

この記事は約8分で読めます。
この記事は1年以上前に書かれたものです。
内容が古い可能性がありますのでご注意ください。
 こんにちは。CS課の坂本(@t_sakam)です。
こんにちは。CS課の坂本(@t_sakam)です。
タイトルは違いますが、前回の続きです。【そんなときどうする?】シリーズ、今回は第5回目になります。
前回までの記事
- 【そんなときどうする?】CloudWatchのデータを2週間以上残したい!
- 【そんなときどうする?】CloudWatchのデータを2週間以上残したい! Lambda編
- 【そんなときどうする?】別のアカウントにセキュアにアクセスしたい! いまさらきけないSTSとは?
- 【そんなときどうする?】DynamoDBのデータを可視化したい! LambdaのBlueprintを使って、Elasticsearch Serviceと簡単連携
これまでの手順で、CloudWatchのデータをDynamoDBに入れつつ、Elasticsearch Serviceで可視化することができました。
最初はEC2でcron実行していたスクリプトをLambdaで実行するようにし、 前回もDynamoDBのデータをElasticsearch Serviceで可視化するときにLambdaを使いました。
ということで、Lambdaを使う機会が増えて日々Lambdaの便利さを実感していますが、マネジメントコンソール上でコードを修正したり、zipファイルでコードをアップロードしたりと、一般的ではない開発方法やデプロイ方法に少し頭を悩ませはじめました。
「何かいい方法はないかなー」と思っていたところ、ちょうど先日のAWS SummitのLambdaのセッションで「Lambdaでの開発を便利にするフレームワーク」の紹介があったので、試してみることにしました。 紹介があったのは「Serverless Framework」と「Flourish」ですが、「Flourish」の方は「coming soon」ということでまだ全貌がわかりません。
今回は「Serverless Framework」を使って、前回のLambdaの箇所を構築したいと思います。
- 「Serverless Framework」のインストール
- プロジェクトの作成
- CloudFormationのマネジメントコンソールで実行履歴を確認
- CloudFormationで自動生成されたポリシーの変更
- Lambdaファンクションの作成
- CloudWatchの値をDynamoDBにINSERTするLambdaファンクションの実行
- まとめ
<a name="development_in_lambda_01"></a>
1. 「Serverless Framework」のインストール
| OS | OS X |
| Python | 2.7.10 |
| aws-cli | aws-cli/1.10.36 |
| npm | 2.15.5 |
以下のコマンドで「Serverless Framework」をローカル環境にインストールします。
sudo npm install serverless -g
バージョンの確認ができれば、インストールは成功です。
serverless --version 0.5.5
<a name="development_in_lambda_02"></a>
2. プロジェクトの作成
1. プロジェクトの作成
インストールできたら、次はプロジェクトを作成します。
serverless project create
以下のような形で、対話的にプロジェクトを作成していきます。質問される内容に順番に答えていきましょう。
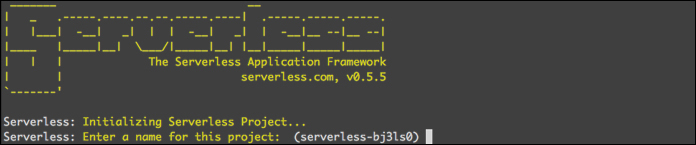
今回はプロジェクト名を「project」、ステージはデフォルトのまま「dev」にしました。プロフィールは「Create A New Profile」を選択します。
「Create A New Profile」を選択するとアクセスキーとシークレットアクセスキーの入力が求められるので、入力します。 キーの情報を保存するプロフィールの名前、利用するリージョンの選択をし、設定を確定させるとCloudFormationでの構築がスタートします。「〜3分」と表示されているので、少し待ちます。

しばらく待つと完成します。以下のメッセージが表示されたら成功です。
Serverless: Successfully deployed "dev" resources to "ap-northeast-1" Serverless: Successfully created region "ap-northeast-1" within stage "dev" Serverless: Successfully created stage "dev" Serverless: Successfully initialized project "project"
2. プロジェクトの確認
ローカル環境に生成された「project」ディレクトリの下には、以下のディレクトリとファイルが作成されています。
s-project.json
s-resources-cf.json
admin.env
_meta
|__resources
|__s-resources-cf-dev-apnortheast1.json
|__variables
|__s-variables-common.json
|__s-variables-dev.json
|__s-variables-dev-apnortheast1.json
<a name="development_in_lambda_03"></a>
3. CloudFormationのマネジメントコンソールで実行履歴を確認
CloudFormationのマネジメントコンソールで実行履歴を確認してみます。

詳細を確認すると、「IAM Role」と「IAM Policy」が作成されています。

IAMのマネジメントコンソールで作成されたロールとポリシーを確認してみます。 「project-dev-r-IamRoleLambda-XXXXXXXXXXXXX」というロールが作成され、そのロールに「dev-project-lambda」というポリシーがあたっています。「dev-project-lambda」ポリシーを確認します。
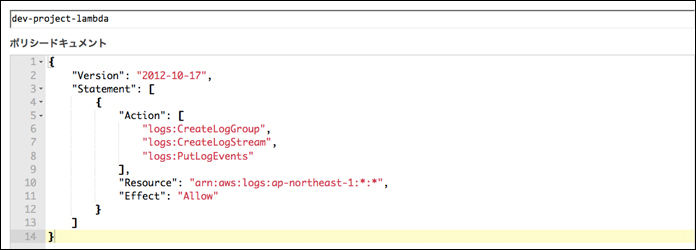
上記が自動で作成された「dev-project-lambda」ポリシーです。自動で作成されたポリシーだと今回必要な権限が足りません。設定することは前回と同じなので、前回作成した「LambdaDynamoStreamRole」の中身を参考に権限を足します。
<a name="development_in_lambda_04"></a>
4. CloudFormationで自動生成されたポリシーの変更
1. ポリシーの変更
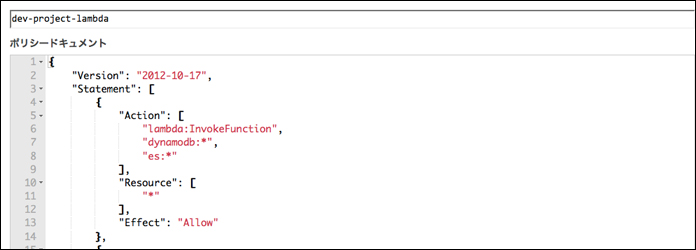
「Serverless Framework」ではポリシーの設定は「s-resources-cf.json」ファイルの中身を変更して、デプロイすることで設定します。 まずは、「s-resources-cf.json」ファイルの37行目から39行目にLambdaのInvokeFunction、DynamoDB、Elasticsearch Serviceの権限を追加します。
33 "Statement": [
34 {
35 "Effect": "Allow",
36 "Action": [
37 "lambda:InvokeFunction",
38 "dynamodb:*",
39 "es:*"
40 ],
2. 変更したポリシーの設定をデプロイ
ファイルの編集がおわったら、以下のコマンドを打って設定をデプロイして反映させます。
serverless resources deploy
「〜3分」と表示されているので、少し待ちます。
Serverless: Deploying resources to stage "dev" in region "ap-northeast-1" via Cloudformation (~3 minutes)...
以下の結果が返ってきたら成功です。
Serverless: Successfully deployed "dev" resources to "ap-northeast-1"
IAMのマネジメントコンソールで確認すると、設定が反映されています。
<a name="development_in_lambda_05"></a>
5. Lambdaファンクションの作成
1. Lambdaファンクション作成コマンド実行
プロジェクトの作成がおわったので、次はLambdaファンクションを作成します。
以下のコマンドを実行します。ファンクション名は「dynamodb-to-elasticsearch」とします。
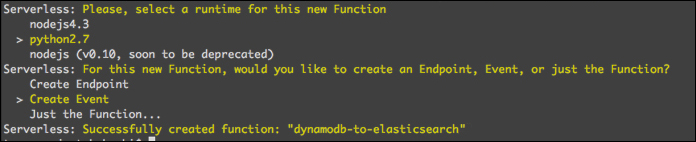
serverless function create functions/dynamodb-to-elasticsearch
Lambdaファンクションも以下のような形で、対話的に作成していきます。今回も言語はPythonを選択しました。 ファンクションの種類を選ぶ箇所がでてきますが、今回はDynamoDBのイベントベースで実行するので、「Create Event」を選択します。
他の選択肢についても少し触れておきます。「Create Endpoint」は、API Gatwayのエンドポイントを使うような処理のときに選び、「Just the Function」は、普通にLambdaファンクションだけを作成したいときに選びます。
Lambdaファンクション用のディレクトリとファイルが作成されました。
functions
|__dynamodb-to-elasticsearch
|__event.json
|__handler.py
|__s-function.json
2. 設定ファイル、「s-function.json」の編集
まずは、「s-function.json」を編集します。7行目の「handler」の設定はファイル名、ファンクション名の指定なので、デフォルトの「"handler.handler"」のままにしておきます。 他は前回の設定と同じ設定になるように変更していきます。8行目の「timeout」を「60」、9行目の 「memorySize」は「384」にします。
| { | |
| "name": "dynamodb-to-elasticsearch", | |
| "runtime": "python2.7", | |
| "description": "Serverless Lambda function for project: project", | |
| "customName": false, | |
| "customRole": false, | |
| "handler": "handler.handler", | |
| "timeout": 60, | |
| "memorySize": 384, | |
| "authorizer": {}, | |
| "custom": { | |
| "excludePatterns": [] | |
| }, | |
| "endpoints": [], | |
| "events": [ | |
| { | |
| "name": "dynamoevents", | |
| "type": "dynamodbstream", | |
| "config": { | |
| "streamArn": "arn:aws:dynamodb:ap-northeast-1:XXXXXXXXXXXX:table/ec2_cpuutilization_es/stream/XXXX-XX-XXXXX:XX:XX.XXX", | |
| "startingPosition": "TRIM_HORIZON", | |
| "batchSize": 100, | |
| "enabled": true | |
| } | |
| } | |
| ], | |
| "environment": { | |
| "SERVERLESS_PROJECT": "${project}", | |
| "SERVERLESS_STAGE": "${stage}", | |
| "SERVERLESS_REGION": "${region}" | |
| }, | |
| "vpc": { | |
| "securityGroupIds": [], | |
| "subnetIds": [] | |
| } | |
| } |
15行目からの「events」の設定がDynamoDBのイベント設定です。今回は名前を「dynamoevents」としておきます。 「type」はイベントタイプを指定する箇所なので、「dynamodbstream」にします。デフォルトでは「type」は「schedule」となっていて、スケジュールイベントの設定になっています。
「streamArn」は前回の作業で作成されている「ストリームARN」を設定します。DynamoDBのマネジメントコンソールの「ec2_cpuutilization_es」テーブルの「概要」-「ストリームの詳細」で確認して設定します。

「startingPosition」、「batchSize」は、前回と同じでそれぞれ「TRIM_HORIZON」、「100」としておきます。
「enabled」を「true」にしてLambdaファンクションを有効化します。他はデフォルトのままにしてファイルを保存しておきます。
3. Lambdaファンクション、「handler.py」の編集
次は「handler.py」を書き換えます。Lambdaのマネジメントコンソールにある前回のコードをコピーしてきてペーストします。そのときに121行目の「lambda_handler」となっているところだけ「handler」と書き換えて、先ほどの「s-function.json」ファイルで指定したファンクション名と合わせます。
121 def handler(event, context):
これで、準備ができました。次はデプロイをおこないます。
以下のコマンドでデプロイします。こちらも対話的に処理していきます。
serverless dash deploy

今回は、デプロイ初回なので、ファンクションとイベントの両方を選んでから「Deploy」を選択して実行します。どちらかを修正後にデプロイをおこないたい場合は、ここで修正した方を選択してデプロイします。
以下のメッセージが返ってきたら成功です。
Serverless: Deploying the specified functions in "dev" to the following regions: ap-northeast-1 Serverless: ------------------------ Serverless: Successfully deployed the following functions in "dev" to the following regions: Serverless: ap-northeast-1 ------------------------ Serverless: dynamodb-to-elasticsearch (serverless-dynamo-es-dynamodb-to-elasticsearch): arn:aws:lambda:ap-northeast-1:XXXXXXXXXXXX:function:serverless-dynamo-es-dynamodb-to-elasticsearch:dev Serverless: Deploying events in "dev" to the following regions: ap-northeast-1 Serverless: Successfully deployed events in "dev" to the following regions: Serverless: ap-northeast-1 ------------------------ Serverless: dynamodbstream (dynamodbstream event)
Lambdaのマネジメントコンソールでもデプロイできていることを確認しておきます。
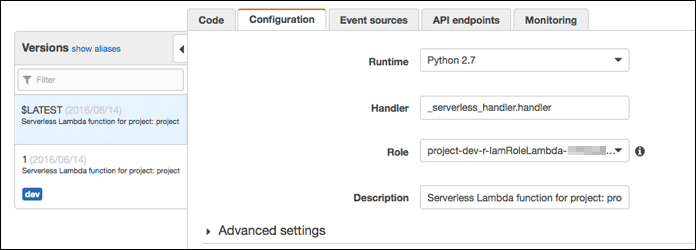
<a name="development_in_lambda_06"></a>
6. CloudWatchの値をDynamoDBにINSERTするLambdaファンクションの実行
設定できているかを確認するために、CloudWatchの値をDynamoDBへ入れます。
前回修正したLambdaファンクションをマネジメントコンソールでテスト実行します。

テスト実行後、DynamoDBのマネジメントコンソールでみてみると、データが入っていることが確認できます。
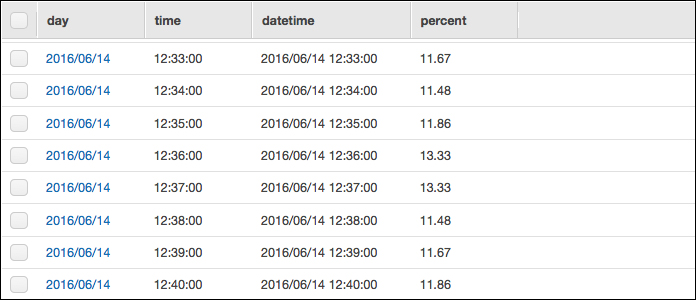
更にElasticsearch Serviceのマネジメントコンソールで確認します。Countの箇所がLambdaのテスト実行後、60になって、問題なくデータがElasticsearch Serviceにも取り込めたことが確認できました。 ※前回入れた値を削除して0に戻してから実行しています。
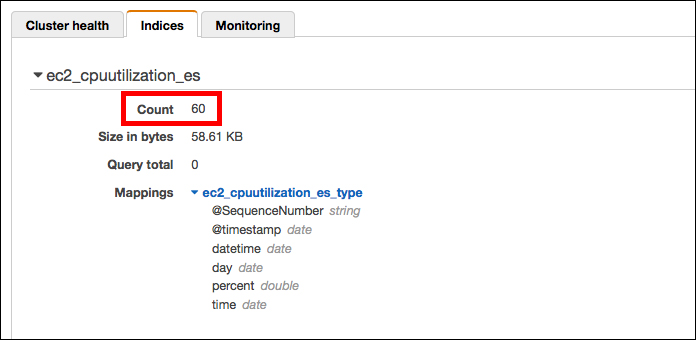
<a name="development_in_lambda_07"></a>
7. まとめ
今回は「Serverless Framework」を使って、前回と同じ状態にまでもっていくことができました。
初回の準備なので、前回よりも手順は増えましたが、今後コードを修正していくときは、マネジメントコンソール上で、修正したり、zipファイルをアップロードしなくてもよくなりました。
今回は「dev」ステージへのデプロイでしたが、「prod」ステージを作ることで、開発環境と本番環境をわけることもできそうです。まだ全部の機能を試せていませんが、今回の手順をみるだけでも「Serverless Framework」を使うことで、Lambdaでの開発がいままでよりも楽になりそうな気がしますよね。
さて次回です。まだまだ便利な機能がたくさんありそうな「Serverless Framework」。引き続き「Serverless Framework」で何ができるのかをみてみたいと思います。
いや〜、Serverless Frameworkって本当にいいものですね。