
はじめに
こんにちは!5月中旬から6月初旬までの3週間、ABEMAのService Growth Backendチームで「CA Tech JOB」のインターンシップ生として参加しました、北尾大河 (Linkedin, Github)です。出身は東京ですが、現在は大学3年生としてアメリカのカリフォルニア州にあるUniversity of California Berkeley (略称UCBerkeley or Cal)でComputer Scienceを勉強しています。
普段は、学校の授業で開発をするだけではなく、「Cal Hacks」というハッカソンに参加したり、学校のソフトウェアエンジニアリングクラブでチーム開発を行っています。ほかにも所属する学生団体「Plextech Consulting Club」では全学期、Zendeskなどの大企業から委託されたWeb開発業務をFull Stackのチームで行ったりしました。夏休みは東京に帰ってくることもあり、エンジニアのインターンシップを募集していた「CA Tech JOB」を見つけ、バックエンドエンジニアとして働けるかもしれないと応募しました。
インターンシップの目的と意気込み
私がCA Tech JOBに応募した理由は下記の3つです。
- Goを使った開発をしてみたい
- 大規模アーキテクチャ、マイクロサービスの仕組みを理解したい
- さまざまなエンジニアの人と話すことでエンジニアとしての視野を広げたい
特にABEMAのサーバーは、大規模リクエストの負荷に耐えられるほど凝った設計がされていたり、CI/CD周りが整っていたり、コード設計から大量のリクエストに耐えられるようなgRPCの実装やキャッシュ、データベース周りなど、知らないところで色々工夫されていてトレーナーの江頭さんに話を聞くだけでもすごく勉強になりました。
3週間の大まかなスケジュール
1週間目
- 手続きや開発の準備を行う
- 初日にFC町田ゼルビアというサイバーエージェントがオーナーを務めるサッカーチームの応援(かなりアブノーマルなスタートでした笑)
- 2日目にLinter合宿(個人的には山にキャンプしにいくのかと思ってました笑)
- 2つのミニタスク(足慣らし、特に初めて触るGoに慣れる目的)
- 月1の懇親会 + 自分の誕生日会
2週間目
- メイン業務であるドラゴンのタスク説明と設計
- Data Management Teamとのミーティング
- 実装を行って、deploy flowなどのCI/CD周りの確認やdeploy後の確認
- 成果発表(自分のタスク説明やチーム説明など)
- 毎日違うABEMAのチームの方々との懇親ランチ
3週間目
- タスクの実装の終了と動作確認
- ABEMAのアーキテクチャなど理解
- ブログの執筆
- 仕事後のサウナ+最後のお疲れ様会
これらに加えて、ABEMA内での大きなミーティングやService Growth Backendチームだけのチェックインミーティング、設計レビューミーティング、輪読会:『LeanとDevOpsの化学』、ABEMA月一締め回(コロナ以来初の対面での実施)などなど。あとは色々美味しい渋谷のランチ(とんかつ、ラーメン、焼肉、お寿司、定食屋、イタリアン…)に連れて行っていただきました。
Linter合宿
サイバーエージェントのオフィスは、アベマタワーズ以外に渋谷スクランブルスクエアにもあります。その一つのミーティングルームをチームで貸し切ってひたすら「個人の担当のパートのLinterエラーを直す」という一日合宿に参加しました。実際に、Goの実装におけるLinterエラーの処理の仕方を具体的に学ぶことができたので、Linterに叩かれないBest Code Practiceを学ぶことができました。実際のLinterエラーの種類は例として以下の通りです。
1. exhaustive: Handle cases where all possible branches are not covered. 2. paralleltest: Resolve resource conflicts (e.g., context, channels) in parallel tests. 3. thelper: Ensure proper usage of test helper functions. 4. nonamedreturns: Avoid using named return values. 5. gomnd: Replace magic numbers with constants. 6. gochecknoglobals: Reduce global variable usage. 7. ireturn: Ensure proper error handling and return values. 8. usestdlibvars: Replace custom implementations with standard library variables. 9. containedctx: Manage context properly in concurrent code. 10. revive: Address unused parameters and other code quality issues. 11. whitespace: Remove unnecessary spaces and line breaks. 12. errcheck: Check for unhandled errors. 13. gocritic: Improve code by following better practices or using newer standard library functions. 14. forbidigo: Avoid using forbidden functions or patterns in production code.
Mylist 500
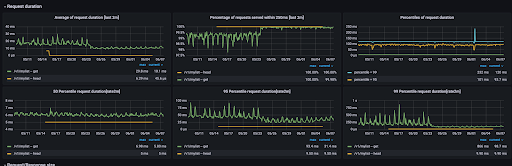
最初に与えられたタスクは、マイリスト機能の実装をGo Routineで並行処理化して書き換えるというものでした。リクエストが重く、500エラーが多く発生しタイムアウトしているためlatencyを改善することが目的でした。Cなどで並行処理の実装は書いたことがありましたが、Goでコードを書くのが初めてだったので、GoのSyntaxやGoroutinの構造・使用方法など理解するのに半日ほどかかりました。タスクが比較的シンプルなこともあり、表面的な理解だけで実装ができてしまったので、Effctive GoやGoのドキュメンテーションを読んでより深く理解したいと考えています。結果としては、400msほどかかっていたリクエスト時間が、1/4の100msまで減り、250ms以内に収まったリクエストの割合を99.9%に達成できたのでlatencyの改善に成功しました。
下記はGrafanaでrequest latencyを表したグラフ
以下、GoroutineでError Groupを使用したサンプルコードです。(*実際に書いたコードとは異なる)
func main() { rand.Seed(time.Now().UnixNano()) // Simulate a list of files to download files := []string{"file1.txt", "file2.txt", "file3.txt"} // Create a new error group ctx, cancel := context.WithCancel(context.Background()) eg, ctx := errgroup.WithContext(ctx) defer cancel() // Create a wait group for monitoring progress var wg sync.WaitGroup // Download and process each file concurrently for _, file := range files { file := file // Create a new variable to avoid data race eg.Go(func() error { wg.Add(1) defer wg.Done() err := downloadAndProcessFile(ctx, file) if err != nil { return fmt.Errorf("error downloading and processing %s: %w", file, err) } return nil }) } // Wait for all downloads and processing to complete if err := eg.Wait(); err != nil { fmt.Printf("Encountered an error: %v\n", err) } else { fmt.Println("All files downloaded and processed successfully") } // Wait for all progress monitoring to complete wg.Wait() fmt.Println("All done") }
Dragonのバンディットアルゴリズムの条件にシリーズ視聴未視聴の条件追加を行う
パッと聞いても「?」となるタスクだと思うのですが、私も最初はそんな感じでした。頭の中で、「そもそもDragonとは?」「バンディットアルゴリズムとは?」など混乱していたのを覚えています。DragonとはABEMAで使われている一つのレコメンドシステムのことで、その中でバンディットというアルゴリズムを使用しています。Dragonでは、広告配信のような仕組みで手動でコンテンツの配信設定を行うので、細かいターゲティングユーザーの属性や過去の行動情報に基づいて、計算量少なめで実行できます。例えば「この年代の男性で新規ユーザーの人にはこれを推薦したい」などです。
Dragonの仕組みとしては大きく下記の3つに分かれています。
- 候補生成
- 並び替え
- クリエイティブの最適化
ABEMA内で一列横に動画が並んでいるところがあるのですが、その部分をモジュールと読んでいて、そこに表示している広告用の画像やサムネなどをクリエイティブと呼んでいます。そのモジュールの中にまずはどのコンテンツを表示したいのかという候補生成を行い、絞り込みをした後に、どの順番で並べ替えるか決めて、最後にどのクリエイティブを表示するか決めるという流れになっています。
実際に私も知らなかったのですが、ABEMAではA/Bテストをしながらどのサムネイルや画像などがより視聴者の関心を得られるかどうかをCTR (Click Through Rate)という指標を元に計測しており、その指標でどのクリエイティブを表示するかどうか判断します。ここで、今のタスクの背景に結びつくのですが、そもそもなぜ「そのコンテンツのシリーズを今までに見たことがあるかないか」がレコマンドで関係するのか疑問に思う方もいるかもしれません。
例として挙げると、例えば「オオカミちゃんには騙されない」という作品を見たことがある人は、そのコンテンツに誰が出てくるか知っているので「〇〇と▲▲のキスの行方は」などのタイトルや画像だと「見てみたい!」と効果抜群な一方で、そのクリエイティブをシリーズ未視聴の人に表示してもパッとしないのは当たり前かと思います。このようにして、実際のデータを元にすると「シリーズ視聴/未視聴がレコメンドを大きく左右する要因になるということがデータチームの分析でわかった」というのがこのタスクの背景です。
Dragonにおけるバンディットアルゴリズム
バンディットアルゴリズムは、強化学習の一種であり、限られた情報を持つ環境で最適な行動を選択する問題を解決するために使用されます。複数の行動(または選択肢)の中から最も報酬を得る行動を見つけることを目的とし、ABEMAではクリック数や異なる視聴ジャンルのCTVR(CTR: Click Through Rate * CVR: Conversion Rate)に基づいて報酬を確定しています。バンディットアルゴリズムは、広告配信や資産管理などの領域で使用されることがあり、より複雑な問題に対しても応用され、強化学習の基礎として重要な役割を果たしています。
名前の由来であるスロットマシンは、複数のアーム(レバー)を持ち、各アームを引くとランダムに報酬が得られるというものです。バンディットアルゴリズムでは、各行動がスロットマシンのアームに対応し、目標は報酬を最大化する最適なアームを見つけることです。実際ABEMAではThompson Samplingを使用しており、探索と活用のバランスを異なる方法で調整することによって、最適な行動を選択するための戦略を提供します。初めは各アームを均等に試してみて、報酬の推定値を更新します。その後、報酬の推定値が高いアームをより頻繁に選択することで、探索と活用のバランスを取ります。探索では未知のアームを試すことで新たな情報を収集し、活用では報酬の高いアームを選ぶことで最適なアームを見つけます。
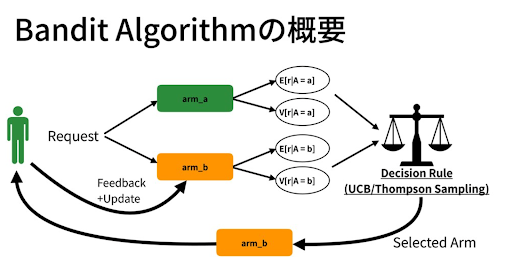
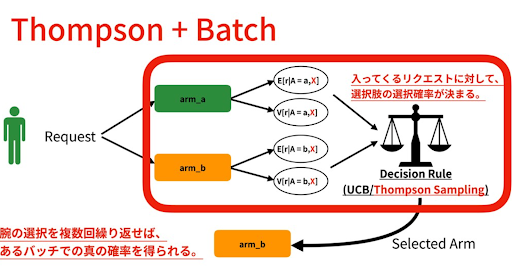
(引用 : https://speakerdeck.com/cyberagentdevelopers/bandit-algorithm-and-casual-inference)
設計、実装について
個人的には実装を行うことよりも、設計を行う方に苦労しました。User Statsというユーザーのデータを取り扱っているコンポーネントとUser Targetingというレコメンドの実装が書いてある2つのABEMAのコンポーネントはかなり大規模ということもあり、まずはそれぞれの設計を読み、コードを理解して、どの部分を修正、追加しなくてはならないかということを洗い出しました。思っていた5倍くらい変更しなくてはいけない実装がさまざまな場所に散らばっていて、自分でも抜けがないか心配になり、かなり設計の段階でどの場所にどのような実装をするか細かく記述したのを覚えています。私が触っていた箇所はレコメンド全体に影響を与える可能性のある大事な箇所だったので、そもそも長期的にみてこの実装で大丈夫かどうか、不具合を引き起こさないために変更した実装に相応のUnit Testを書けているかどうか、リーダブルなコードであるかどうかなど細かい部分まで指摘をいただき改善しました。
また、PRがアプルーブされてマージした後の動作確認の大切さにも気付かされました。エラーになってはいなくても、自分の期待通りの動作ができているか確認するのはかなり重要で、実際に新しく依頼して追加していただいたJsonのフィールドを読み込む段階で小さな対応漏れがあり、期待通りの動作になっていないことに気がつきました。また、短い期間の中、この実装を時間通りに完了できたのはData Managementチームのおかげもあり、「ユーザーが180日間の直近で視聴したシリーズIDを50格納できる仕組みを作って欲しい」というお願いをわずか1週間という短い間にも関わらず時間内に実装、本番まで反映させてくださって感謝しかないです。それぞれのユーザーが視聴した直近のシリーズIDが格納されているからこそ、バンディットアルゴリズムに特定のシリーズを視聴したことがあるかどうかという条件を追加する実装を行うことができました。実装の効果測定はこれからABEMAで検証が始まるところです。
3週間の個人的感想
この3週間で技術面で学んだこと、またチームマネージメントの面で学んだことが数えきれないほどあると思っています。そもそも、対面でこのように凝縮したインターンシップをした経験が今までなかったので、本当にいろんな人に支えられながらとても充実した成長環境にいられたことに感謝しかないと思っています。Clean Architecture、トランクベース開発での小規模マージ、Lambda ArchitectureやPubsub、PipeCDやGrafanaを通してDeploy後の確認、テストを書く上でのBest Practice、Goroutine、レコメンドについての知識などなど幅広いジャンルに触れることができました。毎日欠かさず書いていたログを振り返ってみてみると、普段聞いたことも触れたこともないアーキテクチャや技術など色々とインプットできていて、これからその一つ一つのトピックをまずは調べて、実装して、Youtubeで動画としてアップロードしてアウトプットするところまでやりたいなって考えています。

また、デスクに壁がないだけでなく、私のチームはコミュニケーション上の壁がなく本当に話しやすい印象がありました。30分単位で違う人たちとミーティングがびっしりと入っている江頭さんも、チームのサポートやいろんなタスクをいつも行っているボスの藤井さんも、隣でいつも困った時に支えてくれた重政さんも、嫌な目をせず丁寧に色々教えてくださって、馬鹿なところでミスをしていた時にdebugできたら笑いながら実装や設計のアドバイスを綿密にしてくださったりして、私が成長できたのはこういう暖かくクールなエンジニアの方々のおかげだと思っています。
あとは、個人的にService Growth Backendチームはどこか大学のスポーツチームなのかというくらい団結していて、それがミーティング時や自分の誕生日をお祝いしてもらってカラオケで盛り上がっているときに感じました。それぞれのサブチームによってチームの課題解決に取り組んでおり、品質アゲ太郎チーム、SLIチーム、DevOpsチーム、定期リリース・C I/CD改善チーム、KPT(Keep Problem Try : 組織改善)チームなどにわかれています。Win Sessionではそれぞれが達成したいゴールやOKRなどの設定や確認をしています。
また、「今週のありがとう」というチーム内のコンテンツがとても良いなと思いました。Slackで自分が感謝していることをお互いに伝えるのですが、これってすごく大事だと思っており、私もチームマネジメントをする立場になった時に一番大切にしたいです。単純にエンジニアとしてのチームだけでなく、感謝と尊敬を大切にした、人としてつながりの深いチームでありたいと思います。来学期アメリカでProject Managerとしてチームを率いる立場になった時に、江頭さんのような問題を明確に理解しそれを瞬時に改善できる鋭さ、藤井さんのように他の人をサポートできる応用力と余力を持ちながら、このBackendチームのように他人を支え合えながら高め合えるチームにしたいなと感じました。
この3週間、成長できる刺激的で楽しい環境で、私をチームの一員として受け入れてくれて「ありがとう」ということをスレッドにタイピングしてブログを終わりにしたいと思います!サイバーエージェントの人事の方々、ABEMAでランチなどで関わりを持った他のチームの方々、Service Growth Backendのメンバー、メンターの藤井さんとトレーナーの江頭さん、みなさん本当にありがとうございました。このブログで実際にABEMAやService Growth Backendチームでのインターンシップの様子が伝えられたら嬉しいです。また、海外大学出身のエンジニアがこれからサイバーエージェントにどんどん増えたら嬉しいなと思います。
CONCLUSION
Throughout the internship duration, I often found myself overwhelmed by the huge amount of resources and information available. However, observing other engineers in action had a profound impact on me. Not only has it heightened my motivation and work ethic, but it has also fostered a deep curiosity within me to continuously learn and explore new technologies. This internship has served as a powerful catalyst, further reinforcing my desire to broaden my perspective and venture into other fields as a backend engineer, all in the pursuit of personal growth. This journey is far from over; in fact, it has only just begun.
下記はFC町田ゼルビアのサッカー観戦の様子
