
この記事はBASE Advent Calendar 2020の21日目の記事です。
はじめに
お久しぶりです。BASEビール部部長(兼Data Strategyチーム)のbokenekoです。 今年はほんと辛い1年でしたね。コロナで全くビール部の活動ができませんでした。 その反動で通販でクラフトビール買いまくって冷蔵庫が溢れました。定期便の利用は計画的に。
と、まあそんな私生活はおいておいて、今日はData Strategyチームでのリコメンドにおける取り組みについてお話しします。
BASEでは、ネットショップ作成サービス「BASE」で開設された130万のショップが集まる購入者向けのショッピングアプリ「BASE」を提供しています。アプリでは商品やショップのおすすめを表示していますが、ここに使われているリコメンドのアルゴリズムは実は複数アルゴリズムの組み合わせになっています。例えば協調フィルタリングやFactorization Machinesなどです。今回はそこにさらにGraph Neural Networkによるリコメンドを追加しようとしているというお話をしようと思います。
Graph Neural Networkとは
Graph Neural Network(GNN)は2017年頃から話題がでてきた、Deep Learningでグラフ構造を扱う手法のことです。GNNでは大まかに以下のような問題を解くことができます。
- Node classification/regression
- ノードの分類やノードが持つ値の推定
- Link prediction
- 二つのノード間に特定のエッジが存在するかどうかを予測
- Graph classification/regression
- グラフ自体の分類やグラフに関連する数値の推定
GNNのリコメンドへの応用
Link Prediciton
Link Predictionはグラフ上のあるノードとノードの間にエッジが存在するか否かを推測する問題です。現在観測されているグラフ構造から、まだ観測されていないエッジが存在しているかどうかを推測します。
今回のリコメンドで言えばユーザーノードと商品ノードを購入エッジで繋いだグラフがあったとして、今はまだないあるユーザーと商品の間の購入エッジが存在しうるかどうか、つまりまだ買ってないけど買ってくれる可能性が高いかどうかを推測します。
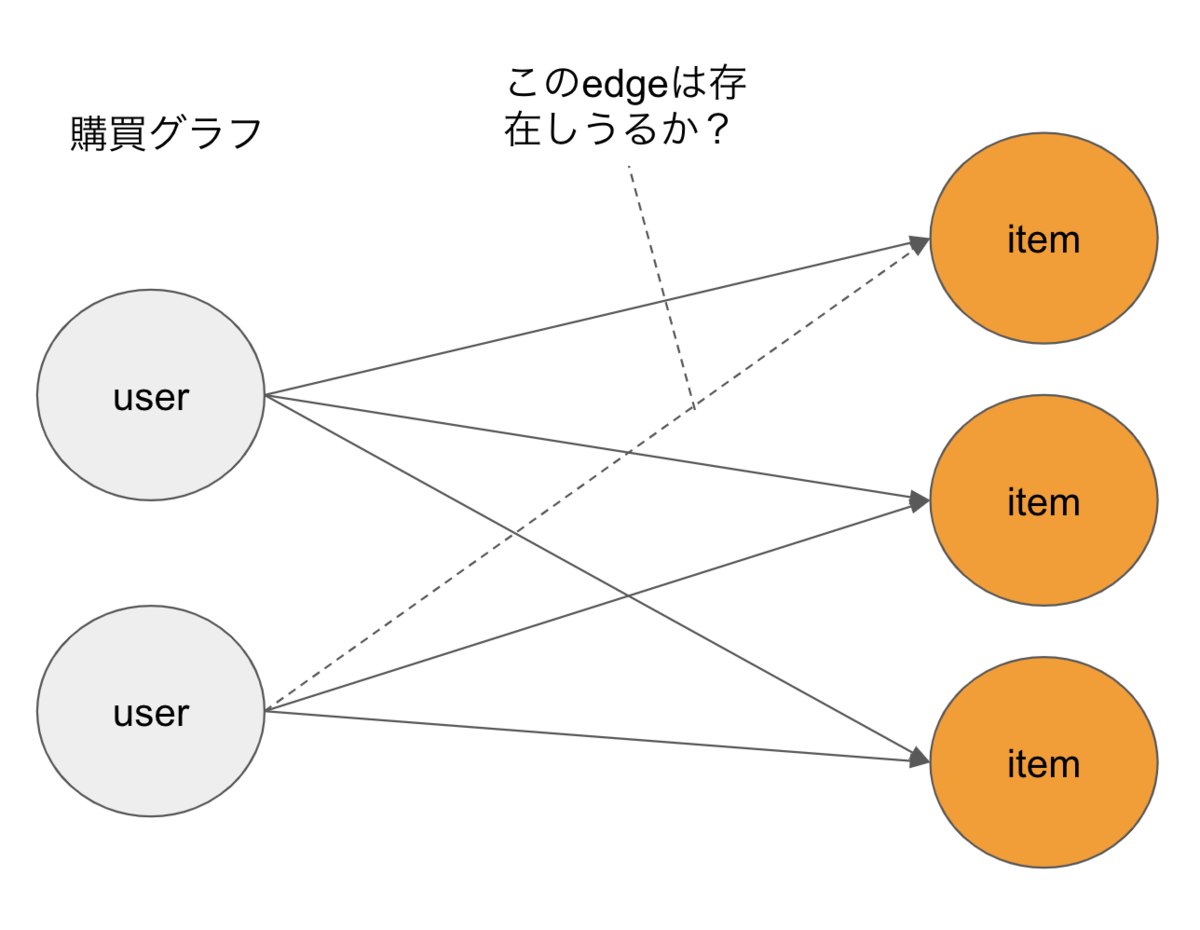
グラフ構造
購入エッジの存在を予測するにあたって、利用したデータは以下の通りです
- ユーザーがどの商品を購入したか
- ユーザーがどの商品をお気に入りしたか
- ユーザーがどのショップをフォローしたか
- どのショップがどの商品を販売しているか
これらの情報をユーザー・商品・ショップを繋ぐグラフ構造にします。
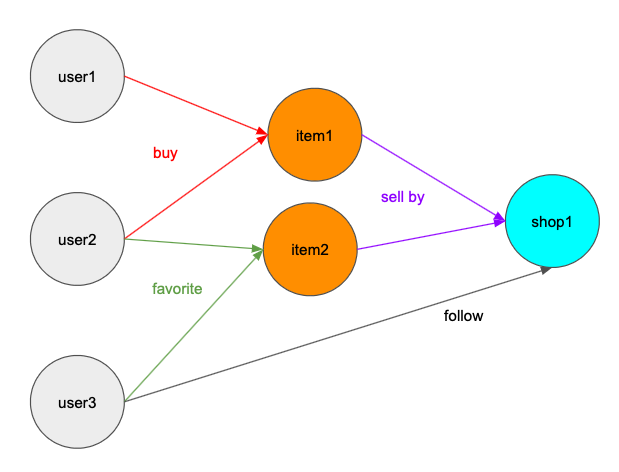
このグラフでbuyエッジがあるユーザーと商品の間にあるかどうかを予測するのが目的になります。 (ちなみにこうしたノード・エッジが複数種類あるグラフのことをheterogeneous graphと呼びます。)
モデル
今回採用したモデルはR-GCNというモデルです。
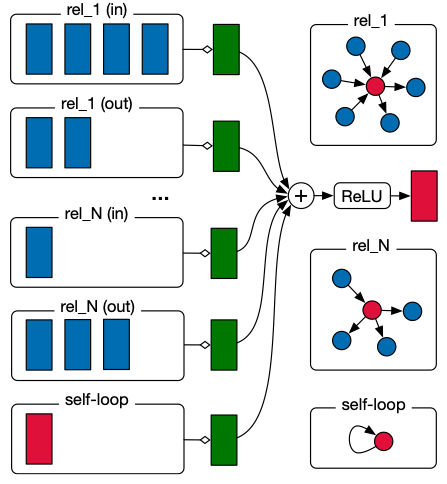
R-GCNはあるノードについて、そのノードに出入りしている各エッジ種ごとにGCNを行いそれをまとめるという方法でグラフを畳み込みます。これで計算されたユーザーと商品の特徴量に対して購買エッジが存在するかを分類問題として解きます。 GCNは通常のDNNでいうところのCNNのようなものをイメージしていただければよいです。
実装
処理の手順は以下のようになります。
- 各ノードに対してノード種毎にIDを振ってグラフを作成
- グラフをR-GCNに通して各ノードの特徴量を計算
- ユーザーと商品の間にあるリンクが存在するかを二値分類問題として解く
グラフ作成
グラフは双方向グラフとして作成しています。
import torch import dgl # buy c2i_buy = torch.tensor([(customer_node_id, item_node_id), ...]) # fav c2i_fav = torch.tensor([(customer_node_id, item_node_id), ...]) # follow c2s_follow = torch.tensor([(customer_node_id, shop_node_id), ...]) # sell s2i = torch.tensor([(shop_node_id, item_node_id), ...]) graph_data = { ("customer", "buy", "item"): (c2i_buy[:, 0], c2i_buy[:, 1]), ("item", "bought-by", "customer"): (c2i_buy[:, 1], c2i_buy[:, 0]), ("customer", "fav", "item"): (c2i_fav[:, 0], c2i_fav[:, 1]), ("item", "fav-by", "customer"): (c2i_fav[:, 1], c2i_fav[:, 0]), ("customer", "follow", "shop"): (c2s_follow[:, 0], c2s_follow[:, 1]), ("shop", "follow-by", "customer"): (c2s_follow[:, 1], c2s_follow[:, 0]), ("customer", "buy-from", "shop"): (c2s_buy[:, 0], c2s_buy[:, 1]), ("shop", "sell-to", "customer"): (c2s_buy[:, 1], c2s_buy[:, 0]), ("shop", "sell", "item"): (s2i[:, 0], s2i[:, 1]), ("item", "selled-by", "shop"): (s2i[:, 1], s2i[:, 0]), } g = dgl.heterograph(graph_data)
training
import torch model = RelationPredict(g, 64, 16) opt = torch.optim.Adam(model.parameters(), lr=0.01) model.train() for epoch in range(60): opt.zero_grad() # グラフから各ノードの特徴量を計算 embed = model(g) labels = torch.zeros(10000, dtype=torch.long) # グラフには取り込んでないが存在する購買エッジをpositive sampleとして利用 pos_s = [] pos_d = [] random.shuffle(c2i_buy_train) for c, i in c2i_buy_train[:5000]: pos_s.append(c) pos_d.append(i) pos_s = torch.tensor(pos_s) pos_d = torch.tensor(pos_d) labels[:5000] = 1 # ランダムに取り出したユーザー・商品の組をnegative sampleとして利用 # 全組み合わせのうち本当に存在してるエッジは無視できるほど少ないので問題はず neg_s = torch.randint(g.number_of_nodes("customer"), (5000,)) neg_d = torch.randint(g.number_of_nodes("item"), (5000,)) train_data = { "srcs": torch.cat([pos_s, neg_s]), "dsts": torch.cat([pos_d, neg_d]), "labels": labels } loss = model.get_loss(embed, train_data) loss.backward() opt.step()
モデル全体
import torch import torch.nn as nn import torch.nn.functional as F import dgl import dgl.nn as dglnn class RelGraphConvLayer(nn.Module): """ R-GCN layer """ def __init__(self, in_feat, out_feat, rel_names, bias=True, activation=None, self_loop=False, dropout=0.0): super(RelGraphConvLayer, self).__init__() self.in_feat = in_feat self.out_feat = out_feat self.rel_names = rel_names self.bias = bias self.activation = activation self.self_loop = self_loop self.conv = dglnn.HeteroGraphConv({ rel : dglnn.GraphConv(in_feat, out_feat, norm='right', weight=False, bias=False) for rel in rel_names }, aggregate='sum') self.weight = nn.ParameterDict() for rel_name in rel_names: weight = nn.Parameter(torch.Tensor(in_feat, out_feat)) nn.init.xavier_uniform_(weight, gain=nn.init.calculate_gain('relu')) self.weight[rel_name] = weight # bias if bias: self.h_bias = nn.Parameter(torch.Tensor(out_feat)) nn.init.zeros_(self.h_bias) # weight for self loop if self.self_loop: self.loop_weight = nn.Parameter(torch.Tensor(in_feat, out_feat)) nn.init.xavier_uniform_(self.loop_weight, gain=nn.init.calculate_gain('relu')) self.dropout = nn.Dropout(dropout) def forward(self, g, inputs): g = g.local_var() wdict = {} for rel_name in self.rel_names: wdict[rel_name] = { "weight": self.weight[rel_name] } hs = self.conv(g, inputs, mod_kwargs=wdict) def _apply(ntype, h): if self.self_loop: h = h + torch.matmul(inputs[ntype], self.loop_weight) if self.bias: h = h + self.h_bias if self.activation: h = self.activation(h) return self.dropout(h) return {ntype : _apply(ntype, h) for ntype, h in hs.items()} class RelGraphEmbed(nn.Module): """ node embeding layer node_id -> node embeding """ def __init__(self, g, embed_size): super(RelGraphEmbed, self).__init__() self.g = g self.embed_size = embed_size # create weight embeddings for each node for each relation self.embeds = nn.ParameterDict() for ntype in g.ntypes: embed = nn.Parameter(torch.Tensor(g.number_of_nodes(ntype), self.embed_size)) nn.init.xavier_uniform_(embed, gain=nn.init.calculate_gain('relu')) self.embeds[ntype] = embed def forward(self): return self.embeds class RelationPredict(nn.Module): def __init__(self, g, h_dim, out_dim, num_hidden_layers=1, dropout=0.5, use_self_loop=True): super(RelationPredict, self).__init__() self.h_dim = h_dim self.out_dim = out_dim self.rel_names = list(set(g.etypes)) self.rel_names.sort() self.num_hidden_layers = num_hidden_layers self.dropout = dropout self.use_self_loop = use_self_loop self.embed_layer = RelGraphEmbed(g, self.h_dim) self.layers = nn.ModuleList() # i2h self.layers.append(RelGraphConvLayer( self.h_dim, self.h_dim, self.rel_names, activation=F.relu, self_loop=self.use_self_loop, dropout=self.dropout)) # h2h for i in range(self.num_hidden_layers): self.layers.append(RelGraphConvLayer( self.h_dim, self.h_dim, self.rel_names, activation=F.relu, self_loop=self.use_self_loop, dropout=self.dropout)) # h2o self.layers.append(RelGraphConvLayer( self.h_dim, self.out_dim, self.rel_names, activation=None, self_loop=self.use_self_loop)) # score self.fc1 = nn.Linear(self.out_dim*2, self.out_dim) self.act1 = nn.ReLU() self.fc2 = nn.Linear(self.out_dim, 1) self.act2 = nn.Sigmoid() def calc_score(self, h, srcs, dsts, src_type="customer", dst_type="item"): s = h[src_type][srcs] d = h[dst_type][dsts] x = torch.cat([s, d], dim=1) x = self.act1(self.fc1(x)) x = self.act2(self.fc2(x)).view(-1) return x def forward(self, g): h = self.embed_layer() for layer in self.layers: h = layer(g, h) return h def get_loss(self, h, train_data): srcs = train_data["srcs"] dsts = train_data["dsts"] labels = train_data["labels"] score = self.calc_score(h, srcs, dsts) predict_loss = F.binary_cross_entropy_with_logits(score, labels) return predict_loss
結果
直近90日分の売り上げ・お気に入り商品・フォローショップのデータを用いて、売り上げの80%をグラフに取り込み、残りの18%を教師データ、2%をテストデータとして試験したところ、テストデータでは以下のような結果になりました。
accuracy: 0.891 recall: 0.858 specificity: 0.925 precision: 0.920
もちろんここでの成績が直ちにユーザーの満足度につながるわけではないのですが、数値的にはかなり優秀なんではないでしょうか。
最後に
このモデルは現在開発環境で試験中で、問題なければ来年頭にはアプリのリコメンドに組み込まれる予定です。
GNNはグラフ構造にならば何にでも適用できますので是非皆さんがお持ちのデータでも試していただけると。
明日は、フロントエンドチームの青木さんです。お楽しみに。
もしBASEで働くことに興味を持っていただけた方は、ぜひご連絡ください。
最後の最後に
なんかre:InventでNeptune MLとかいうの出てましたね。NeptuneでGNNできるんですね。もうちょっとさあ、早くだして欲しかったなぁ。