




はじめに
こんにちは。基幹システム本部・物流開発部の作田です。現在、ZOZO社内で使用している基幹システムのリプレイスを担当しています。
現在行っているリプレイスでは、既存の基幹システムから発送機能を切り出し、マイクロサービスに移行しています。リプレイスの詳細については、ZOZOBASEを支える発送システムリプレイスの取り組みをご覧ください。
マイクロサービスは発送業務の各作業が完了したことを基幹システムに連携しており、この連携を実現するためにAmazon Managed Streaming for Apache Kafka(以降、Amazon MSK)を採用しました。今回は、サービス間のデータ連携にAmazon MSKを採用した理由やAmazon MSKでの実装例と考慮点について紹介します。MySQLなどのリレーショナルデータベースに対してAmazon MSKを用いて非同期でデータを連携する事例として参考になれば幸いです。
目次
システム要件と設計
システム要件とそれを満たすために考えた設計を順番に説明します。
システム要件
発送マイクロサービスから基幹システムにデータを連携させるにあたって2つの要件がありました。
- 発送マイクロサービスが独立して動作可能
- 更新したデータの即時連携
この2つのシステム要件について簡単に説明します。
発送マイクロサービスが独立して動作可能
発送マイクロサービスは基幹システムに障害が発生しても発送業務を遂行できることを目指しています。そのため、発送マイクロサービスが独立して動作できるシステムを構築する必要がありました。
更新したデータの即時連携
発送マイクロサービスは発送業務の各作業(ピック作業や梱包作業)が完了したことを基幹システムに連携する必要があります。連携されたデータは実績の確認などに使用され、一時的に発送マイクロサービスとデータが異なることは許容できますが結果整合性を担保する必要があります。また、実績の乖離による作業者の混乱を防ぐためデータの連携には即時性が求められました。
これらの要件を満たすには、サービス間を疎結合にして非同期でデータを連携する必要があります。要件を満たすためのシステム概要図は以下の通りです。基幹システムは発送業務に必要なデータを非同期で発送マイクロサービスに連携し、発送マイクロサービスはデータの変更を非同期で基幹システムに連携します。今回は発送マイクロサービスから基幹システムへのデータ連携に焦点を当てます。
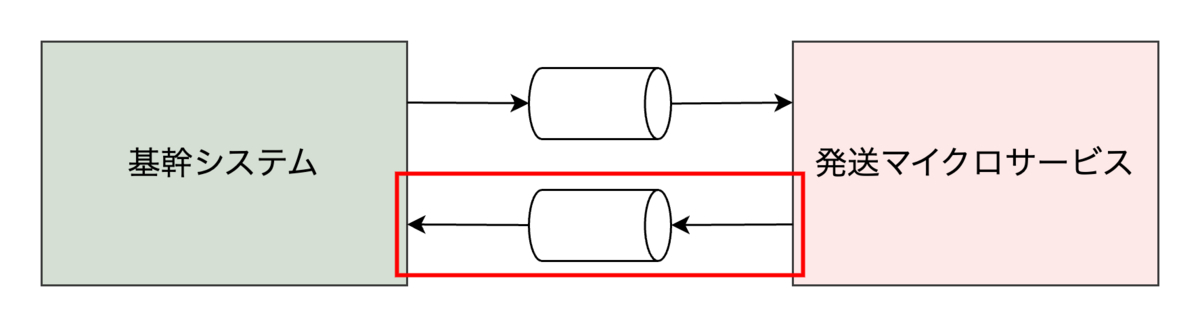
システム設計
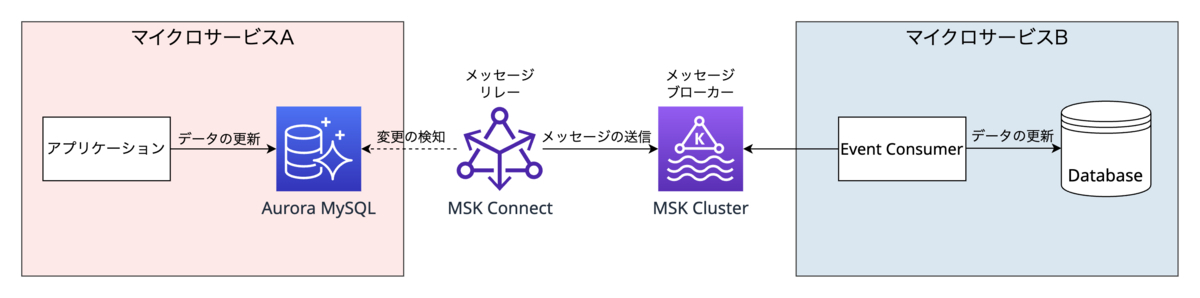
非同期でデータを連携させる上で、データベースの更新とメッセージングシステムへの書き込みに整合性が必要となります。データベースとメッセージングシステムへそれぞれ書き込みを行った場合、どちらかの処理が失敗するとデータの不整合が発生してしまいます。この問題を解決するために、Outboxパターンを採用しました。
発送マイクロサービスでのOutboxパターンの実装例を説明します。前提として、データベースには社内で広く使われているAurora MySQLを選定しています。Outboxパターンの考えに基づいて、集約の状態更新(itemsテーブルの更新)とドメインイベントの発行(item_eventsテーブルへの書き込み)を同一トランザクションで行います。そして、メッセージリレーはイベントテーブルに書き込まれた内容をメッセージブローカーに送信します。これにより、データベースの更新とメッセージングシステムへの書き込みの整合性を担保できます。

技術選定
Outboxパターンを実現するために、Apache KafkaのフルマネージドサービスであるAmazon MSKを採用しました。次の節で、Amazon MSKを採用した理由について説明します。
選定理由
Amazon MSKを採用した理由は、Debeziumコネクタが提供されているApache Kafkaをフルマージドで運用可能だからです。なぜDebeziumやApache Kafkaが必要なのかを順番に説明します。
データベースにMySQLを選定しているため、Outboxパターンの実現にはMySQLのデータ変更を検知してメッセージブローカーにデータを送信する仕組みが必要です。データがいつどのように変更されたかを検出する仕組みのことをChange Data Capture(以降、CDC)と言います。今回はCDCを実現するためにDebeziumを採用することにしました。Debeziumは様々なデータベースに対してCDCを実現でき、MySQLではbinlogを読み取りコミットされた変更を検知しています。DebeziumはApache Kafka Connectを使用してデプロイされることが一般的で、Kafka Connectを使用することでデータソースやデータターゲットへの接続が容易になります。そのため、メッセージリレーにApache Kafka Connect、メッセージブローカーにApache Kafkaを採用しました。Apache Kafkaはストリーミングデータを処理するために必要なアプリケーションの実行や構築ができるプラットフォームです。
そして、Apache Kafkaの運用のコストをできるだけ下げるために、フルマネージドサービスであるAmazon MSKを採用しました。Amazon MSKには、Kafka Brokerを持つMSK ClusterとDebeziumをカスタムプラグインとしたMSK Connectが含まれています。MSK Connectではイベントテーブルの変更を検知して、MSK Clusterにメッセージを送信しています。Event Consumerは、MSK Clusterに対して100ミリ秒間隔でメッセージのポーリングを行い、データベースを更新しています。Amazon MSKによって、できるだけ早く別のサービスにデータ連携するという要件をフルマネージドなサービスで実現できました。
非機能要件の検証
Amazon MSKは社内での導入実績がなかったため、SRE担当者と協力し以下の非機能要件について検証しました。
- 性能・拡張性
- 信頼性
- 可用性
性能・拡張性に関しては、複数のシナリオを考慮した負荷試験を行い、本番相当のデータをinsertし続けてもMSK ConnectがMSK Clusterにデータを送れることを確認しました。信頼性と可用性に関しては次の節で詳しく説明します。
信頼性と可用性の検証
信頼性と可用性を高めるために以下の点について考慮しました。
- オフセット情報の消失
- Kafka Brokerの停止
- MSK Connectの停止
オフセット情報の消失はアプリケーション側で考慮しており、Kafka BrokerやMSK Connectの停止はインフラ側で考慮しているのでそれぞれ説明します。
オフセット情報の消失
Event ConsumerがPartitionのどこまでメッセージを読み込んだかのオフセットはKafka Broker内のトピックで管理しています。このオフセット情報が何かしらの理由で失われてしまった場合を考慮して、ConsumerConfig.AUTO_OFFSET_RESET_CONFIGにearliestを設定しています。earliestに設定すると、オフセット情報が存在しない場合はPartitionの最初からメッセージを読み直します。これにより全てのメッセージが1回以上読み出されるため、Event Consumerは冪等性を考慮した実装が求められます。本システムでは、イベントテーブルにシーケンス用のカラムを用意し、イベントの発行順序が分かるようにしています。このシーケンス番号を元に処理済みのメッセージかどうかを判断し、重複処理をしないようにしています。
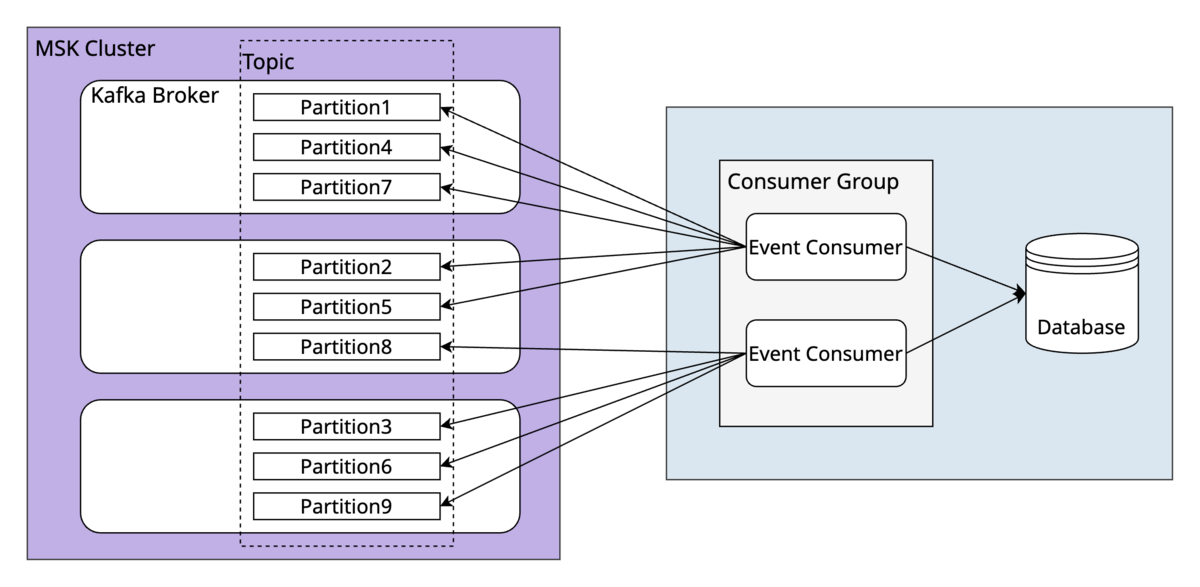
また、MSK Connectもどこまでメッセージを送信したかのオフセットを指定したトピックに保存しています。このオフセット情報が消失した場合、binlogの最初から再度メッセージが送信されますが、Event Consumer側で重複処理をしないように実装しているため問題ありません。
Kafka BrokerやMSK Connectの停止
Kafka BrokerやMSK Connectが何かしらの理由で停止してしまった場合を考慮して、AZ障害を模擬した障害試験を実施しました。MSK Clusterでは3つのBrokerを用いて冗長化し、Partitionごとにデータをレプリしているため、Kafka Brokerの1つが停止してもデータが欠損しません。実際に1つを停止してみましたが、発送マイクロサービスから別のサービスへのデータ連携が滞りなく行われることを確認しました。
MSK ConnectではDebeziumを使用しているため、1つのタスクしかサポートされておらず冗長化できません。また、何らかの理由でfailed(=produce処理ができない)の状態で止まってしまった場合は再起動できず、再作成をする必要があります。再作成に15分程度かかりますが、再作成が完了すればデータの欠損なく連携できることを確認しています。頻繁にMSK Connectの再作成が必要であれば、Airbyteなどの他のツールへの乗り換えを検討していきたいです。
検証によって分かったデメリット
検証によって、MSK Connectがfailedの状態で止まった場合や設定を変更した場合に再作成しなくてはならないことが分かりました。MSK Connectの再作成時に発生するデメリットは以下の通りです。
- 再作成が完了するまでの15分程度はメッセージの送信ができない
- 再作成時にテーブルに対して読み取りロックが発生する(100万件で1分程度)
今回は、これらのデメリットを容認できたため、Amazon MSKでデータ連携することを決めました。参考としてご覧いただけると幸いです。
実装例
ここからはMSK ConnectとEvent Consumerの実装について紹介します。
MSK Connect
Producerの実装は行わず、MSK ConnectにDebeziumを採用することでマネージドにCDCを実現しました。MSK Connectはイベントテーブルのみを監視するように設定し、イベントテーブルごとにトピックを用意しています。これにより、イベントテーブルAの変更はトピックA、イベントテーブルBの変更はトピックBにメッセージが送信されます。
Kafkaは同一のPartitionでのみ順序を保証しているため、順序保証が必要であれば同一のPartitionにメッセージを入れる必要があります。デフォルトでは監視しているテーブルの主キーのハッシュに基づいて各Partitionにメッセージを振り分けます。今回のケースでは、同じ集約IDのイベントに対して順序保証をしたいため、イベントテーブルの主キーではなく集約IDのカラムに基づいて各Partitionに振り分ける設定を入れています。現時点では、バージョン2.1のDebeziumを使用しているためComputePartitionで設定していますが、廃止予定なのでPartitionRoutingで設定できるように対応する予定です。

Event Consumer
次に、Event Consumerの実装例を紹介します。使用している言語のバージョンは以下の通りです。
| 種類 | バージョン |
|---|---|
| Java | 17 |
| Spring Boot | 2.7.1 |
Spring Boot 2.7.xでKafkaを使用するため、build.gradleに依存関係を追加します。
implementation 'org.apache.kafka:kafka-clients:3.2.3' implementation 'org.springframework.kafka:spring-kafka:2.9.3'
コードの関係は以下のようになっています。今回はEventConsumer.javaとKafkaConsumerConfig.javaについて説明していきます。
app/
|-- EventConsumer.java
`-- config
|-- KafkaConsumerConfig.java
`-- KafkaConsumerSettings.java
consume処理
EventConsumer.javaでは、@KafkaListenerアノテーションを使用してメッセージのconsume処理を実装しています。consumeメソッドはメッセージが受信できたときに呼び出され、どのパーティションからメッセージが来たのかなどを把握できます。このコード例では受け取ったメッセージをログに出力しています。後続の処理では、メッセージの値をJavaのクラスに変換してデータベースを更新していますが、consume処理とは直接関係ないため割愛します。
@Slf4j public class EventConsumer { @KafkaListener(topics = "${kafka.consumer.topic}") public void consume(ConsumerRecord<String, String> record) { log.info( String.format( "Consumed event from %s topic, partition %d : key = %s, value = %s", record.topic(), record.partition(), record.key(), record.value())); // record.value()に対して処理を行う } }
@KafkaListenerアノテーションを使用するためには、@Configurationと@EnableKafkaアノテーションが付与されたクラスを作成し、リスナーコンテナーファクトリを用意する必要があります。コード例に記載されているKafkaConsumerSettingsクラスではapplication.yamlから読み取った環境変数の値を保持しており、KafkaConsumerConfigクラスではリスナーコンテナーファクトリを提供しています。KafkaConsumerConfigクラスのconsumerFactoryメソッドではConsumerに関する設定を定義しており、getDefaultErrorHandlerメソッドでは例外発生時の処理方法を指定しています。
@Slf4j @EnableKafka @Configuration @RequiredArgsConstructor @EnableConfigurationProperties({KafkaConsumerSettings.class}) public class KafkaConsumerConfig { private final KafkaConsumerSettings settings; @Bean KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory() { final ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.getContainerProperties().setPollTimeout(3000); factory.setCommonErrorHandler(getDefaultErrorHandler()); return factory; } private ConsumerFactory<String, String> consumerFactory() { final HashMap<String, Object> props = new HashMap<>(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, settings.getBootstrapServers()); props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, settings.getAutoOffsetReset()); props.put(ConsumerConfig.GROUP_ID_CONFIG, settings.getGroupId()); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); return new DefaultKafkaConsumerFactory<>(props); } private DefaultErrorHandler getDefaultErrorHandler() { // 3秒から始まり2倍ずつ増えていく。最大値は30秒 // ex) 3, 6, 12, 24, 30, 30, 30, ... final var backOff = new ExponentialBackOff(3000L, 2); // 合計で1分経過したら再試行を停止する backOff.setMaxElapsedTime(60000L); final var defaultErrorHandler = new DefaultErrorHandler( (consumerRecord, exception) -> { log.error(exception); // 処理できなかったメッセージをデータベースに保存する }, backOff); // SQL周りで発生した例外だけリトライする defaultErrorHandler.addNotRetryableExceptions(Exception.class); defaultErrorHandler.addRetryableExceptions(SQLException.class); return defaultErrorHandler; } }
例外発生時の処理
getDefaultErrorHandlerメソッドでは、SQL周りで例外が発生した場合のみ処理をリトライするように設定しています。リトライ時は、エクスポネンシャルバックオフを指定し、書き込み先のデータベースに過度な負荷がかからないようにしています。リトライ試行期間が合計1分を超えたらDefaultErrorHandlerで定義した処理が実行されます。DefaultErrorHandlerで定義した処理にも失敗した場合は、オフセットがコミットされないので再び同じメッセージをポーリングします。この仕組みによって、書き込み先のデータベースがダウンしているときは、永遠に同じメッセージを処理し続けるようにしてデータの連携が止まるようにしています。
メッセージが処理できなかった場合は、受け取ったメッセージをそのままデータベースに保存するようにDefaultErrorHandlerで設定しています。dead-letter用のトピックにメッセージを送信する方法が一般的で、デットレタリングされたメッセージを元のトピックに戻すなどのリカバリー処理が容易です。しかし、処理できなかったメッセージを直接確認するためにはトピックからメッセージを受け取る仕組みを作成する必要があり、データベースと比べて手間がかかります。初期リリース時は処理できなかったメッセージの確認をすぐに行いたかったため、データベースにメッセージを保存するという選択をしました。
おわりに
発送マイクロサービスの初期リリースが完了し、現在は既存の基幹システムから段階的に移行しています。この過程では、引き続き既存の基幹システムを使用しながら、発送マイクロサービスで少しずつ発送処理をしています。現時点では、データ処理量が限定的なのでデータの連携は数秒ほどで完了しています。負荷試験において、本番環境と同量のデータが処理できることを確認しましたが、既存システムと同量のデータを持続的に処理したわけではありません。処理するデータ量が増えたときに問題点が見つかれば改善していきたいです。
本記事では、マネージドサービスであるAmazon MSKを用いてMySQLに対してCDCを実現する事例を紹介しました。Amazon MSKはOutboxパターンでドメインイベントを伝える仕組みと相性が良いため、イベント駆動型アーキテクチャでの導入を検討してみてはいかがでしょうか。
ZOZOの基幹システムの開発・リプレイスに興味を持ってくださった方は、以下のリンクからぜひご応募ください。