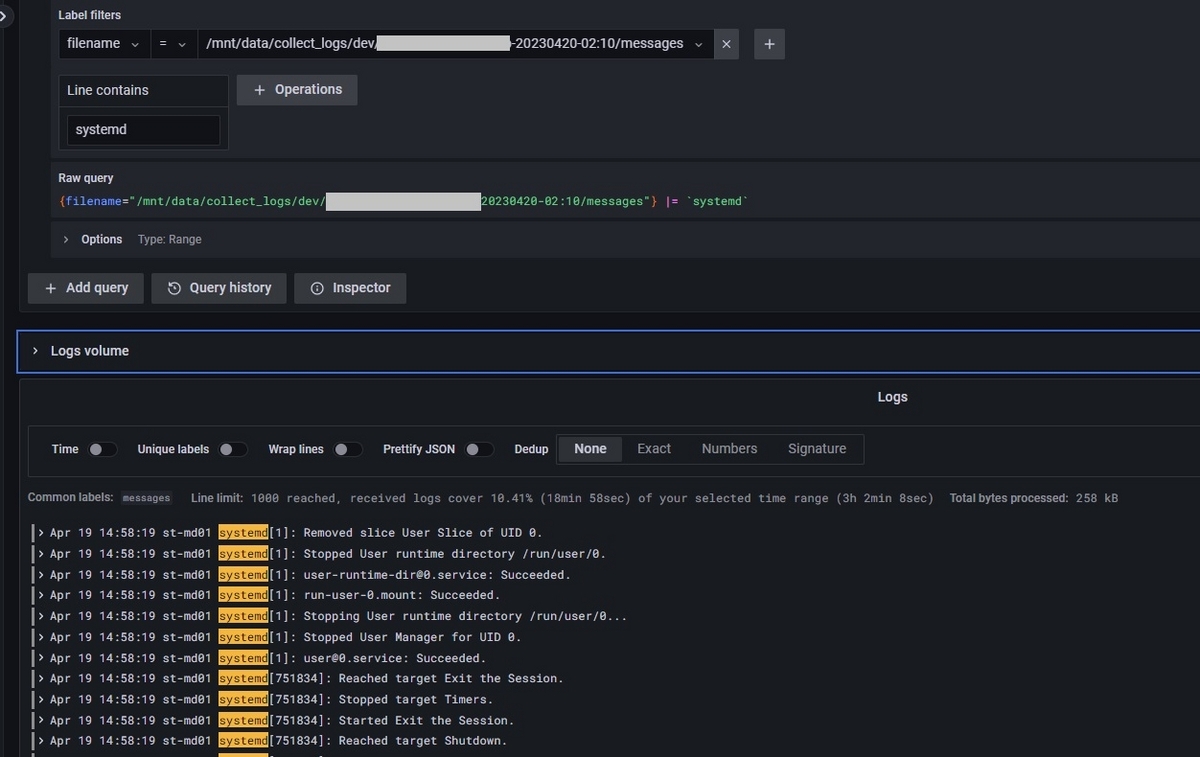
- さらに、対象期間の絞り込みや、キーワードによる対象ログの抽出も可能ですので、特定ログを調査したい場合に活用できます。
以下の例では、systemdのワードで抽出しています。
8.まとめ
使い勝手の良さを意識して、ブラウザ上での操作で完結する本番システムログの取得環境の構築に取り組み、なんとか思い描いた形に仕上げることができました。
これにより、従来の仕組みと比べてお手軽に使えるようになり、今まで一定の頻度で発生していた「インフラ部門へのログ提供依頼」の件数が少しでも減少することを期待しています。
そのためにも、少しでも見やすいマニュアルを作成して、他部門へ展開しています。
ただし、対象サーバが複数であったり、対象期間が1ヵ月を超えるようなケースにおいては、本システムを使っての取得はNGとしているので、まだ一定数以上の依頼は発生する想定です。
また、リリースしたばかりのシステムであるため、今後利用されていく中で様々な不具合や改修ポイントが見つかると考えており、より良い形になるよう今後もメンテナンスしていきたいと思います。
(実際、「あれ…」ってなる箇所を逐次発見しては改修している状況です。)
以上です。本記事が少しでもお役に立てれば嬉しいです。
