はじめまして。CADDiでバックエンドエンジニアとして働いている中野です。
この記事では、Cloud Data Fusionを利用して作成したデータパイプラインについてご紹介します。
TL;DR
SalesforceとBigQuery間のデータ連携にHeroku Connectをこれまで利用していたのですが、Cloud Data Fusionに乗り換えることでダウンタイムなしで約1/8までコストダウンができました。
モチベーション
弊社では、Salesforceに溜まったデータをBigQueryに連携し、営業などのBizサイドの組織も含めアクセスできる状態にしております。これまでは連携に Heroku Connect及びHeroku Postgresと StitchというCloud Data Pipelineを用いていました。
しかし、Heroku Connect及びHeroku Postgresの利用料が高額でコストダウンしたいというモチベーションがありました。
乗り換え先として、EmbulkなどのOSSを利用して自分たちでホスティングを行う方法なども検討に上がりましたが、なるべくメンテナンスコストをかけたくないことから、要件を全て満たせそう且つフルマネージドなCloud Data Fusionを使うことに決定しました。
Cloud Data Fusionについて
Cloud Data Fusion は、データ パイプラインを迅速に構築し管理するための、フルマネージドかつクラウド ネイティブなエンタープライズ データ統合サービスです。Cloud Data Fusion は、データ パイプラインを迅速に構築し管理するための、フルマネージドかつクラウド ネイティブなエンタープライズ データ統合サービスです。
引用:https://cloud.google.com/data-fusion/docs/concepts/overview?hl=ja
UIからの操作も直感的に可能で、シンプルなパイプラインであればエンジニア以外でも簡単にデプロイすることができます。
構成
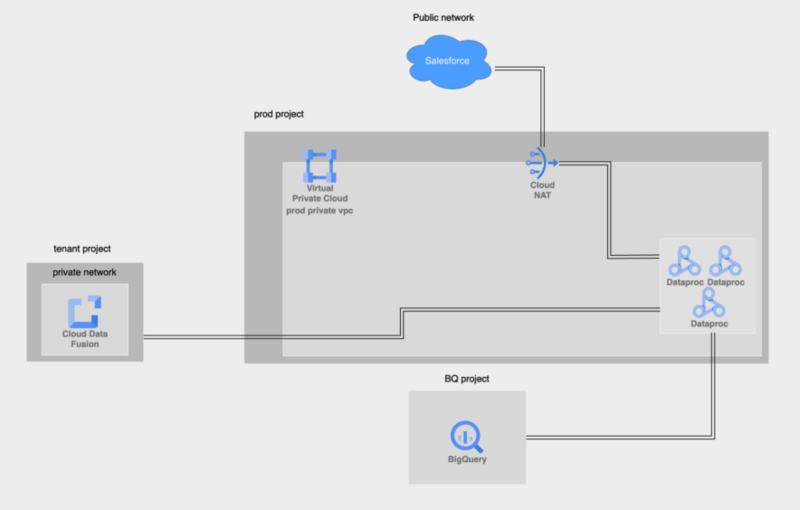
今回我々がやりたかったことは、「SalesforceにあるデータをBigQueryに連携する」ということです。それを実現するために、Cloud Data Fusionのデプロイは以下の構成で行いました。
▽図1:システム構成図

しかし、一度デプロイした後には不要になるリソースがいくつかあります。そのためデプロイが完了し、DataprocクラスターをCloud Data Fusionがプロビジョニング可能な状態になった後には、定期実行のスケジュールを設定し不要なリソースを削除した上で、以下の構成で運用しています。
Dataprocはバッチ処理などを行うためのマネージドサービスです。Dataprocが実際にSalesforceと通信してデータを取得し、BigQueryにデータを貯める役割を担っています。Dataprocの詳細は最後に参考文献として載せています。
▽図2:リソース削除後システム構成図
マイグレーションプラン
弊社では様々な部署がBigQueryに蓄積されたデータを元に業務を行っているため、できる限りダウンタイムを作らずにマイグレーションを行う必要がありました。そのため以下方針でマイグレーションを行い、ダウンタイムを発生させずに作業を完了させることができました。(前提として、BigQueryの利用者はこれまでSalesforceのデータが連携されていた dataset sf_heroku_connect にある各テーブルを直接参照せず、dataset sf にあるViewを経由してデータにアクセスしておりました。)
- Cloud Data Fusionのリソースを作成し、dataset
sf_cloud_data_fusionの各テーブルにSalesforceから取得したデータを格納する。 dataset
sfのデータソースを datasetsf_heroku_connectの各テーブルから、 datasetsf_cloud_data_fusionの各テーブルに置き換える。しばらく稼働させ、問題が発生しないか確認する。
dataset
sf_heroku_connectを削除する。
実装詳細
以下リソースの定義を行いました。
実際には、module化して管理しておりますが、ここではブログ用に基本的にresourceとして定義しています。また、BigQueryのリソースも実際には別プロジェクト内に配置してあるのですが、ここでは簡易化のために同一プロジェクト内に配置しております。
FILL_YOUR_XXXと記載がある箇所はご自身で適切なIPレンジに置き換えてください。
全体設定
provider "google" {
project = "sample-project"
region = "asia-northeast1"
zone = "asia-northeast1-c"
}
data "google_client_config" "current" {}
provider "cdap" {
host = "${module.wait_healthy.service_endpoint}/api"
token = data.google_client_config.current.access_token
}
terraform {
required_providers {
google = {
source = "hashicorp/google"
version = "4.78.0"
}
google-beta = {
source = "hashicorp/google-beta"
version = "4.73.2"
}
cdap = {
source = "GoogleCloudPlatform/cdap"
version = "~> 0.10"
}
}
required_version = ">= 1.1"
}
Cloud Data Fusion関連リソース
# Service Account
resource "google_service_account" "sa_for_data_fusion" {
project = "sample-project"
account_id = "data-fusion-instance-sa"
display_name = "For cloud data fusion"
}
resource "google_project_iam_member" "sa_for_data_fusion_role_bindings" {
project = "sample-project"
for_each = toset([
"roles/storage.admin",
"roles/datafusion.runner",
"roles/dataproc.worker",
"roles/bigquery.jobUser",
])
role = each.key
member = "serviceAccount:${google_service_account.sa_for_data_fusion.email}"
}
locals {
data_fusion_service_account = "service-${data.google_project.data_fusion_project.number}@gcp-sa-datafusion.iam.gserviceaccount.com"
}
resource "google_service_account_iam_binding" "google_managed_sa_role_bindings" {
service_account_id = "projects/sample-project/serviceAccounts/${google_service_account.sa_for_data_fusion.email}"
role = "roles/iam.serviceAccountUser"
members = [
"serviceAccount:${local.data_fusion_service_account}",
]
}
# Data Fusion
resource "google_data_fusion_instance" "create_instance" {
name = "data-fusion-instance-name"
description = "data-fusion-instance-description"
region = "asia-northeast1"
type = "DEVELOPER"
enable_stackdriver_logging = true
enable_stackdriver_monitoring = true
private_instance = true
dataproc_service_account = google_service_account.sa_for_data_fusion.email
network_config {
network = "sample-private-network"
ip_allocation = "FILL_YOUR_IP_RANGE_OF_DATAFUSION_INSTANCE"
}
version = "6.9.1"
}
# Source is from
# https://cdfhub-asia-northeast1.storage.googleapis.com/hub/packages/plugin-salesforce/1.6.0/salesforce-plugins-1.6.0.json
# https://cdfhub-asia-northeast1.storage.googleapis.com/hub/packages/plugin-salesforce/1.6.0/salesforce-plugins-1.6.0.jar
resource "cdap_local_artifact" "salesforce-plugins" {
name = "salesforce-plugins"
version = "1.6.0"
json_config_path = "path/to/file/salesforce-plugins-1.6.0.json"
jar_binary_path = "path/to/file/salesforce-plugins-1.6.0.jar"
depends_on = [google_data_fusion_instance.create_instance]
}
data "google_project" "data_fusion_project" {
project_id = "sample-project"
}
resource "cdap_application" "sf-bq-sync-account" {
name = "sf-bq-sync-account"
spec = file("path/to/file/sf-bq-sync-account-cdap-data-pipeline.json")
depends_on = [google_data_fusion_instance.create_instance, cdap_local_artifact.salesforce-plugins]
}
resource "cdap_application" "sf-bq-sync-user" {
name = "sf-bq-sync-user"
spec = file("path/to/file/sf-bq-sync-user-cdap-data-pipeline.json")
depends_on = [google_data_fusion_instance.create_instance, cdap_local_artifact.salesforce-plugins]
}
# https://github.com/terraform-google-modules/terraform-google-data-fusion/tree/master/modules/wait_healthy
module "wait_healthy" {
source = "terraform-google-modules/data-fusion/google//modules/wait_healthy"
version = "~> 0.1"
service_endpoint = google_data_fusion_instance.create_instance.service_endpoint
access_token = data.google_client_config.current.access_token
}
ネットワーク関連リソース
# Gateway VM
resource "google_service_account" "sa_for_gateway_vm" {
project = "sample-project"
account_id = "gateway-vm-instance-sa"
display_name = "For cloud data fusion gateway"
}
resource "google_compute_instance" "sample_gateway_vm" {
name = "sample-gateway-vm"
machine_type = "e2-micro"
zone = "asia-northeast1-b"
tags = ["allow-http-for-data-fusion", "allow-https-for-data-fusion"]
can_ip_forward = true
boot_disk {
initialize_params {
image = "debian-cloud/debian-11"
}
}
network_interface {
network = google_compute_network.sample_private_network.self_link
subnetwork = google_compute_subnetwork.sample_subnetwork.self_link
}
metadata_startup_script = "#! /bin/bash \n echo 1 > /proc/sys/net/ipv4/ip_forward \n iptables -t nat -A POSTROUTING -s FILL_YOUR_IP_RANGE_OF_DATAFUSION_INSTANCE -j MASQUERADE \n echo net.ipv4.ip_forward=1 > /etc/sysctl.d/11-gce-network-security.conf \n iptables-save"
service_account {
email = google_service_account.sa_for_gateway_vm.email
scopes = ["cloud-platform"]
}
shielded_instance_config {
enable_integrity_monitoring = true
enable_vtpm = true
}
metadata = {
block-project-ssh-keys = true
}
}
# VPC
resource "google_compute_network" "sample_private_network" {
project = "sample-project"
name = "sample-private-network"
auto_create_subnetworks = "false"
delete_default_routes_on_create = "false"
routing_mode = "REGIONAL"
}
resource "google_compute_subnetwork" "sample_subnetwork" {
project = "sample-project"
region = "asia-northeast1"
name = "sample-subnetwork"
ip_cidr_range = "FILL_YOUR_IP_CIDR_RANGE"
network = google_compute_network.sample_private_network.self_link
private_ip_google_access = "true"
}
resource "google_compute_network_peering" "sample_peering" {
name = "sample-peering"
network = google_compute_network.sample_private_network.self_link
peer_network = "https://www.googleapis.com/compute/v1/projects/${google_data_fusion_instance.create_instance.tenant_project_id}/global/networks/${google_data_fusion_instance.create_instance.region}-${google_data_fusion_instance.create_instance.name}"
export_custom_routes = true
}
# NAT
resource "google_compute_router" "router" {
name = "sample-router"
project = "sample-project"
region = "asia-northeast1"
network = google_compute_network.sample_private_network.self_link
bgp {
advertise_mode = "CUSTOM"
advertised_groups = ["ALL_SUBNETS"]
asn = "64512"
}
}
resource "google_compute_address" "address" {
name = "nat-ip"
project = "sample-project"
region = google_compute_router.router.region
}
resource "google_compute_router_nat" "cluster_router_nat" {
name = "sample-router-nat"
project = "sample-project"
region = google_compute_router.router.region
router = google_compute_router.router.name
nat_ip_allocate_option = "MANUAL_ONLY"
nat_ips = [google_compute_address.address.self_link]
source_subnetwork_ip_ranges_to_nat = "ALL_SUBNETWORKS_ALL_IP_RANGES"
log_config {
enable = true
filter = "ERRORS_ONLY"
}
}
# Firewall rule
resource "google_compute_firewall" "gateway_vm_for_data_fusion_allow_http_fw" {
project = "sample-project"
name = "gateway-vm-for-data-fusion-allow-http"
network = "sample-private-network"
allow {
ports = ["80"]
protocol = "tcp"
}
direction = "INGRESS"
disabled = "false"
priority = "1000"
source_ranges = ["FILL_YOUR_IP_RANGE_OF_DATAFUSION_INSTANCE"]
target_tags = ["allow-http-for-data-fusion"]
}
resource "google_compute_firewall" "gateway_vm_for_data_fusion_allow_https_fw" {
project = "sample-project"
name = "gateway-vm-for-data-fusion-allow-https"
network = "sample-private-network"
allow {
ports = ["443"]
protocol = "tcp"
}
direction = "INGRESS"
disabled = "false"
priority = "1000"
source_ranges = ["FILL_YOUR_IP_RANGE_OF_DATAFUSION_INSTANCE"]
target_tags = ["allow-https-for-data-fusion"]
}
# Route
resource "google_compute_route" "sf_bq_sync_route" {
name = "sample-route"
dest_range = "0.0.0.0/0"
network = google_compute_network.sample_private_network.self_link
next_hop_instance = google_compute_instance.sample_gateway_vm.self_link
priority = 1001
}
Secret Manager関連リソース
FILL_YOUR_CIPHERTEXT と記載がある箇所は google_kms_secret に従って、Cloud SDKを用いて暗号化したsecretを入れます。
google_kms_secretの例 だと、my-secret-passwordにpasswordなどのsecretを入れ、outputとして出てきたCiQAaCd+xX4SsOXziF10a8JYq4spf~~~をFILL_YOUR_CIPHERTEXTに登録します。
$ echo -n my-secret-password | gcloud kms encrypt \
> --project my-project \
> --location us-central1 \
> --keyring my-key-ring \
> --key my-crypto-key \
> --plaintext-file - \
> --ciphertext-file - \
> | base64
CiQAqD+xX4SXOSziF4a8JYvq4spfAuWhhYSNul33H85HnVtNQW4SOgDu2UZ46dQCRFl5MF6ekabviN8xq+F+2035ZJ85B+xTYXqNf4mZs0RJitnWWuXlYQh6axnnJYu3kDU=
(引用:google_kms_secret )
# secret manager
resource "google_secret_manager_secret" "salesforce_username" {
project = "sample-project"
secret_id = "salesforce-consumer-secret"
replication {
automatic = true
}
}
resource "google_secret_manager_secret" "salesforce_password" {
project = "sample-project"
secret_id = "salesforce-consumer-key"
replication {
automatic = true
}
}
resource "google_secret_manager_secret" "salesforce_consumer_secret" {
project = "sample-project"
secret_id = "salesforce-consumer-secret"
replication {
automatic = true
}
}
resource "google_secret_manager_secret" "salesforce_consumer_key" {
project = "sample-project"
secret_id = "salesforce-consumer-key"
replication {
automatic = true
}
}
data "google_secret_manager_secret_version" "salesforce_username" {
project = "sample-project"
secret = google_secret_manager_secret.salesforce_username.id
}
data "google_secret_manager_secret_version" "salesforce_password" {
project = "sample-project"
secret = google_secret_manager_secret.salesforce_password.id
}
data "google_secret_manager_secret_version" "salesforce_consumer_secret" {
project = "sample-project"
secret = google_secret_manager_secret.salesforce_consumer_secret.id
}
data "google_secret_manager_secret_version" "salesforce_consumer_key" {
project = "sample-project"
secret = google_secret_manager_secret.salesforce_consumer_key.id
}
data "google_kms_secret" "salesforce_username" {
crypto_key = var.crypto_key
ciphertext = var.salesforce_username
}
data "google_kms_secret" "salesforce_password" {
crypto_key = var.crypto_key
ciphertext = var.salesforce_password
}
data "google_kms_secret" "salesforce_consumer_secret" {
crypto_key = var.crypto_key
ciphertext = var.salesforce_consumer_secret
}
data "google_kms_secret" "salesforce_consumer_key" {
crypto_key = var.crypto_key
ciphertext = var.salesforce_consumer_key
}
variable "crypto_key" {
type = string
default = "sample-project/global/sample/terraform"
}
variable "salesforce_password" {
type = string
sensitive = true
default = "FILL_YOUR_CIPHERTEXT"
}
variable "salesforce_username" {
type = string
sensitive = true
default = "FILL_YOUR_CIPHERTEXT"
}
variable "salesforce_consumer_key" {
type = string
sensitive = true
default = "FILL_YOUR_CIPHERTEXT"
}
variable "salesforce_consumer_secret" {
type = string
sensitive = true
default = "FILL_YOUR_CIPHERTEXT"
}
BigQuery関連リソース
# BigQuery
resource "google_bigquery_dataset" "sf_cloud_data_fusion" {
project = "sample-project"
dataset_id = "sf_cloud_data_fusion"
location = "asia-northeast1"
}
resource "google_bigquery_dataset_iam_member" "sf_cloud_data_fusion_owner" {
project = "sample-project"
dataset_id = google_bigquery_dataset.sf_cloud_data_fusion.dataset_id
role = "roles/bigquery.dataOwner"
member = "user:john_doe@caddi.jp"
}
resource "google_bigquery_dataset_iam_member" "data_fusion_editor" {
project = "sample-project"
dataset_id = google_bigquery_dataset.sf_cloud_data_fusion.dataset_id
role = "roles/bigquery.dataEditor"
member = "serviceAccount:${google_service_account.sa_for_data_fusion.email}"
}
説明
いくつかCloud Data Fusionを定義する上でのポイントをかいつまんで説明します。
Service Account
図2をみるとわかる通り、Pipelineの実行時にはCloud Data FusionはSalesforceに接続しておらず、DataprocがSalesforceに接続して必要なデータの取得を行なっています。
Cloud Data Fusionのリソース定義を行う際にDataprocで利用するService Accountは宣言することができるのですが、Cloud Data Fusion自体が利用するService Accountは宣言することができません。
resource "google_data_fusion_instance" "create_instance" {
name = "data-fusion-instance-name"
description = "data-fusion-instance-description"
region = "asia-northeast1"
type = "DEVELOPER"
enable_stackdriver_logging = true
enable_stackdriver_monitoring = true
private_instance = true
dataproc_service_account = google_service_account.sa_for_data_fusion.email
network_config {
network = "sample-private-network"
ip_allocation = "FILL_YOUR_IP_RANGE_OF_DATAFUSION_INSTANCE"
}
version = "6.9.1"
}
Cloud Data Fusion自体が利用するService AccountはCloud Data Fusion APIを有効化した際に作成される、Google Managed Service Accountになるので、Cloud Data Fusion自体が行う操作に対して追加で権限を付与する必要がある場合には、このGoogle Managed Service Accountに対して権限を付与してやる必要があります。(参考:Cloud Data Fusion でのサービス アカウント )
例えば、Pipeline作成時に別プロジェクトにあるBigQueryテーブルを確認しに行くためには、自身で定義したSerivce Accountではなく、Google Managed Service Accountに対して必要なロールを付与する必要があります。
プライベートインスタンスからインターネット上のリソースへの接続
Cloud Data Fusionのインスタンスを作成した後に、パイプラインの作成が行われるのですが、その際にSalesforce(インターネット上に存在するデータソース)に接続し、Salesforce上のスキーマ情報を取得する必要があります。プライベートインスタンスからパブリックソースへの接続 のドキュメントを読むと、プライベートインスタンスからインターネット上に存在するデータソースに接続するためには、Network Peeringを設定し、Gateway VMやFirewall Ruleなども設定し、Cloud Data Fusionインスタンスが外部に接続することができる状態を作る必要があることがわかります。
しかし、一度パイプラインを作成した後、Dataprocのプロビジョニングを行う際には既にCloud Data FusionインスタンスがSalesforceのスキーマ情報など必要な情報を保有しているため、再度インターネット上に存在するデータソースに接続する必要がありません。そのためパイプラインの編集を頻繁には行わない場合などには、パイプラインのデプロイ後、Network Peering, Gateway VM, Firewall Rule, Routeなど、インターネット上に存在するデータソースにCloud Data Fusionプライベートインスタンスが接続するために必要なリソースは削除することが可能です。
ただしこれらのリソースの削除にはメリットデメリットが存在するので、用途に応じて削除するかどうかの判断が必要です。
メリット
デメリット
- 外部サービス(弊社の例ではSalesforce)の最新スキーマを取得できなくなる。取得するためには再度これらのリソースを構築し直す必要がある。
弊社の場合、Salesforceの更新頻度が低い且つIaCでリソースを管理しており再構築が容易に可能という状況だったため、これらのリソースを削除するという選択を行いました。
Cloud Data Fusion インスタンスとパイプラインの作成タイミング
Cloud Data Fusionインスタンスの作成には30分ほど時間がかかります。パイプラインの作成はCloud Data Fusionインスタンスが存在してはじめて可能になるため、Cloud Data Fusionインスタンスの作成が完了するまでパイプライン作成は待つ必要があります。そこで、wait_healty moduleを利用することでCloud Data Fusionインスタンスの作成を待ってパイプラインの作成に移ることが可能になります。
パイプラインの定義方法
パイプラインを定義する際に path/to/file/sf-bq-sync-user-cdap-data-pipeline.jsonで参照しているファイルは、以下のようなJSONファイルを参照しています。
resource "cdap_application" "sf-bq-sync-user" {
name = "sf-bq-sync-user"
spec = templatefile("sf-bq-sync-user-cdap-data-pipeline.json", { consumer_key = data.google_kms_secret.salesforce_consumer_key.plaintext, consumer_secret = data.google_kms_secret.salesforce_consumer_secret.plaintext, username = data.google_kms_secret.salesforce_username.plaintext, password = data.google_kms_secret.salesforce_password.plaintext })
depends_on = [google_data_fusion_instance.create_instance, cdap_local_artifact.salesforce-plugins]
}
sf-bq-sync-user-cdap-data-pipeline.json
{
"name": "sf-bq-sync-user",
"description": "Data Pipeline Application",
"artifact": {
"name": "cdap-data-pipeline",
"version": "6.9.1",
"scope": "SYSTEM"
},
"config": {
"resources": {
"memoryMB": 2048,
"virtualCores": 1
},
"driverResources": {
"memoryMB": 2048,
"virtualCores": 1
},
"connections": [
{
"from": "Salesforce",
"to": "BigQuery"
}
],
"comments": [],
"postActions": [],
"properties": {},
"processTimingEnabled": true,
"stageLoggingEnabled": false,
"stages": [
{
"name": "Salesforce",
"plugin": {
"name": "Salesforce",
"type": "batchsource",
"label": "Salesforce",
"artifact": {
"name": "salesforce-plugins",
"version": "1.6.0",
"scope": "USER"
},
"properties": {
"referenceName": "user",
"useConnection": "false",
"username": "${username}",
"password": "${password}",
"consumerKey": "${consumer_key},
"consumerSecret": "${consumer_secret}",
"loginUrl": "https://login.salesforce.com/services/oauth2/token",
"connectTimeout": "30000",
"query": "select\nlastname,\nid,\nname,\ndivision\nfrom user",
"operation": "query",
"enablePKChunk": "false",
"schema": "{\"name\":\"etlSchemaBody\",\"type\":\"record\",\"fields\":[{\"name\":\"lastname\",\"type\":[\"string\",\"null\"]},{\"name\":\"id\",\"type\":[\"string\",\"null\"]},{\"name\":\"name\",\"type\":[\"string\",\"null\"]},{\"name\":\"division\",\"type\":[\"string\",\"null\"]}]}"
}
},
"outputSchema": "{\"name\":\"etlSchemaBody\",\"type\":\"record\",\"fields\":[{\"name\":\"lastname\",\"type\":[\"string\",\"null\"]},{\"name\":\"id\",\"type\":[\"string\",\"null\"]},{\"name\":\"name\",\"type\":[\"string\",\"null\"]},{\"name\":\"division\",\"type\":[\"string\",\"null\"]}]}",
"id": "Salesforce"
},
{
"name": "BigQuery",
"plugin": {
"name": "BigQueryTable",
"type": "batchsink",
"label": "BigQuery",
"artifact": {
"name": "google-cloud",
"version": "0.22.1",
"scope": "SYSTEM"
},
"properties": {
"useConnection": "false",
"project": "sample-project",
"datasetProject": "sample-project",
"serviceAccountType": "filePath",
"serviceFilePath": "auto-detect",
"dataset": "sf_cloud_data_fusion",
"table": "user",
"operation": "upsert",
"relationTableKey": "id",
"allowSchemaRelaxation": "false",
"location": "asia-northeast1",
"createPartitionedTable": "false",
"partitioningType": "NONE",
"schema": "{\"name\":\"etlSchemaBody\",\"type\":\"record\",\"fields\":[{\"name\":\"lastname\",\"type\":[\"string\",\"null\"]},{\"name\":\"id\",\"type\":[\"string\",\"null\"]},{\"name\":\"name\",\"type\":[\"string\",\"null\"]},{\"name\":\"division\",\"type\":[\"string\",\"null\"]}]}"
}
},
"outputSchema": "{\"name\":\"etlSchemaBody\",\"type\":\"record\",\"fields\":[{\"name\":\"lastname\",\"type\":[\"string\",\"null\"]},{\"name\":\"id\",\"type\":[\"string\",\"null\"]},{\"name\":\"name\",\"type\":[\"string\",\"null\"]},{\"name\":\"division\",\"type\":[\"string\",\"null\"]}]}",
"inputSchema": [
{
"name": "Salesforce",
"schema": "{\"name\":\"etlSchemaBody\",\"type\":\"record\",\"fields\":[{\"name\":\"lastname\",\"type\":[\"string\",\"null\"]},{\"name\":\"id\",\"type\":[\"string\",\"null\"]},{\"name\":\"name\",\"type\":[\"string\",\"null\"]},{\"name\":\"division\",\"type\":[\"string\",\"null\"]}]}"
}
],
"id": "BigQuery"
}
],
"schedule": "0 */2 * * *",
"engine": "spark",
"numOfRecordsPreview": 100,
"rangeRecordsPreview": {
"min": 1,
"max": "5000"
},
"description": "Data Pipeline Application",
"maxConcurrentRuns": 1
},
"version": "de67b401-29e2-11ee-9d6b-7ad3ba276e43"
}
このJSONファイルを1から手で書くのは骨が折れますが、Cloud Data FusionではUIから定義したパイプラインの設定をパイプラインのページからExportし、利用することが可能です。
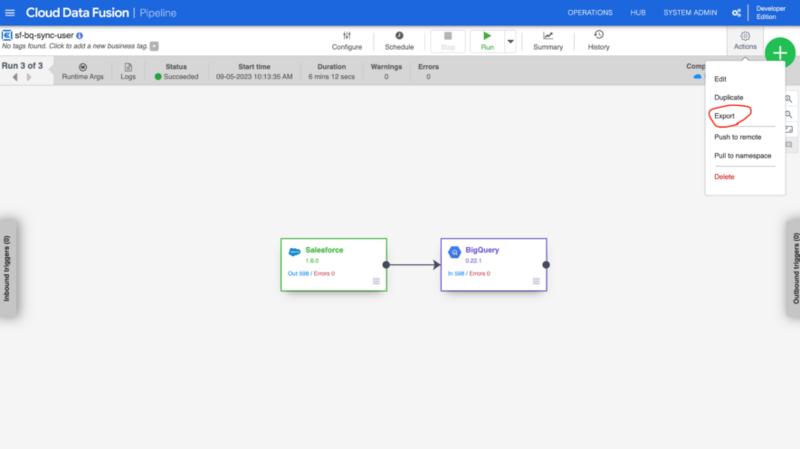
そのため、1番最初はUIからパイプラインの定義を行い、exportしたJSONファイルを雛形として利用し、必要に応じて編集しながら使うのが効率的かと思います。その際に、secretの扱いを気をつける必要があります。
設定をexportすると、JSONファイルの中に以下passwordやconsumerSecretなどの情報が直接入ってきます。これらをGitHubなどにPushしてしまうとまずいため、templatefile function を利用して、Secret Managerなどから取得したsecretに置き換えてやる必要があります。JSONファイル内で "password": "${password}",と書いて変数を埋め込み、パイプラインの定義を行う際に以下のようにtemplatefile functionを利用してsecretに置き換えます。
resource "cdap_application" "sf-bq-sync-user" {
name = "sf-bq-sync-user"
spec = templatefile("sf-bq-sync-user-cdap-data-pipeline.json", { consumer_key = data.google_kms_secret.salesforce_consumer_key.plaintext, consumer_secret = data.google_kms_secret.salesforce_consumer_secret.plaintext, username = data.google_kms_secret.salesforce_username.plaintext, password = data.google_kms_secret.salesforce_password.plaintext })
depends_on = [google_data_fusion_instance.create_instance, cdap_local_artifact.salesforce-plugins]
}
スキーマの更新
スキーマの更新の際にはJSONファイルを編集する必要があります。変更内容が多い場合でも、置換をうまく使えば作業自体はそこまで大変ではないので、Heroku ConnectでUIから管理していた時よりも個人的には作業が楽になったように感じます。また、JSONファイルもGit管理下に置かれるので、変更前後のDiffが見られる安心感もメリットに感じています。
Salesforce側の設定
Cloud Data Fusionを利用してSalesforceのデータを取得するためには、Salesforce側の設定も必要になります。Salesforceの設定はClassmethodさんの記事「Cloud Data FusionでSalesforceのデータをBigQueryに取り込んでみる」を参考にさせていただきました。
困っている点
パイプラインの定期実行スケジュールのトリガー方法
パイプラインのデプロイまではIaCで自動化することができたのですが、パイプラインの定期実行スケジュールをデプロイと同時に開始することができず、スケジュールの開始だけはUIから操作する必要があります。UIから定期実行を開始したのちに、google_data_fusion_instance に対してterraform import&terramform plan を実行しても差分が出ず、また、pipelineを作成しているcdap_applicationは terraform importをサポートしておらず、定期実行のスケジュールを開始する方法は見つけられておりません。
おわりに
お決まりですが採用についてです。リアルな世界に向き合い複雑なドメインを取り扱うことに興味がある方、検証を回しつつ、スケールするための基盤作りに興味がある方を募集しています。カジュアル面談もやっていますのでぜひお気軽にご連絡ください。
エンジニア向け採用サイト https://recruit.caddi.tech/ 求人一覧 https://open.talentio.com/r/1/c/caddi-jp-recruit/homes/4139
参考文献