
概要
GOODROIDでリードエンジニアをさせて頂いています及川です。
弊社ではマスタデータなどの一部のデータをローカルDBに保存しています。
ここ数年で開発規模が増加し、それに伴って課題解決の形でローカルデータ基盤を一新する機会がありました。
一新した結果、既存基盤で発生した課題を解決すると共に、高頻度シナリオでは最大1200%、ニッチなケースも含めると最大6300%の性能向上を達成する事ができました。
本記事では、ローカルDBを扱う上で発生した課題と、それをどうやって解決したのかを紹介していきます。
前提知識
新規基盤を話題に挙げる前の前提知識として、2点上げさせてください。
ローカルデータ基盤とはどこの話なのか
本記事で扱うローカルデータ基盤は、sqliteをバックエンドとしたデータ提供基盤です。
DBやSQL等のインフラレイヤを隠蔽しつつ、プロジェクトコードにMaster/Playerデータアクセスと必要なデータの永続化を提供します。

既存のローカルデータ基盤について
ローカルデータの背景
そもそもなぜローカルでデータを持っているかという話からですが、ビジネス的な選択の結果になります。
弊社は過去にエンジニア/デザイナ/プランナー各一人ずつのような少人数かつ高速でアプリを開発を行っており、最小で1月単位での開発/リリースを行っていました。
ここ数年は大型化が進み高リスクなデータがサーバに移行されましたが、
一部のデータは少人数開発時の経験を生かした開発速度やコストの観点からローカルでのデータ保持が選択されています。
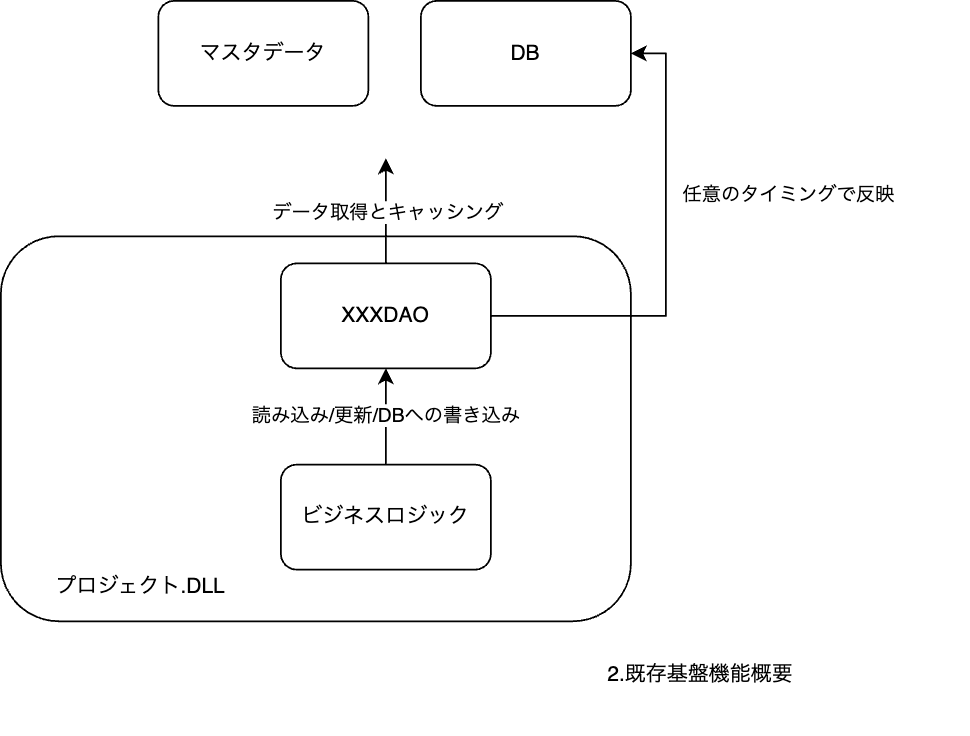
基盤機能
機能はDAOとして集約されています。
Master/Playerデータともに読み込み機能を。
Playerデータに対してのみ書き込み機能を提供しています。
データを定義すると、
public class PlayerInfoDTO
{
public int Id;
public string AppVersion;
}
Google Apps Script上でDAOのコードが生成され、プロジェクトコード上で下記の様なデータアクセスが提供されます。
void Test()
{
var dao = new PlayerInfoDAO();
//DBデータのキャッシュ化
dao.LoadRecords();
var info = dao.Cache.First();
Debug.Log($"AppVersion: {info.AppVersion}");
//キャッシュデータをDB反映
dao.SaveAll();
}
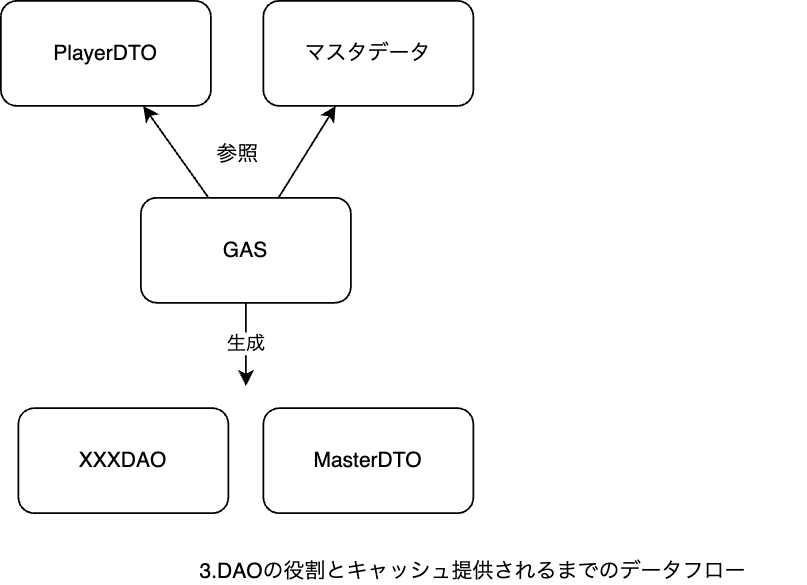
プロジェクトで使う場合全てのDAOをstatic上に保持するクラスが導入され、Master/Player両データ共に全てのデータをC#上のキャッシュに乗せて提供しています。
全てのデータをキャッシュ上に乗せるのはパフォーマンス/セキュリティ上のデメリットがあるのですが、開発速度とのトレードオフとして許容しています。*1
提供されたC#上のキャッシュに対してプロジェクト側でアクセスすることでSQLやDBなどの、データのインフラを意識意識せず開発が行えるようにする役割を担っています。
新規基盤の概要
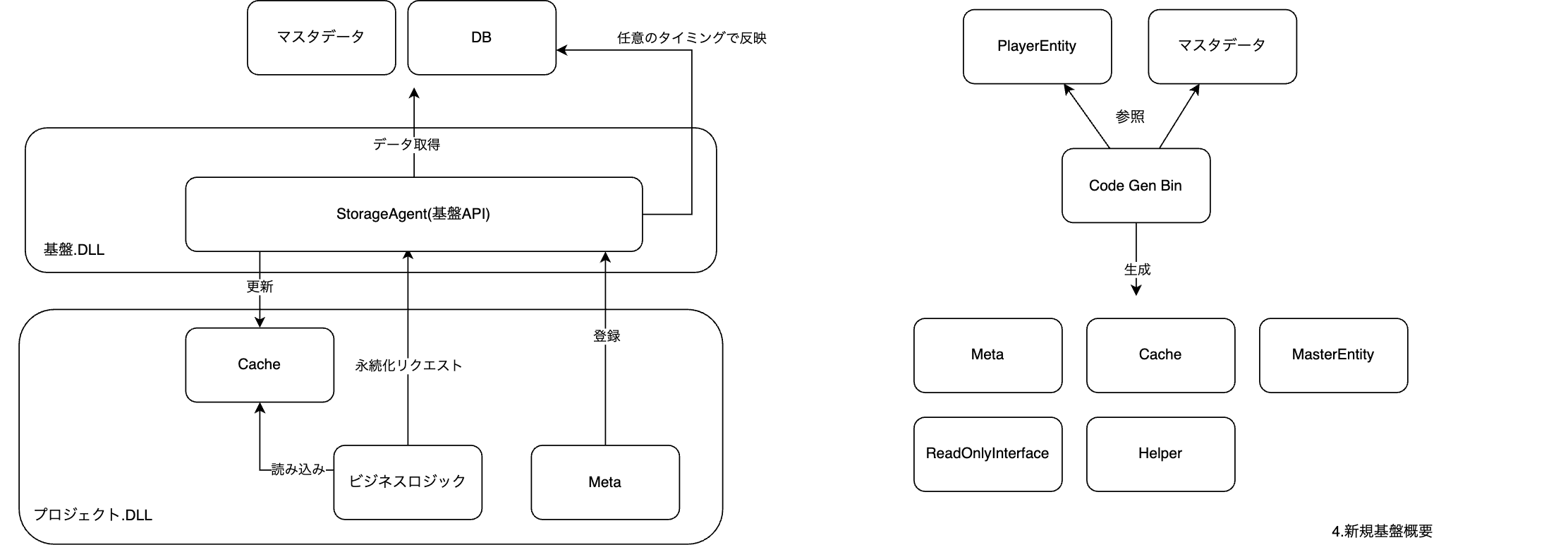
新しい基盤はStorageという名称です。
基盤利用の開発体験を大きく変えたくなかったので、Entityを定義することでキャッシュ等のコードを生成、インフラを隠蔽するフローは踏襲しています。
詳しくは後述しますが、プロジェクトコードと切り離して専用のAPIを叩いてもらう形になっています。
//プロジェクト定義
[Table("player_info", isSingle:true)]
public class PlayerInfo : ITableEntity,IPlayerInfo
{
[Column("id", "INTEGER", "PRIMARY KEY NOT NULL", "1")]
public int PrimaryIndex { get; set; }
[Column("app_version", "TEXT", "NOT NULL", "0")]
public string AppVersion { get; set; }
}
//自動生成
class PlayerCache
{
public PlayerInfo PlayerInfo { get; set; }
public void LoadAll()
{
//全てのEntityをキャッシュのせる
}
}
//ユースケースイメージ
void Test()
{
var cache = new PlayerCache();
StorageAgent.Instance.Setup(cache);
//DBデータのキャッシュ化
cache.LoadAll();
var info = cache.PlayerInfo;
Debug.Log($"AppVersion: {info.AppVersion}");
//キャッシュデータをDB反映(内部でキャッシュにも反映)
StorageAgent.Instance.SaveEntity(cache.PlayerInfo);
}
大きな変更点としては2つです。
DAO/キャッシュの責任分割、細分化
既存の基盤ではDAOが内部にキャッシュを持ち、ビジネスロジックはそのキャッシュに対して読み込みや更新処理を行っていました。
DAO -> 自動生成、各クラスのインフラ構造とデータアクセスロジック、キャッシュ、その更新責任を持つ
新しい基盤では、それらの責任をそれぞれ独立化し整理しています。
Cache -> 自動生成、キャッシュのinstanceを提供
Meta -> 自動生成、各クラスのインフラ構造を提供
基盤API -> データアクセスロジック、キャッシュの更新を提供
DAOが持つ多くの責任を分散することで、生成コードの複雑性を上げる下地を作成しています。
生成コードの責任増加
既存の基盤実装だと、SQL作成に必要な情報を提供するコードを生成していました。
生成したコードでは、インフラ情報を下記のような形で保持していました。
//手動定義
public class PlayerInfoDTO
{
public int Id;
public string AppVersion;
}
//自動生成
public class PlayerInfoDAO
{
protected List<string> _nameList = new List<string>();
protected List<string> _attrList = new List<string>();
protected List<string> _defaultList = new List<string>();
protected void SetColumn(string name, string attr, string defaultVal)
{
_nameList.Add(name);
_attrList.Add(attr);
_defaultList.Add(defaultVal);
}
public override void SetAllColumn()
{
SetColumn("id", AttrType.PrimaryKey, "1");
SetColumn("app_version", AttrType.Text, "'0.0.0'");
}
public PlayerInfoDTO Row2DTO(Dictionary<string, object> row)
{
var dto = base.Row2DTO(row);
dto.Id = row.TryGetValue("id", out object id)? (int)id : 1;
dto.AppVersion = row.TryGetValue("app_version", out object appVersion)? (string)appVersion : "0";
return dto;
}
}
このコードを元に保存用のSQLの生成やキャッシュの作成を行っていました。
新基盤では、データ構造だけでなくデータアクセスのロジックやSQL自体をある程度事前に作成するようにしています。
//手動定義
[Table("player_info", true, true)]
public class PlayerInfo : ITableEntity,IPlayerInfo
{
[Column("id", "INTEGER", "PRIMARY KEY NOT NULL", "1")]
public int PrimaryIndex { get; set; }
[Column("app_version", "TEXT", "NOT NULL", "0")]
public string AppVersion { get; set; }
}
public sealed class PlayerInfotMeta
{
public string SelectSQL => $"テーブル内カラムをすべて取得するクエリ";
public string SelectSQLFirst => $"テーブル内カラムの先頭を取得するクエリ";
public string TableInfoSQL => $"pragmaでテーブル情報を取得するクエリ";
public string CreateTableSQL => $"テーブル作成するクエリ";
public string DeleteAllRowSQL => $"すべてのカラムを削除するクエリ";
//一部抜粋、他にはLong/Double/String/Bool用のロジックが生成されます
public int GetIndexIntMember(ITableEntity entity, int index)
{
var casted = entity as PlayerInfotMeta;
switch (index)
{
case 0:
return casted.PrimaryIndex;
}
return default;
}
public void SetIndexIntMember(ITableEntity entity, int index, int value)
{
var casted = entity as PlayerInfotMeta;
switch (index)
{
case 0:
casted.PrimaryIndex = (int)value;
return;
}
}
}
これらの変更により、後述する課題解決が実現しました。
新規基盤による課題解決
基盤刷新にあたり、既存の基盤で発生していた課題を解決することを目標にしました。
データ読み込み時のアロケーション
課題
Player/Masterの全データのキャッシュを作成するため、データが増えた場合このキャッシュ作成がUXに影響を与える可能性が課題感としてありました。
そこでデータ読み込みのフローを見直し、多くのアロケーションが発生している箇所を修正することにしました。
アロケーションが多く発生していたのは、中間データで使用しているレコード表現のDictionary<string,object>に値を入れる箇所でした。

既存基盤では、Entityを作成するためsqliteのプラグインから返却されたデータを中間データとして以下のように定義していました。(抜粋)
class DataRow : Dictionary<string, object>
{
}
class DataTable
{
public List Rows { get; set; }
}
このDataTableはDAOに渡されDTOの作成に使用されます。
public PlayerInfoDTO Row2DTO(DataRow row)
{
var dto = new PlayerInfoDTO();
dto.Id = row.TryGetValue("id", out object id)? (int)id : 1;
dto.AppVersion = row.TryGetValue("app_version", out object appVersion)? (string)appVersion : "0";
return dto;
}
既存基盤ではsqliteから受け取れるデータとしてint/float/stringを定義しており、*2
string以外のデータはこの中間データ作成の際にobject型に変換されることでboxingが起きていました。
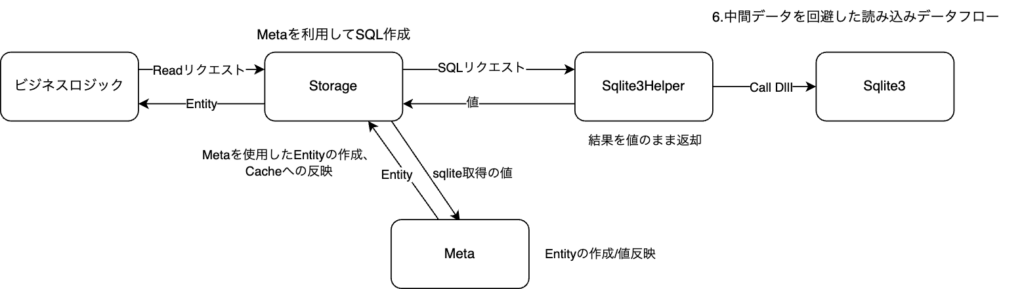
新基盤での対応
値型のデータの取得にobject型の中間データを挟んでいることが原因なので、この中間データを無くすことで回避しました。
Entityに各型用のインターフェースを基盤側で用意し、プロジェクト側でこのインターフェースを実装してもらう方針です。
// 基盤側定義
public interface ITableEntity
{
int PrimaryIndex { get; set; }
}
public interface ITableEntityMeta
{
// int用
int GetIndexIntMember(ITableEntity entity,int index);
void SetIndexIntMember(ITableEntity entity,int index, int value);
// long用など他の型用のインターフェースが続きます
}
// プロジェクト側定義
[Table("player_test")]
public class TableEntity : ITableEntity
{
[Column("id")]
int PrimaryIndex { get; set; }
[Column("int_data")]
int IntData { get; set; }
}
//自動生成
public class TableEntityMeta : ITableEntityMeta
{
//Columnの定義順に変数を返すgetter
int GetIndexIntMember(ITableEntity entity,int index)
{
var casted = entity as PlayerAccount;
switch (index)
{
case 0:
return casted.PrimaryIndex;
case 1:
return casted.IntData;
}
return default;
}
//Columnの定義順に変数を更新するsetter
void SetIndexIntMember(ITableEntity entity,int index, int value)
{
var casted = entity as PlayerAccount;
switch (index)
{
case 0:
casted.PrimaryIndex = value;
case 1:
casted.IntData = value;
}
}
}
// 基盤側の値更新イメージ
void UpdateEntityValue(System.IntPtr pState,ITableEntity entity,ITableEntityMeta meta)
{
for (int columnIndex = 0; columnIndex < columnCount; columnIndex++)
{
var attribute = meta.ColumnAttributes[columnIndex];
switch(attribute.DataType)
{
case "int":
var intValue = SQLiteHelper.ColumnInt(pState,columnIndex);
meta.SetIndexIntMember(entity,columnIndex,intValue);
break;
//他の型のデータ
}
}
}
今まで基盤側でEntityにデータを注入するためobjectで扱うしかありませんでした。
具体的な値を扱うインターフェースがプロジェクトコードとして自動実装されることで、
基盤側のEntityへのデータ注入責任をプロジェクト側に移譲しobject型の中間キャッシュを回避することが出来ました。
既存基盤よりも複雑性がかなり増したため、自動生成ツールを基盤機能の一部として開発して対応しています。
このツールはコード生成後にRoslynでコンパイルを行うことでプロジェクト導入後にコンパイルが失敗しないコードを作成する機能があり、PlayerデータのMeta、マスタデータのEntityとMeta、初期化用のHelperやCacheのコードが生成されています。
また、Entity提供のユースケースとして読み込みしかできないEntityの需要もありました。
//プロジェクト定義
[Table("player_info", true, true)]
public class PlayerInfo : ITableEntity,IPlayerInfo
{
[Column("id", "INTEGER", "PRIMARY KEY NOT NULL", "1")]
public int PrimaryIndex { get; set; }
[Column("app_version", "TEXT", "NOT NULL", "0")]
public string AppVersion { get; set; }
}
void Test()
{
var cache = new PlayerCache();
StorageAgent.Instance.Setup(cache);
//DBデータのキャッシュ化
cache.LoadAll();
var info = cache.PlayerInfo;
Debug.Log($"AppVersion: {info.AppVersion}");
//Entityは扱いたいが、変更されると困る
info.AppVersion = "???";
}
そのためリードオンリーなEntityを提供するコードも生成されています。
//自動生成
public interface IPlayerInfo
{
int PrimaryIndex { get;}
string AppVersion { get;}
}
//自動生成
public class ReadonlyPlayerCache
{
private readonly PlayerCache _cacheSource;
public ReadonlyPlayerCache(PlayerCache cacheSource)
{
_cacheSource = cacheSource;
}
public IPlayerInfo PlayerInfo => _cacheSource.PlayerInfo;
}
void Test()
{
var cache = new PlayerCache();
var readOnlyCache = new ReadonlyPlayerCache(cache);
StorageAgent.Instance.Setup(cache);
//DBデータのキャッシュ化
cache.LoadAll();
var info = readOnlyCache.PlayerInfo;
Debug.Log($"AppVersion: {info.AppVersion}");
//セッター不要なケースならリードオンリーなinterfaceに切り替えて使用できる
info.AppVersion = "???";//error
}
リードオンリーなEntityアクセスの手段が提供され、変更されたくないEntityの表現が容易に行えるようになりました。
余談 : 自動生成ならではの最適化
List<TableEntity>のリクエストがあった場合、基盤内ではList<ITableEntity>として扱うため、必要に応じて相互変換が必要です。
OfType<TableEntity>やCast<TEntity>を使用する場合、別のListインスタンスが必要になるケースがあり、不要なアロケーションが走ってしまいます。
そこで自動生成ならではの最適化として、List同士のUnsafeなキャストを行っています。
処理のフローイメージは以下になります
//自動生成
public class TableEntityMeta : ITableEntityMeta
{
public List<ITableEntity> CreateEmpties(int length)
{
var result = new List(length);
for (int i = 0; i < length; i++)
{
result.Add(new TEntity());
}
return Unsafe.As<List<TEntity>,List<ITableEntity>>(ref result);
}
}
//基盤実装
List<TEntity> LoadEntityies() where TEntity : class, ITableEntity
{
// metaHolerへのMeta/Entityのひもずけを行う初期化コードも自動生成されます
var meta = metaHolder[typeof(TEntity)];
var resultCount = SqliteHelper.クエリ結果のデータ行数取得();
// 自動生成コードでリクエストにきた派生先のEntityを作成する
List<ITableEntity> result = meta.CreateEmpties(resultCount);
// 自動生成コードなので必ず一致する
return Unsafe.As<List<ITableEntity>, List<TEntity>>(ref entities);
}
新基盤では、MetaとEntityを紐付けて登録するHelperコードも含めて自動生成しています。
人が書いたコードであればList<ITableEntity>の実態がTEntityでリクエストされた型あることは限らないためOfTypeやCastで安全に扱う必要がありますが、自動生成コードの場合ヒューマンエラーは基本無いため自動生成ならではの最適化が行えています。
テーブル内データ量
課題
EntityのキャッシュをC#常に載せてLinqなどで走査を行う都合上、レコード量の多いテーブルが発生するとパフォーマンスへの影響が大きいという課題感がありました。
これはPlayer/Master両方のデータで起きており、同じインターフェースでの解決が必要でした。
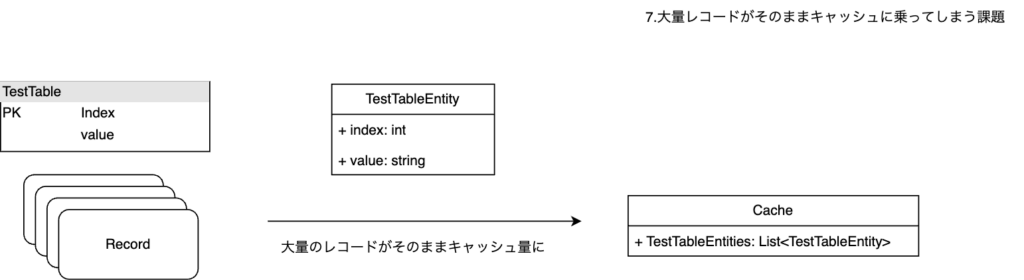
新基盤での対応
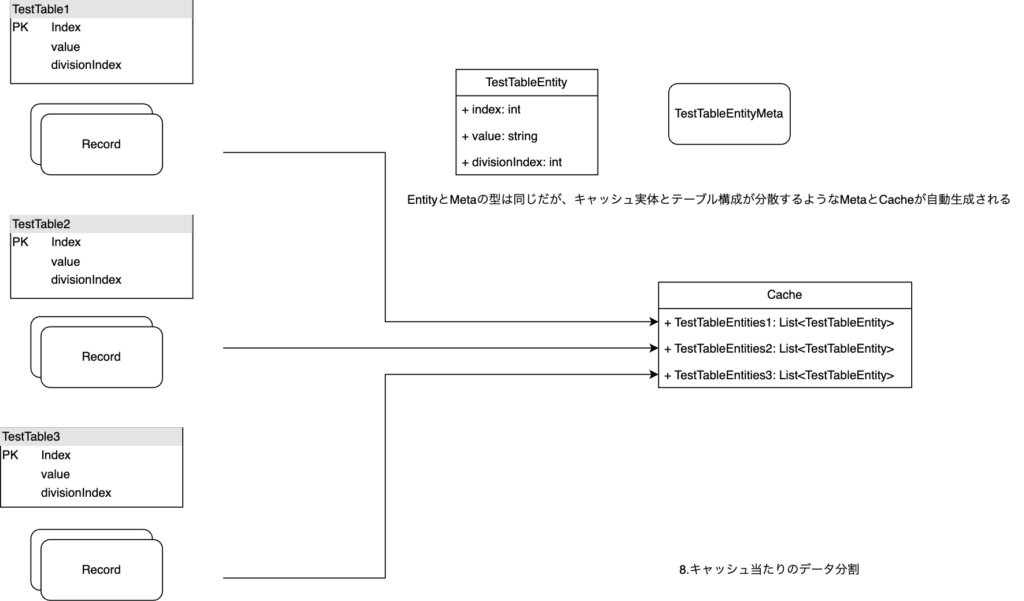
Entityに対して水平分割を提供する事で対応しています。
具体的には、コード上のEntietyと実体のテーブルの関係が1対多にできる機能を実装しました。
ユーザーはentitiyに分割数を追加で指定する事で分割idを指定してデータを操作するmetaが自動生成されます。
//基盤定義
public interface IHorizontallyDivideTableEntity
{
int DivisionIndex { get; set; }
}
// プロジェクト定義
[Table("horizontally_table", divisionCount:3)]
public class PlayerTestDiv : IPersistentEntity,IHorizontallyDivideTableEntity
{
[Column("id", "INTEGER", "PRIMARY KEY NOT NULL", "1")]
public int PrimaryIndex { get; set; }
[Column("divisionIndex", "INTEGER", "NOT NULL", "0")]
public int DivisionIndex { get; set; }
[Column("content_id", "TEXT", "NOT NULL", "0")]
public string ContentId { get; set; }
}
var playerDivideEntity1 = new PlayerTestDiv { PrimaryIndex = 1, DivisionIndex = 1, ContentId = 100 };
var playerDivideEntity2 = new PlayerTestDiv { PrimaryIndex = 1, DivisionIndex = 2, ContentId = 200 };
var playerDivideEntity3 = new PlayerTestDiv { PrimaryIndex = 1, DivisionIndex = 3, ContentId = 300 };
StorageAgent.Instance.SaveEntity(playerDivideEntity1);
StorageAgent.Instance.SaveEntity(playerDivideEntity2);
StorageAgent.Instance.SaveEntity(playerDivideEntity3);
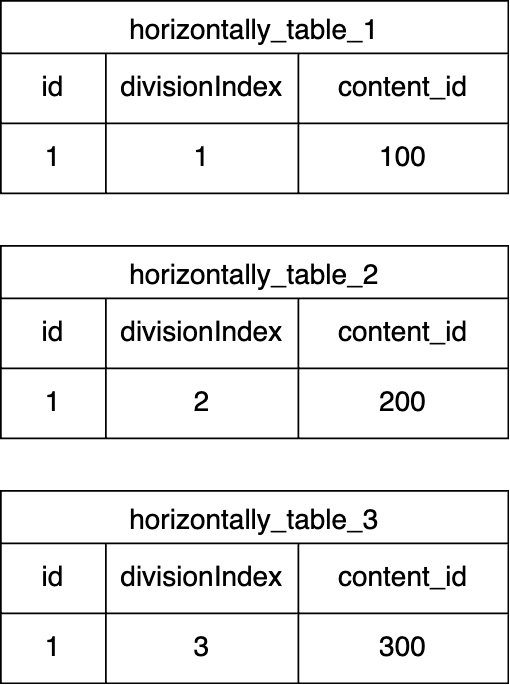
上記の様な定義を保存APIに投げると、DivisionIndexを参照してテーブルが更新され下記の状態になります。
データ読み込みのケースではキャッシュアクセス用のhelperが水平分割考慮された状態で自動生成され提供されます。
//自動生成
public class PlayerCache
{
//divisionCount分キャッシュも分割される
public PlayerTestDiv PlayerTestDiv1 { get; set; } = null;
public PlayerTestDiv PlayerTestDiv2 { get; set; } = null;
public PlayerTestDiv PlayerTestDiv3 { get; set; } = null;
//DivisionIndexを投げると紐付いたキャッシュを返すAPI
public PlayerTestDiv FetchPlayerTestDiv(int index)
{
switch (index)
{
case 1: return PlayerTestDiv1;
case 2: return PlayerTestDiv2;
case 3: return PlayerTestDiv3;
}
return null;
}
}
MasterのEntityは自動生成されるため、設定ファイルに分割数を指定する事でEntitiyごと生成する形をとっています。
この対応により大量のレコードを扱うデーブルが分割され、データ量の増加に共なうパフォーマンスの低下を抑える事ができました。
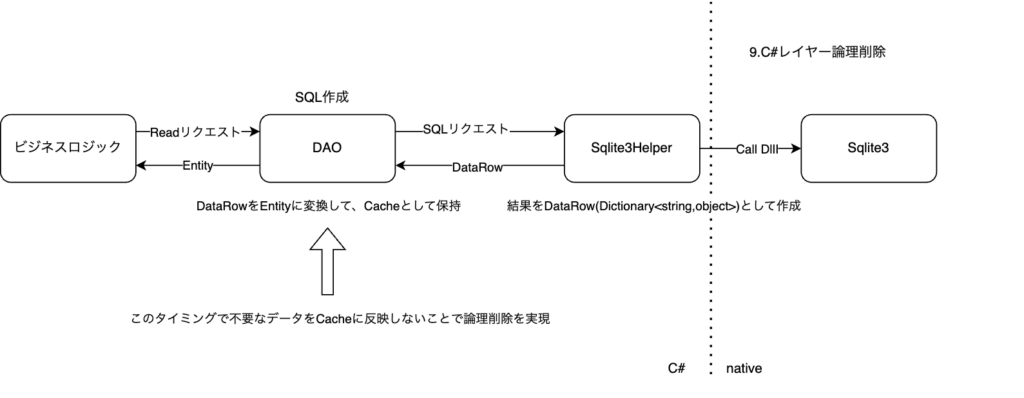
非効率な論理削除
既存基盤でもEntityキャッシュのデータ量問題の対策として、論理削除が実装されていました。
ただ、削除のタイミングがC#レイヤーのEntityキャッシュ後に行われており、データ自体はキャッシュに乗るため非効率でした。
//手動定義
public class PlayerDTOBase
{
public bool LogicallyDeleted;
}
//手動定義
public class PlayerInfoDTO : PlayerDTOBase
{
public int Id;
public string AppVersion;
}
//自動生成
public class PlayerInfoDAO
{
public List Cache {get;} = new();
void LoadRecords()
{
//この時点では論理削除されてデータも入っている
List<Dictionary<string, object>> allRows Records = BaseDAO.GetAllData();
foreach (var raw in allRows)
{
var hasKey = raw.TryGetValue("logically_deleted",out int value);
var isLogicallyDeleted = hasKey && value == 1;
if(!isLogicallyDeleted)
{
Cache.Add(Row2DTO(raw));
}
}
}
public PlayerInfoDTO Row2DTO(Dictionary<string, object> row)
{
var dto = base.Row2DTO(row);
dto.Id = row.TryGetValue("id", out object id)? (int)id : 1;
dto.AppVersion = row.TryGetValue("app_version", out object appVersion)? (string)appVersion : "0";
return dto;
}
}
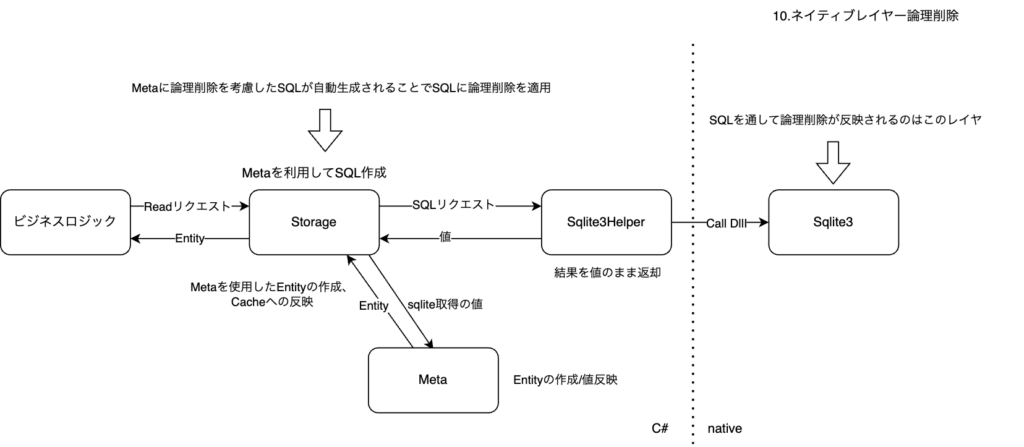
新基盤での対応
DB上で論理削除が行えるようなsqlをmeta上で自動生成することで対応しました。
//基盤定義
public interface ILogicalDeleteEntity
{
bool IsLogicalDeleted { get; set; }
}
//プロジェクト定義
[Table("player_info", enableLogicalDelete:true)]
public class PlayerInfo : ITableEntity,IPlayerInfo,ILogicalDeleteEntity
{
[Column("id", "INTEGER", "PRIMARY KEY NOT NULL", "1")]
public int PrimaryIndex { get; set; }
[Column("is_logical_deleted", ColumnDataType.Boolean, "NOT NULL", "false")]
public bool IsLogicalDeleted { get; set; }
[Column("app_version", "TEXT", "NOT NULL", "0")]
public string AppVersion { get; set; }
}
//自動生成
public sealed class PlayerInfotMeta
{
public string SelectSQL => IsActiveLogicalDeleted ? $"論理削除が考慮されたクエリ" : $"論理削除を無視したクエリ";
public string SelectSQLFirst => IsActiveLogicalDeleted ? $"論理削除が考慮されたクエリ" : $"論理削除を無視したクエリ";
//リクエストの際のフラグが反映される
public bool IsActiveLogicalDeleted {get; set;}= true;
}
//ユースケース
void Test()
{
var cache = new PlayerCache();
StorageAgent.Instance.Setup(cache);
// 論理削除を無視した読み込み
var entity1 = StorageAgent.Instance.LoadEntity(enableLogicalDelete: false);
// 論理削除を考慮した読み込み
var entity2 = StorageAgent.Instance.LoadEntity(enableLogicalDelete: true);
}
この対応によってdbレイヤーで削除済みデータを作成できるため、C#レイヤーで作成するEntityを減らすことができました。
過剰保存
課題
既存基盤では、Entityの単体更新に課題がありました。
public class PlayerInfoDTO
{
public int Id;
public string AppVersion;
}
void テーブルの情報更新()
{
var dao = new PlayerInfoDAO();
//テーブル上の全てのレコードをキャッシュ化
dao.LoadRecords();
var info = dao.Cache.Last();
info.AppVersion = "new version";
dao.Save(dto => dto.Id == info.Id);
}
更新したDTOを、Predicateの形で保存条件を指定する必要があった点です。
var info = dao.Cache.Last();
info.AppVersion = "new version";
dao.Save(dto => dto.Id == info.Id);
既存基盤のDTO設計だと統一したインターフェースが無かったため、毎回保存条件を設定する必要がありました。
この方法は煩雑だったため実際のプロジェクト運用だと下記方法が多用されていました。
void テーブル情報更新のプロジェクトコード運用()
{
var dao = new PlayerInfoDAO();
//テーブル上の全てのレコードをキャッシュ化
dao.LoadRecords();
var info = dao.Cache.Last();
info.AppVersion = "new version";
dao.SaveAll();
}
このSaveAllはDAOは保有するキャッシュを全て保存する機能です。
更新したデータが1件に対しDAOを持つキャッシュ全てを保存するため、
データ量が大きくなるにつれ更新量とキャッシュ量の乖離が大きくなり、過剰保存の問題が顕在化する懸念がありました。
新基盤での対応
Entityに主キーを定義する共通インターフェースを提供し、それを元にEntityを保存するAPIを用意しましました。
//手動定義
[Table("player_info", true, true)]
public class PlayerInfo : ITableEntity,IPlayerInfo
{
[Column("id", "INTEGER", "PRIMARY KEY NOT NULL", "1")]
public int PrimaryIndex { get; set; }
[Column("app_version", "TEXT", "NOT NULL", "0")]
public string AppVersion { get; set; }
}
//基盤定義
public interface ITableEntity
{
int PrimaryIndex { get; set; }
}
void 単体レコードの情報更新のユースケース()
{
var cache = new PlayerCache();
StorageAgent.Instance.Setup(cache);
var info = cache.PlayerInfo;
info.AppVersion = "new version";
//基盤側でPrimaryIndexを元にDBとキャッシュに反映
StorageAgent.Instance.SaveEntity(info);
}
void 複数レコード更新のユースケース()
{
var cache = new PlayerCache();
StorageAgent.Instance.Setup(cache);
var infos = new List()
{
new PlayerInfo(){PrimaryIndex = 1,AppVersion="1"},
new PlayerInfo(){PrimaryIndex = 2,AppVersion="2"},
};
//基盤側でPrimaryIndexを元にDBとキャッシュに反映
StorageAgent.Instance.SaveEntities(infos);
}
このAPI追加により単体/複数を問わず、PrimaryIndexを使用しての効率的なリクエストが行えるようになりました。
データ変更量とキャッシュ量との乖離があるケース、プレイヤーの所持品や所持キャラなど長期運用でキャッシュ量が増える様なデータ設計に対する効果が期待できます。
計測
新基盤と既存基盤のシナリオ毎の計測結果です。
計測環境
M1 Max 64G
Unity 2022.3
TestRunner 1.1.33
計測環境はPerformance Testing Extensionを使用し、下記のようにウォームアップをかけて100回ほど計測しています。
計測結果はマイクロ秒です。
Measure.Method(() =>
{
//計測内容
})
.WarmupCount(10)
.MeasurementCount(100)
.Run();
結果
保存シナリオ
データのキャッシュ数は1000固定です。
保存条件を指定しない保存
既存基盤のSaveAllによる保存と、新基盤SaveEntitiesの比較です。
新旧での最もよく使われる保存APIのユースケース比較になります。
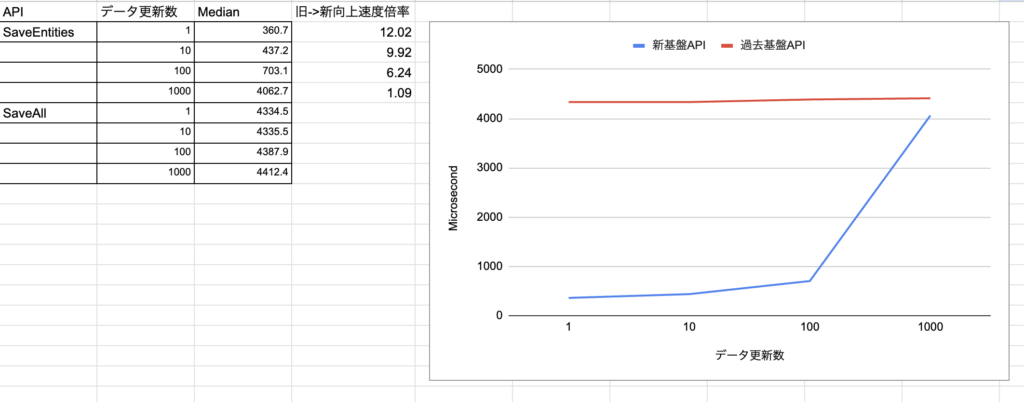
新基盤の方が1.09~12.02倍ほど高パフォーマンスになっています。
既存基盤のSaveAllの場合、キャッシュを全て保存するため更新データ量に関わらず負荷がかかります。
新基盤だとリクエストの方法が改善されたため、キャッシュ量とデータの変更数の乖離があるケースでもパフォーマンスが発揮されるようになりました。
保存条件を指定した保存
既存基盤のPredicate<DTO>による保存と、新基盤SaveEntitiesの比較です。
PrimaryIndexやIDでのデータを指定した永続化のパフォーマンス比較になります。
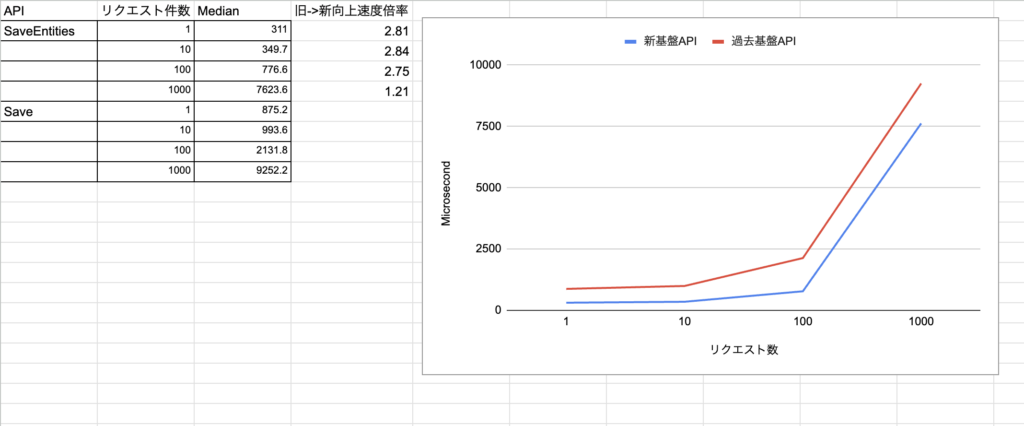
新旧で同じような負荷の傾向が出ていますが、新基盤の方が1.2~2.8倍ほど高パフォーマンスになっています。
読み込みシナリオ
論理削除のないデータ読み込み
既存基盤のRecord2Cacheによる読み込みと、新基盤LoadEntitiesの比較です。
新旧での最もよく使われる読み込みAPIのユースケース比較になります。
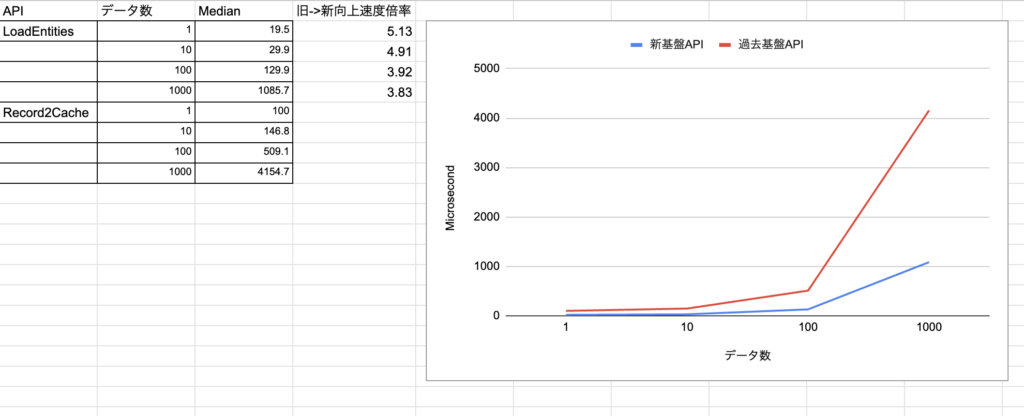
件数の増加に伴い倍率は下がるものの、3.8~5.1倍のパフォーマンス向上になっています。
書き込みのAPIに比べ精度が向上しているのは、アロケーション抑制の効果が出ていそうです。
論理削除のありデータ読み込み
論理削除の効果を図るために、読み込みの計測1で使用したAPIの対象を論理削除を有効にしたテーブルにして計測しています。
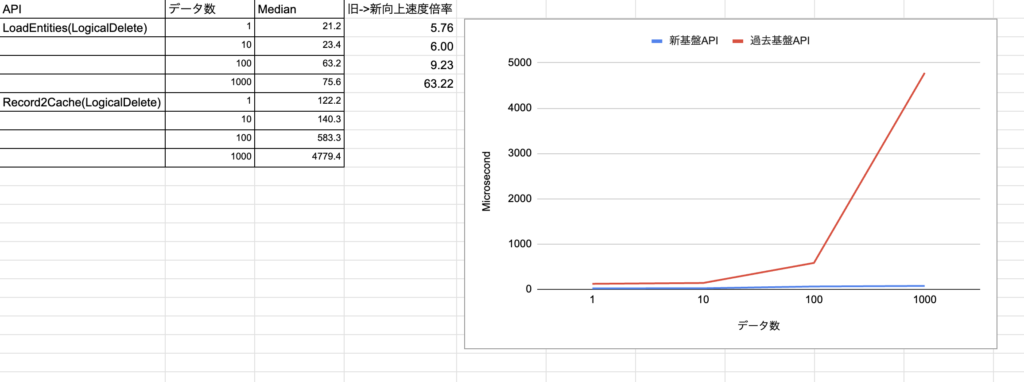
新旧の比較で、5~63倍のパフォーマンス向上効果が出ています。
論理削除を行うレイヤーをネイティブ上に写したことで、sqliteの本領が発揮された効果が出ていそうです。
まとめと今後
新規基盤の導入により、既存基盤で発生した課題を解決すると共に、高頻度シナリオでは最大1200%、ニッチなケースも含めると最大6300%の性能向上を達成する事ができました。
また、既存基盤であった秘伝のタレ化を解除、専用のDLLにしたことでテスト可能性も上がった事で、
必要であればプロダクトと並行して基盤機能を更新していけるフットワークの軽さを得られたことも個人的には良かったなと思います。
新基盤のStorageは2020.7に開発を開始し、一ヶ月ほどで開発した基盤がスタートラインでした。
開発から3年で複数のタイトルに導入され、各タイトルでの要望を共通仕様として取捨選択しながら今に至ります。
いくつかの理由から基盤が安定するまではあえて1人に属人化させ速度と精度と担保して来ましたが、*3
今後は属人化解除を行なっていき、多くのエンジニアでプロダクトと共栄できる基盤を目指していく予定です。
昨今のアプリ開発だとローカルにデータを持つのはかなりニッチかと思いますが、どなたかの開発の参考になれば幸いです。
最後に、新しい基盤の導入に協力してくれたプロダクトチームのメンバーへ、この場を借りて感謝申し上げます。
注釈
*1 : ローカルにデータを置く関係上、セキュリティ強化やデータの復旧環境などは別途対応しています。
*2 : 新基盤だとint/long/float/string/boolに対応しています。
*3 : 元々隠蔽されていたレイヤなので、知識を紐解いて浸透させるコストが高かった点、
プロダクトの開発で生まれた要望を基盤としてのドメインを守りながら新基盤を更新していくにも少人数が好都合だった点