Amazon Web Services ブログ
Amazon EMR における高可用性キー配布センターの実装
このブログは Lorenzo Ripani (Big Data Solutions Architect) と Stefano Sandona (Analytics Specialist Solutions Architect) によって執筆された内容を日本語化したものです。原文はこちらを参照して下さい。
高可用性(HA)とは、指定された期間、故障することなく継続的に稼働するシステムまたはサービスの特性です。システム全体に HA 特性を実装することで、通常、サービスの中断につながる単一障害点を排除し、ビジネスの損失やサービスが使用不可能となることを回避します。
耐障害性と高可用性の核となる考え方は、定義の点では非常にシンプルです。通常、特定のサービスに対して冗長性を持たせるために複数のマシンを使用します。これにより、ホストがダウンしても他のマシンがトラフィックを引き継ぐことができるようになります。簡単に聞こえるかもしれませんが、特に分散テクノロジーを扱う場合、このような特性を得るのは容易ではありません。
Hadoop テクノロジーに焦点を当てると、使用しているフレームワークによって、複数のレイヤーで可用性について考える必要があります。耐障害性を持ったシステムを実現するには、次のレイヤーを考慮する必要があります。
- データレイヤー
- 処理レイヤー
- 認証レイヤー
最初の 2 つの層は、通常、Hadoop フレームワークのネイティブ機能( HDFS High Availability や ResourceManager High Availability など ) や、使用する特定のフレームワークで利用できる機能(例えば、読み取り処理の可用性を高めるための HBase テーブルレプリケーション を使用して処理されます。
認証レイヤーは、通常、Kerberos プロトコルの利用によって管理されます。Kerberos には複数の実装が存在しますが、Amazon EMR はマサチューセッツ工科大学(MIT)が直接提供する Kerberos プロトコルのフリーな実装を使用しており、MIT Kerberos とも呼ばれます。
キー配布センター (KDC) のネイティブ設定を見ると、ツールには典型的なプライマリ/セカンダリ構成が付属しており、プライマリ KDC に 1 つまたは複数のレプリカを追加して、可用性の高いシステムの構成が可能です。
しかし、この構成ではシステムが中断した場合に新しいプライマリ KDC を選出する自動フェイルオーバー機構は提供されていません。そのため、手動でフェイルオーバーを行うか、自動化されたプロセスを実装する必要がありますが、自動化のセットアップ作業は容易ではありません。
AWS のネイティブサービスを利用することで、MIT KDCの機能に対して、システムの障害に対する耐性をさらに高めることができます。
高可用な MIT KDC
Amazon EMR は、Kerberos 認証を有効にするための異なるアーキテクチャオプションを提供し、各々が特定のニーズやユースケースを解決できます。Kerberos 認証は、Amazon EMR セキュリティ設定を定義することによって有効にできます。セキュリティ設定は Amazon EMR 自身に保存される情報です。そのため、複数のクラスター間でこの構成を再利用することができます。
Amazon EMR のセキュリティ設定を作成する際、 クラスター専用の KDC か外部 KDC のどちらかを選択する必要があるため、それぞれのソリューションの利点と制限を理解することが重要です。
クラスター専用 KDC を有効にすると、Amazon EMR は起動するクラスターの EMR プライマリノード上に MIT KDC を構成してインストールします。一方、外部 KDC を使用する場合、起動したクラスターは外部の KDC に依存します。この場合、 KDC は外部 KDC として別の EMR クラスターのクラスター専用 KDC 、または Amazon Elastic Compute Cloud (Amazon EC2) インスタンスやコンテナにインストールされた KDC を使用できます。
クラスター専用 KDC は、 KDC サービスのインストールと設定をクラスター自体に委ねる、簡単な構成のオプションです。このオプションは、Kerberos システムに関する深い知識を必要としないため、テスト環境に適しています。また、クラスター内に専用の KDC を設置することで、Kerberos レルムを分離できるため、組織内の特定のチームまたは部門の認証にのみ使用できる専用の認証システムを提供できます。
ただし、KDC は EMR のプライマリノードに配置されているため、クラスターを削除すると KDC も削除されることを考慮する必要があります。また、KDC を他の EMR クラスター(セキュリティ設定で外部 KDC と定義したもの)と共有する場合を考慮すると、それらの認証レイヤーが侵害され、結果としてすべての Kerberos が有効なフレームワークが機能しなくなります。これはテスト環境では許容されるかもしれませんが、本番環境では推奨されません。
KDC の寿命は特定の EMR クラスターに縛られるとは限らないため、EC2 インスタンスや Docker コンテナに設置した外部 KDC を使用するのが一般的です。このパターンには、次のような利点があります。
- Active Directory を使用するかわりに、Kerberos KDC にてエンドユーザーの認証情報を保持することができます(ただし、クロスレルム認証を有効にすることもできます)。
- 複数の EMR クラスター間で通信を可能にし、すべてのクラスタープリンシパルが同じ Kerberos レルムに参加することで、すべてのクラスターで共通の認証システムを使用できます。
- EMR プライマリノードを削除することで他のシステムの認証に影響が出ないように、EMR プライマリノードの依存関係を削除できます。
- マルチマスターの EMR クラスターが必要な場合は、外部 KDC が必要です。
しかし、単一のインスタンスに MIT KDC をインストールしても、本番環境で重要な HA 要件には対応できません。次のセクションでは、認証システムの耐障害性を向上させるために、AWS のサービスを使用して可用性の高い MIT KDC を実装する方法について説明します。
アーキテクチャ概要
次の図に示すアーキテクチャは、AWS サービスを使用して、 複数のアベイラビリティゾーンに跨った高可用な MIT Kerberos KDC の構成です。ここでは 2 つのバージョンを提案します。 Amazon Elastic File System (Amazon EFS) ファイルシステムをベースにしたものと、Amazon FSx for NetApp ONTAP (FSx for ONTAP) ファイルシステムをベースにしたものです。
どちらのサービスも EC2 インスタンスにマウントし、ローカルパスとして使用することが可能です。Amazon EFS はFSx for ONTAP と比較して安価ですが、後者はミリ秒以下の操作レイテンシーを提供するため、パフォーマンス が向上します。
異なるファイルシステムを含むソリューションのベンチマークとして、複数のテストを実施しました。次のグラフは、Amazon EMR 5.36 の結果です。フレームワークとして Hadoop と Spark を選択し、クラスターが完全に立ち上がるまでの時間を秒単位で測定しました。

テスト結果を見ると、NFS プロトコルのロック操作のレイテンシによってもたらされるパフォーマンス低下は、クラスタートポロジーのノード数を増やすとクラスター起動の遅延が大きくなるため、Amazon EFS ファイルシステムは小規模クラスター(100 ノード未満)の処理に適していることがわかります。例えば、200 ノードのクラスターでは、Amazon EFS ファイルシステムによって生じる遅延により、一部のインスタンスは時間内にクラスターに参加できなくなります。その結果、クラスターに参加できないインスタンスは削除され、その後置き換えられるため、クラスター全体のプロビジョニングが遅くなります。これが、上のグラフでクラスターノードの数が 200 の場合の Amazon EFS のメトリックを公開していない理由です。
一方、FSx for ONTAP は、クラスターのプロビジョニング中に作成されるプリンシパルの数が増えても、Amazon EFS と比較してパフォーマンスの低下を抑えながら、より適切に処理できます。
FSx for ONTAP を用いたソリューションであっても、インスタンス数が多いクラスターでは、 Amazon EFS で前述したような挙動が発生する可能性があります。したがって、大きなクラスター構成の場合は、このソリューションを慎重にテストして評価する必要があります。
Amazon EFS を使用したソリューション
次の図は、Amazon EFS を使用したソリューションのアーキテクチャです。

インフラストラクチャは、KDC の耐障害性を向上させるために、さまざまなコンポーネントに依存しています。このアーキテクチャでは、次のサービスを使用しています。
- Kerberos サービスポート(認証用の port 88 と、プリンシパルの作成や削除などの管理タスク用の port 749)に対応するように構成された Network Load Balancer を使用しています。このコンポーネントの目的は、別々のアベイラビリティゾーンにある複数の KDC インスタンス間でリクエストのバランスをとることです。また、障害が発生した KDC インスタンスに接続する際のリダイレクトメカニズムを提供します。
- KDC の可用性を維持し、定義した条件に従って EC2 インスタンスを自動的に追加または削除できるようにする EC2 Auto Scaling group を使用しています。このシナリオでは、 KDC インスタンスの最小数を 2 台と定義します。
- Amazon EFS ファイルシステムは、 KDC データベースのための永続的で信頼性の高いストレージレイヤーを提供します。このサービスには HA プロパティが組み込まれているため、ネイティブ機能として永続的で信頼性の高いファイルシステムを利用できます。
- Kerberos の設定、具体的には Kadmin サービスに使用するパスワード、 KDC が管理する Kerberos ドメインとレルムを保存および取得するために AWS Secrets Manager を使用します。Secrets Manager を使用することで、 KDC インスタンスの起動時にスクリプトのパラメータやパスワードなどの機密情報を入力する必要がなくなります。
この構成では、単一インスタンスのインストールによるデメリットがなくなります。
- 失敗した接続は正常な KDC ホストにリダイレクトされるため、KDC が単一障害点であることはありません。
- 認証のための EMR プライマリノードに対する Kerberos トラフィックがなくなると、プライマリノードの状態が改善されます。これは、大規模な Hadoop (数百ノードの場合) のインストールでは重要になる場合があります。
- 障害が発生中も、存続しているインスタンスで管理業務と認証業務を処理しながら復旧することができます。
FSx for ONTAP を使用したソリューション
次の図は、 FSx for ONTAP を使用したソリューションのアーキテクチャです。
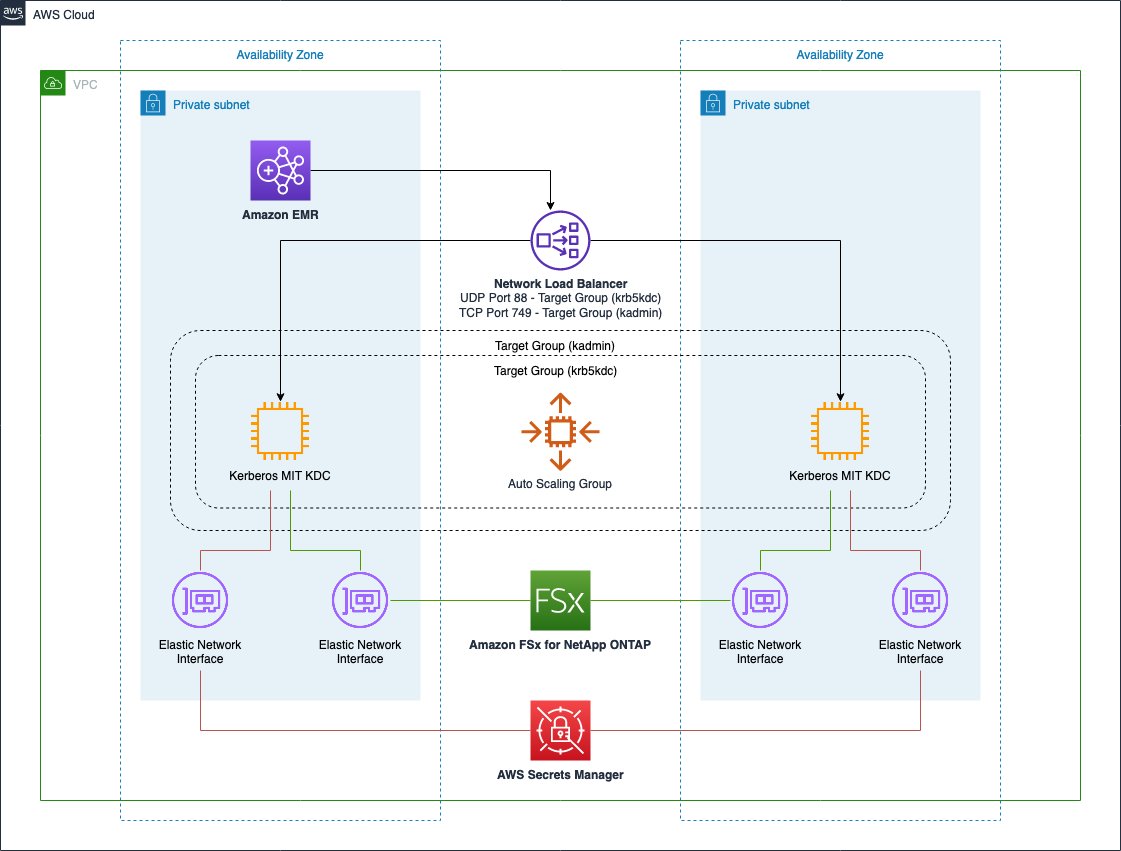
このインフラストラクチャは Amazon EFS の構成とほとんど同じ構成であり、同じメリットがあります。唯一の違いは、複数のアベイラビリティゾーンの FSx for ONTAP ファイルシステムを KDC データベースの永続的で信頼性の高いストレージレイヤーとして使用していることです。この場合でも、サービスには HA プロパティが組み込まれているため、そのネイティブ機能を活用して、永続的で信頼性の高いファイルシステムを実現できます。
ソリューションで使用するリソース
本記事では、一般的なガイドとして AWS CloudFormation のテンプレートを提供しています。必要に応じて見直し、カスタマイズする必要があります。また、このスタックによってデプロイされたリソースの中には、使用し続けるとコストが発生するものがあることに注意してください。
CloudFormation テンプレートには、複数のネストしたテンプレートが含まれています。次のものを作成します。
- KDC インスタンスをデプロイするための、2 つのパブリックと 2 つのプライベートサブネットを持つ Amazon VPC
- パブリックサブネットに接続するインターネットゲートウェイとプライベートサブネットに接続する NAT ゲートウェイ
- 各サブネットの Amazon Simple Storage Service(Amazon S3)ゲートウェイエンドポイントと Secrets Manager インターフェイスエンドポイント
VPC を含むリソースがデプロイされた後、KDC のネストされたテンプレートが起動され、次のコンポーネントをプロビジョニングします。
- 監視する特定の KDC ポート( Kerberos 認証用の port 88 と Kerberos 管理用の port 749 )用のリスナーにそれぞれ接続された 2 つのターゲットグループ。
- 異なるアベイラビリティゾーンに作成された KDC インスタンス間でリクエストのバランスをとるための Network Load Balancer 1 台。
- 選択したファイルシステムに応じて、複数のアベイラビリティゾーンに跨った Amazon EFS または FSx for ONTAP ファイルシステム。
- KDC インスタンスをプロビジョニングするための構成とオートスケーリング。具体的には、KDC インスタンスは、KDC のプリンシパルデータベースを格納するために使用されるローカルフォルダに選択したファイルシステムをマウントするように構成されます。
2 つ目のテンプレートが終了すると、外部 KDC が設定された、選択した場合にはマルチマスター構成で EMR クラスターが起動します。
CloudFormation スタックの起動
スタックを起動し、リソースをプロビジョニングするには、次の手順を実行します。
- Launch Stack を選択:

「Launch Stack」をクリックすると、お使いの AWS アカウント(サインイン済でない場合はサインインするように移行します)で AWS CloudFormation テンプレートが自動的に起動します。必要に応じて AWS CloudFormation コンソールでテンプレートを表示することができます。スタックが意図するリージョンで作成されることを確認してください。 CloudFormation スタックには、次のスクリーンショットに示すように、いくつかのパラメータが必要です。

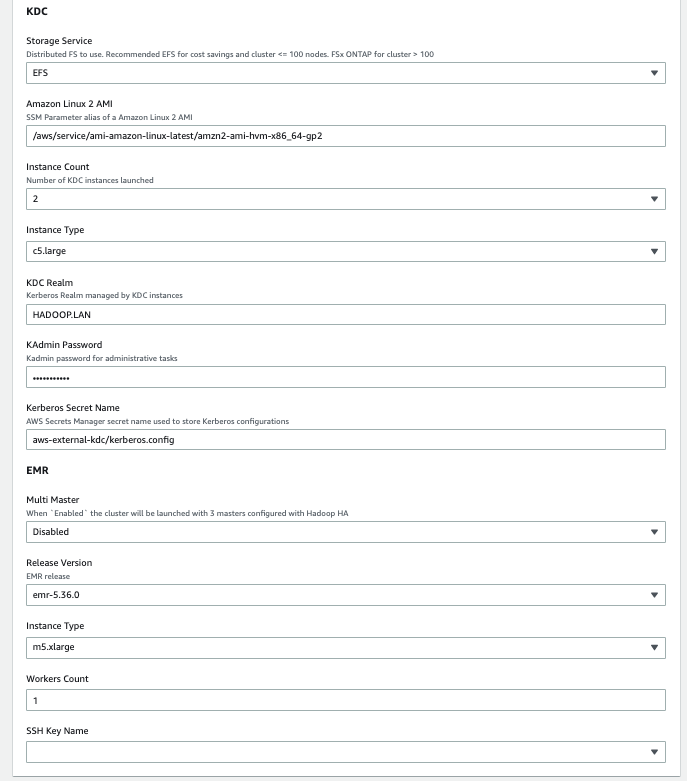
次の表は、スタックの各セクションで設定が必要なパラメータを記載しています。 - Core セクションでは, 次のパラメータを指定します。
パラメータ 値 (デフォルト) 説明 Project aws-external-kdc環境がデプロイされるプロジェクトの名前です。スタックで作成された各リソースに関連付けられた AWS タグを作成する際に使用されます。 Artifacts Repository aws-blogs-artifacts-public/artifacts/BDB-1689このスタックを起動するために必要なテンプレートとスクリプトをホストしている Amazon S3 のロケーションです。 - Networking セクションでは、次のパラメータを指定します。
パラメータ 値 (デフォルト) 説明 VPC Network 10.0.0.0/16 VPC のネットワーク範囲 (例:10.0.0.0/16) Public Subnet One 10.0.10.0/24 1 つ目のパブリックサブネットのネットワーク範囲 (例: 10.0.10.0/24) Public Subnet Two 10.0.11.0/24 2 つ目のパブリックサブネットのネットワーク範囲 (例: 10.0.11.0/24) Private Subnet One 10.0.1.0/24 1 つ目のプライベートサブネットのネットワーク範囲 (例: 10.0.1.0/24). Private Subnet Two 10.0.2.0/24 2 つ目のプライベートサブネットのネットワーク範囲 (例:10.0.2.0/24). Availability Zone One (ユーザー選択) 1 つ目のプライベートおよびパブリックサブネットを配置するためのアベイラビリティゾーン. Availability Zone Two パラメータの値とは異なる値となります。. Availability Zone Two (ユーザー選択) 2 つ目のプライベートおよびパブリックサブネットを配置するためのアベイラビリティゾーン. Availability Zone One パラメータの値とは異なる値となります。 - KDC セクションでは、次のパラメータを指定します。
パラメータ 値 (デフォルト) 説明 Storage Service Amazon EFS KDC で使用する共有ファイルシステムを指定します。Amazon EFS または FSx for ONTAP を指定します。 Amazon Linux 2 AMI /aws/service/ami-amazon-linux-latest/amzn2-ami-hvm-x86_64-gp2最新の Amazon Linux 2 AMI を取得するための AWS Systems Manager パラメータエイリアスを指定します。 Instance Count 2起動する KDC のインスタンスの数 Instance Type c5.largeKDC のインスタンスタイプ KDC Realm HADOOP.LAN外部 KDC サーバーによって管理される Kerberos レルム KAdmin Password Password123KDC で管理者操作を実行するためのパスワード Kerberos Secret Name aws-external-kdc/kerberos.configKerberos の設定を保存するために使用される Secrets Manager のシークレット名 - EMR では、次のパラメータを指定します。
パラメータ 値 (デフォルト) 説明 Multi Master Disabled 有効にすると、 Hadoop HA で構成された3つのプライマリでクラスターが起動します。 Release Version emr-5.36.0 Amazon EMR のリリースバージョン (Workers) Instance Type m5.xlarge クラスターのプロビジョニングに使用された EC2 インスタンスタイプ (Workers) Node Count 1 クラスターの起動中にプロビジョニングされた Amazon EMR CORE ノードの数 SSH Key Name (ユーザー選択) SSH リモートアクセスを提供するためにクラスターと KDC インスタンスに添付される有効な SSH PEM 鍵 - 次へを選択します。
- 必要に応じて AWS tags を追加します。 (このソリューションでは、すでにいくつかの定義済み AWS タグを使用しています)
- 次へを選択します。
- 最終要件を確認します。
- 送信を選択します。
テンプレートのネットワークセクションで、必ず異なるアベイラビリティゾーンを選択してください(Availability Zone One と Availability Zone Two)。これにより、アベイラビリティゾーン全体に障害が発生した場合の障害を防ぐことができます。
インフラストラクチャのテスト
インフラストラクチャ全体のプロビジョニングが完了後、HA 構成のテストと検証を行います。
本テストでは、KDC インスタンスの障害発生をシミュレートします。障害が起きた際に、残っている健全な KDC を使い続け、障害が発生した KDC の代わりに KDC インスタンスを追加することで、インフラストラクチャがどのように自己回復するのかを確認します。
CloudFormation スタックを起動し、2つの KDC インスタンスを指定し、KDC データベースのストレージレイヤーとして Amazon EFS を使用してテストを実施しました。EMR クラスターは、11 台の CORE ノードで立ち上げています。
インフラストラクチャ全体をデプロイした後、SSH 接続を使用して EMR プライマリノードに接続し、テストを実行することができます。

プライマリノード・インスタンスに接続後、テストのセットアップを進めます。
- まず、KDC データベース内に 10 個のプリンシパルを作成します。そのために、create_users.sh という bash スクリプトを下記の内容で作成します。
- 次のコマンドでスクリプトを実行します。
- 10 個のプリンシパルが KDC データベース内に正しく作成されたことを確認します。これを行うには、list_users.sh という別のスクリプトを作成し、前のスクリプトと同じように実行します。
スクリプトの出力には、クラスターノードがプロビジョニングされたときに作成されたプリンシパルと、作成したばかりのテストユーザーが表示されます。
ここで、複数の
kinitリクエストを並行して実行し、その間に、利用可能な 2 つの KDC インスタンスのうち 1 つでkrb5kdcプロセスを停止します。このテストは、
kinitリクエストの高い並列性を実現するために、Spark を使用して実行されます。 - 次に
user_kinit.shというスクリプトを作成します。 spark-shellを開き、—filesパラメータを使用して、前述の bash スクリプトをすべての Spark エグゼキューターに配布します。また、Spark の動的割り当てを無効にし、各々が 4 つの vCore を使用する 10 個のエクゼキューターでアプリケーションを起動します。- 次の Scala 文を実行して、分散テストを開始します。
この Spark アプリケーションは 1,600 個のタスクを作成し、各タスクは 10 個の
kinitリクエストを実行します。 これらのタスクは、一度に 40 個の Spark タスクのバッチで並列に実行されます。このコマンドの最終出力は、失敗したkinitリクエストの数を返します。

- ここでは、2 つの利用可能な KDC インスタンス に接続できます。このテンプレートでは、KDC インスタンスに SSH キーを提供していないため、AWS Systems Manager Session Manager を使用して、SSH キーなしで接続します。Amazon EC2 コンソールから AWS Systems Manager を使用して KDC インスタンスに接続するには、セッションの開始( Amazon EC2 コンソール)を参照してください。
- 1 つ目の KDC にて、次のコマンドを実行して、受信した kinit 認証リクエストを表示します。
出力例は次のスクリーンショットの通りです。

- 2 つ目の KDC にて、次のコマンドを実行し、障害をシミュレートします。
- Amazon EC2 のコンソールに接続し、KDC に関連するターゲットグループを開くと、インスタンスの状態が Unhealthy になり( 3 回連続でヘルスチェックが失敗した後)、その後削除されて新しいインスタンスに置き換えられたことが確認できます。
ターゲットグループは、サービスに障害が発生した際に以下の手順を実行します。- KDC インスタンスが Unhealthy の状態となる。
- Unhealthy となった KDC インスタンスをターゲットグループから登録解除する。(ドレイン処理)
- 新しい KDC インスタンスを起動する。
- 新しい KDC インスタンスをターゲットグループに登録し、ロードバランサーからのトラフィックを受信できるようにする。
KDC インスタンスに障害が発生している間、次のスクリーンショットのような出力が表示されることが予想されます。

- 置き換えられた KDC インスタンスに接続すると、
krbr5kdcログにトラフィックが表示され始めるのが確認できます。


テストの最後には、失敗した Kerberos 認証の総数が表示されます。
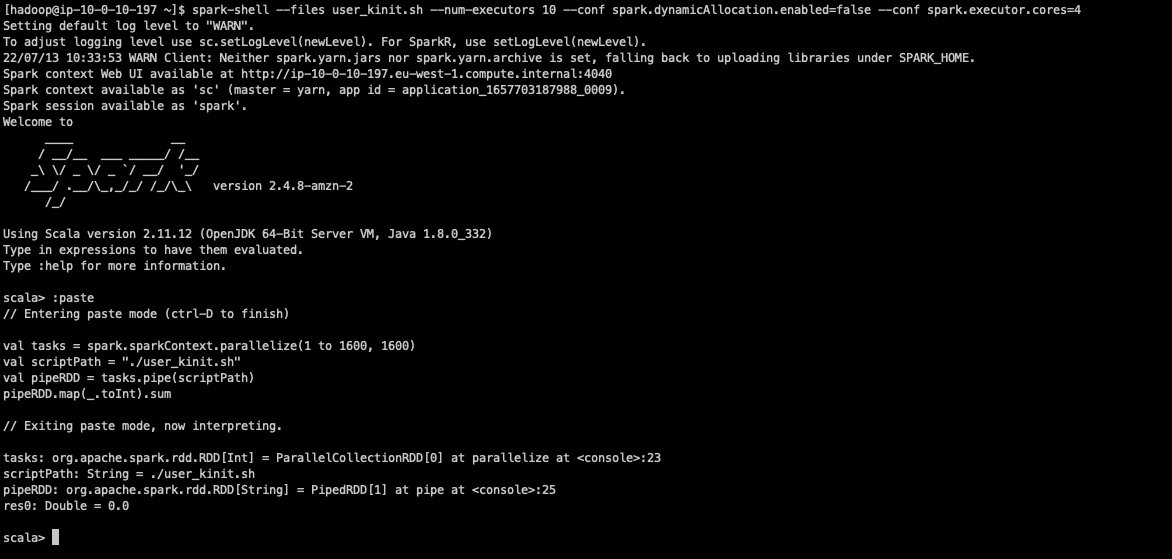
出力結果より、このテストでは認証の失敗がありませんでした。しかし、このテストを何度も繰り返すと、いくつかのリクエストの認証中に krbr5kdc のプロセスが停止してしまい、エラー(平均 1 ~ 2 個)が発生する可能性があります。.
kinit ツール自体にリトライの仕組みがないことに注意してください。クラスター上で実行される Hadoop サービスと、 EMR インスタンスのプロビジョニング中に行われる Kerberos プリンシパルの作成は、いずれも KDC 呼び出しに失敗した場合にリトライするように設定されています。
これらのテストを自動化したい場合、AWS Fault Injection Simulator の利用をご検討ください。これは AWS 上でフォールトインジェクション実験を行うためのフルマネージドサービスで、アプリケーションのパフォーマンス、オブザービリティ、レジリエンシーを容易に向上させることができます。
クリーンアップ
すべてのリソースをクリーンアップするために、次の手順を行ってください。
- AWS CloudFormation のルートスタックの削除。
- 削除の開始からしばらくすると、失敗が表示されます。
- VPC のネストしたCloudFormationスタックをクリックし、Resources を選択します。VPC リソースに対して、
DELETE_FAILEDエントリが表示されています。これは、EMR が自動的に Default Security Groups を作成し、それらが CloudFormation による VPC の削除を妨げていることが原因です。 - AWS コンソールの VPC セクションに移動し、その VPC を手動で削除します。
- CloudFormation に戻り、ルートスタックを再度選択し、Delete を選択します。今度は削除が完了します。
ファイルシステムのバックアップ
Amazon EFS と FSx for ONTAP は AWS Backup にネイティブに統合されています。
AWS Backup は、バックアップの自動化と一元管理を支援します。ポリシー駆動型のプランを作成した後、進行中のバックアップのステータスの監視、コンプライアンスの検証、バックアップの検索と復元をすべてマネジメントコンソールから行うことができます。
詳細については、 「AWS Backup を使用して、Amazon EFS ファイルシステムのバックアップおよび復元するには」 および、 「Amazon FSx で AWS Backup を使用する」 を参照してください。
その他考慮事項
本セクションでは、このソリューションを使用する際の考慮事項を説明します。
共有ファイルシステムのレイテンシーが与える影響
共有ファイルシステムの利用は、多くの場合パフォーマンスの低下に繋がります。特に、同時に作成しなければならない Kerberos プリンシパルが多ければ多いほど、プリンシパル作成プロセスとクラスター起動時間にレイテンシーが発生することがわかります。
この性能低下は、同時に行われる並列 KDC リクエストの数に比例します。たとえば、同じ KDC に接続された 20 ノードを持つ 10 個のクラスターを起動しなければならないシナリオを考えてみます。10 個のクラスターを同時に立ち上げると、フレームワークに関連する Kerberos プリンシパルを作成するための最初のインスタンスプロビジョニング中に、KDC へ 10 × 20 = 200 の並列接続が発生する可能性があります。さらに、サービス用の Kerberos チケットの持続時間はデフォルトで 10 時間であり、すべてのクラスターサービスがほぼ同時に起動されるため、サービスチケットの更新にも同じレベルの並列性が発生する可能性があります。一方、この 10 個のクラスターを時間差で起動すると、並列接続が20個で収まる可能性があります。その結果、共有ファイルシステムによって生じるレイテンシーはそれほどパフォーマンスに影響しません。
本記事にて先述したように、複数クラスターでは関連する KDC 間でクロスレルム認証を設定することなく、互いに通信する必要がある場合に同じ KDC を共有することができます。複数のクラスターを同じ KDC にアタッチする前に、その必要性が本当にあるかどうかを評価する必要があります。なぜなら、より良いパフォーマンスを実現し、問題が発生した場合の影響範囲を小さくするために、Kerberos レルムを異なる KDC インスタンスに分離することも検討できるからです。
まとめ
ダウンタイムが許されない EMR クラスターにとって、高可用性と耐障害性は重要な要件です。これらのクラスター内で実行される分析ワークロードは、機密データを扱う可能性があるため、安全な環境での運用が不可欠です。そのため、安全で可用性が高く、耐障害性の高いセットアップが必要です。
本記事では、Amazon EMR のビッグデータワークロードの認証レイヤーの高可用性と耐障害性を持たせるひとつの実現方法を紹介しました。AWS のネイティブサービスを使用することで、複数の Kerberos KDC を並行して動作させ、障害が発生した場合に自動的にインスタンスを交換する方法を示しました。これとフレームワーク固有の高可用性および耐障害性を組み合わせることで、安全で高可用性かつ耐障害性を持った環境で運用することができます。
翻訳はネットアップ合同会社の岩井様、監修はテクニカルアカウントマネージャーの有田が担当しました。
著者について
 Lorenzo Ripani は、AWS の Big Data Solution Architect です。分散システム、オープンソース技術、セキュリティに特化しています。世界中の顧客に対して、Amazon EMR を使ったスケーラブルで安全なデータパイプラインの設計、評価、最適化を提供しています。
Lorenzo Ripani は、AWS の Big Data Solution Architect です。分散システム、オープンソース技術、セキュリティに特化しています。世界中の顧客に対して、Amazon EMR を使ったスケーラブルで安全なデータパイプラインの設計、評価、最適化を提供しています。
 Stefano Sandona は、AWS の Analytics Specialist Solution Architect です。データ、分散システム、セキュリティに特化しているエンジニアです。世界中の顧客のデータプラットフォームのアーキテクトを支援しています。Amazon EMR とその周辺のセキュリティに強い関心を持っています。
Stefano Sandona は、AWS の Analytics Specialist Solution Architect です。データ、分散システム、セキュリティに特化しているエンジニアです。世界中の顧客のデータプラットフォームのアーキテクトを支援しています。Amazon EMR とその周辺のセキュリティに強い関心を持っています。