Professional Data Engineer 完全攻略ガイド:データストレージ編



はじめに
こんにちは、クラウドエース 第三開発部の松本です。
普段はデータ基盤や機械学習システムを構築したり、Google Cloud 認定トレーナーとしてトレーニングを提供しています。
今回は、Professional Data Engineer 試験対策ガイドのデータストレージ編として、データ取り込み編に続き、データストレージのプロダクトを中心に試験対策の内容をご紹介します!
尚、前回のデータ取り込み編をまだ見ていない方は、以下をぜひご覧ください。
対象読者
- 試験で問われる Google Cloud のデータストレージプロダクトを効率的に把握したい方
- 試験対策として、データストレージ分野を強化したい方
- Google Cloud データストレージのプロダクトを実務で活用したい方
データストレージプロダクト
Google Cloud における主要なデータストレージプロダクトとして、下表のプロダクトがあります。まずは、各プロダクトの種類(オブジェクトストレージ、データウェアハウス、NoSQL、RDBMS、インメモリ)や特徴、ユースケースを把握しておきましょう!

データストレージプロダクトの比較
また、各プロダクトごとの詳細なポイントを以下に記載しましたので、確認していきましょう!尚、私が考える試験対策としての重要度を各プロダクトごとに記載していますので、学習優先度の参考にしてみてください!
1. Cloud Storage(重要度:★★★★☆)
Cloud Storage は、構造化(CSV など)、半構造化(JSON、XML など)、非構造化(画像、音声、動画など)のあらゆる種類のデータを格納できるオブジェクトストレージサービスです。
まずは以下の特徴を押さえておきましょう。
- (実質的に)無制限のストレージとアクセス: (通常の使用においては実質的に)容量に上限はなく、必要に応じてデータを保存できます。また、誰でもデータへアクセスできます。(必要に応じてアクセス制御も可能です。)
- グローバルなアクセスとストレージ: 世界中のユーザーがデータにアクセスでき、世界各地のロケーションにデータを保存できます。これにより、ユーザーに近い場所へのデータ配置が可能になり、レイテンシの低減に貢献します。
- 低レイテンシ: データ取得時のレイテンシが低く、迅速にデータにアクセスできます。また、常にオンラインでデータにアクセスする設計となっており、オフラインでのデータ取得は発生しません。
- 非常に高い耐久性: 99.999999999 %(イレブンナイン) という非常に高い年間耐久性を誇ります。これは、データが失われる可能性が極めて低いことを意味します。
- リージョン間の冗長性: データをマルチリージョンまたはデュアルリージョンに保存した場合、複数のリージョンにデータが冗長化されるため、特定のリージョンで障害が発生した場合でもデータは保護されます。(マルチリージョン、デュアルリージョンの説明については後述しています。)
また、Cloud Storage は構造化データだけでなく半構造化データや非構造化データを格納できるため、データ分析基盤においてはデータレイクとしてよく使用されます。
その他の重要なポイントを以下に記載していますので、理解しておきましょう!
ストレージクラス
Cloud Storage には、データのアクセス頻度や保存期間に基づいて選択できるストレージクラスがあります。これにより、コストを最適化できます。
| ストレージクラス | 最小保存期間 | アクセス頻度 | ストレージ料金 | オペレーション料金 |
|---|---|---|---|---|
| Standard | なし | 高頻度 | 高 | 低 |
| Nearline | 30 日 | 月に数回 | ↑ | ↓ |
| Coldline | 90 日 | 四半期に数回 | ↑ | ↓ |
| Archive | 365 日 | 数年に一度またはアクセスなし | 低 | 高 |
尚、各ストレージクラスで定められた最小保存期間に達することなくオブジェクトを削除/置換/移動した場合は、最小保存期間分の料金が発生します。詳細は以下の公式ドキュメントをご参照ください。
オブジェクトライフサイクル
オブジェクトライフサイクルを使用すると、オブジェクトの保存期間やストレージクラスの変更を自動化できます。例えば、作成から 30 日後に Standard から Nearline に、さらに 90 日後に Coldline に移動するルールを設定できます。これにより、ストレージコストを自動的に最適化できます。
また、ライフサイクルのルールとして以下のアクションを指定できますので、押さえておきましょう。
- Delete: オブジェクトを削除する。
- SetStorageClass: オブジェクトのストレージクラスを変更する。
- AbortIncompleteMultipartUpload: 未完了のマルチパートアップロードを削除する。
バージョニング
バージョニングを有効にすることで、オブジェクトの過去のバージョンを保持できます。これにより、オブジェクトを誤って削除または上書きした場合でも、以前のバージョンに復元できます。
Autoclass
Autoclass は、アクセスパターンに基づいてストレージクラスを自動的に管理する機能です。手動でストレージクラスを管理する手間を省いたり、コストを最適化したい場合に使用します。
デュアルリージョンとマルチリージョン
Cloud Storage では、データを複数のロケーション(リージョン)に冗長化して保存することで、可用性と耐久性を高めることができます。以下のロケーションタイプの違いについて押さえておきましょう。
| ロケーションタイプ | 特徴 | ストレージ料金 | 書き込み時のレプリケーション料金 | 読み取り時のアウトバウンドのデータ転送料金 |
|---|---|---|---|---|
| マルチリージョン | 複数のリージョンにデータを冗長化でき、広範囲の障害に対する耐性が高い。 | リージョンより高く、デュアルリージョンより低い。 | あり | あり |
| デュアルリージョン | 2 つのリージョンにデータを冗長化。 | 最大(マルチリージョン、リージョンに比べて) | あり | なし |
| リージョン | 特定のリージョンにデータを保存し、特定の地域内でのデータへのアクセスが高速。 | 最小(マルチリージョン、デュアルリージョンに比べて) | なし | (同じリージョン内では)なし |
詳細に関しては、以下の公式ドキュメントをご参照ください。
ターボレプリケーション
デュアルリージョンを使用している場合、通常はオブジェクトが非同期で 2 つのリージョンにレプリケートされますが、レプリケート時間として「1 時間以内に 99.9 %」のオブジェクトが複製され、「12 時間以内に 100 %」に達するとされています。
このレプリケーション時間を短縮したい場合は、ターボレプリケーションを使用すると、レプリケーション時間を 15 分以内に短縮することが可能です。これにより、障害発生時のデータ損失の可能性(RPO)を大幅に低減することができます。
署名付き URL
署名付き URL は、特定の Cloud Storage リソースに一時的なアクセス権を与える URL です。有効期限内で Google アカウントなしでもアクセスでき、ダウンロード、アップロードなどの操作が可能です。
そのため、署名付き URL は「一時的にファイル共有したい」、「ダウンロードリンクの有効期限を設定したい」、「認証なしのファイルアップロードなどを安全に行いたい」といった場合に使用します。
アクセス制御
アクセス制御に関する以下の内容も押さえておきましょう。
- IAM(Identity and Access Management): IAM により、Cloud Storage へのアクセス制御が可能です。最小権限の原則に基づき、必要なリソースへのアクセスのみを許可することで、セキュリティを強化します。特に、事前定義ロールやカスタムロールについては理解しておきましょう。
- VPC Service Controls : VPC Service Controls は、サービス境界と呼ばれる論理的なセキュリティ境界を定義し、Cloud Storage バケットなどの Google Cloud リソースを囲うことで、外部からの不正アクセスを防いだり、外部へのデータ流出を防ぐことができます。
データ暗号化
データ暗号化に関する内容も押さえておきましょう。Cloud Storage では、以下のいずれかの暗号鍵を用いてデータの暗号化が可能です。
- Google 管理の暗号鍵(デフォルトの暗号化): 標準の Cloud Storage の暗号化として、保存されるデータはデフォルトで Google が管理する暗号鍵によって暗号化されます。
- 顧客管理の暗号鍵(CMEK): 顧客自身が Cloud Key Management Service(Cloud KMS)という鍵管理サービスにて暗号鍵を生成・管理し、暗号化に使用できます。これにより、鍵のライフサイクル管理やアクセス制御をより厳密に行うことが可能になり、コンプライアンス要件への対応やセキュリティポリシーの強化に役立ちます。
- 顧客指定の暗号鍵(CSEK): 顧客が生成した暗号鍵を Google Cloud に提供し、データの暗号化に使用します。鍵の保管と管理は完全に顧客の責任となります。極めて高度なセキュリティ要件や、鍵を Google Cloud 環境上で管理したくない場合に適しています。
ベストプラクティス
Cloud Storage に関するデータの保存方法やアクセス制御などのベストプラクティスが以下の公式ドキュメントにて紹介されていますので、目を通しておくと良いでしょう。
2. BigQuery(重要度:★★★★★)
BigQuery は、ペタバイト規模のデータをスケーラブルに高速処理・分析できるフルマネージドでサーバレスなデータウェアハウスサービスです。
BigQuery は、Professional Data Engineer 試験において最も重要なプロダクトの一つであるため、しっかりと対策しておきましょう!
まずは以下の特徴を押さえておきましょう。
- フルマネージドかつサーバーレス: インフラの管理が不要で、ユーザーがスケーリングを意識することなく、必要な時に必要な分だけリソースが自動的に割り当てられます。これにより、インフラ管理における運用コストが削減できます。
- ペタバイト規模のデータ処理: ペタバイト規模のデータをスケーラブルに高速処理・分析できます。
- 標準 SQL: 標準 SQL に準拠しているため、既存の SQL スキルを活用できます。
- 機械学習: BigQuery ML を使用することで、SQL で簡単に機械学習モデルを構築できます。(BigQuery ML の詳細については、データ可視化と AI・機械学習編で詳しく解説します。)
- 地理空間分析: BigQuery の GIS 機能により、位置情報を含むデータ分析が可能です。
その他の重要なポイントを以下に記載していますので、理解しておきましょう!
BigQuery の仕組み
まずは、BigQuery の仕組みについて理解しておきましょう。(これ以降に解説する BigQuery の各機能について、理解しやすくなります。)
ストレージとコンピューティングの分離
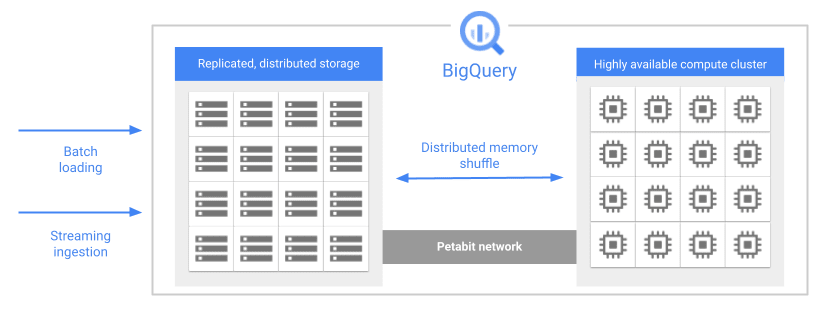
出典: BigQuery アーキテクチャ
BigQuery は、ストレージ(データ保存場所) とコンピューティング(クエリ実行エンジン) が物理的に分離しています。これにより、ストレージとコンピューティングを個別にスケールでき、高いコスト効率とパフォーマンスを実現しています。
行指向と列指向
データ分析を行う上で、データの格納方式や読み取り方式はパフォーマンスに大きな影響を与えます。ここではそのパフォーマンスに関わる、行指向型ストレージと列指向型ストレージの違いについて説明します。
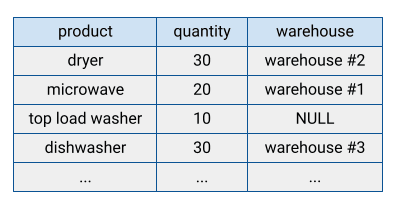
出典: 行指向型ストレージ
従来のデータベースの多くは、データを行単位でまとめて格納する「行指向型ストレージ」を採用しています。この行指向型ストレージは、データを一行ずつ格納する方式であり、個々の行(レコード)へのアクセスや更新に非常に適しています。
しかし、データ分析においてクエリによりデータを読み取る際、全ての列(行全体)ではなく特定の列のみを参照することがほとんどです。これは分析の目的の多くが特定の指標や傾向を抽出することにあるためです。
例えば、ECサイトの売上分析で「過去1年間の月ごとの売上合計」を求めたい場合、必要な情報は「購入日」と「購入金額」だけであり、その他の顧客の住所や電話番号といった情報は分析には不要になります。
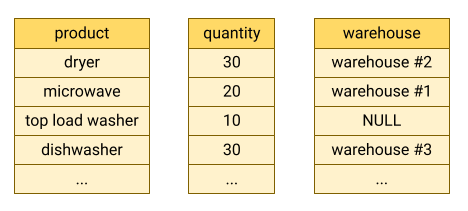
出典: 列指向型ストレージ
データ分析においては、一部の列のみを効率的に読み取る必要がありますが、そのための仕組みとして BigQuery では「列指向型ストレージ」を採用しています。
列指向型ストレージは、データを列単位で格納する方式であり、必要な列だけを読み込むことができます。これにより、I/O が削減され、クエリが高速化されます。また、同じ列のデータは同じデータ型で格納されるため、圧縮効率が向上し、ストレージコストの削減や読み取り速度の向上にもつながります。
ここまでの BigQury の仕組みを理解した上で、以下の機能を理解しておきましょう!
パーティショニングとクラスタリング
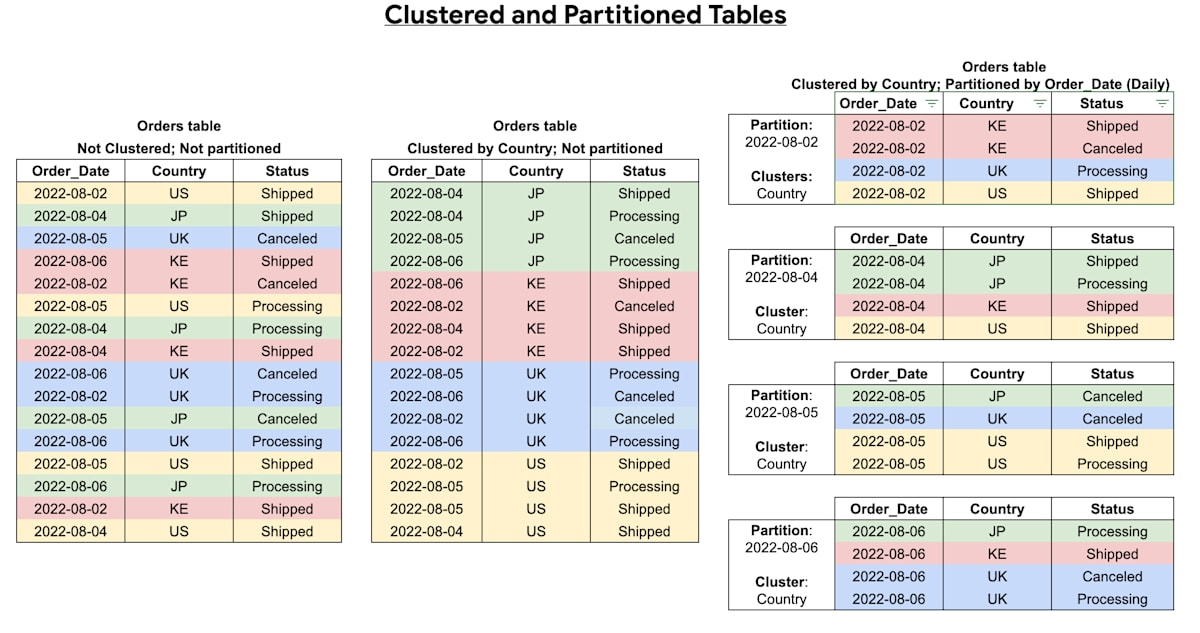
BigQuery のクエリでは、通常テーブル全件をスキャンします。(Where 句や Limit 句を使用したとしても、テーブル全件をスキャンします。フィルタリングはスキャン後に行われます。)
しかし、パーティショニングとクラスタリングと呼ばれる機能を使用することで、クエリがスキャンするデータ量を削減し、パフォーマンスを向上させることができます。パーティショニングとクラスタリングについては以下の通りです。
-
パーティショニング: テーブルを保存する際に、1 つのテーブルを複数のパーティション(区切り)に分割して保存します。これにより、スキャン時に必要なデータのみを読み込み、クエリパフォーマンスを向上させます。パーティション分割の基準となる列として
時間(DATE、TIMESTAMP、DATETIME)、取り込み時間、整数範囲を指定できます。
(※上図の例では一番右のテーブルが該当し、Order_Date(時間単位)列を基にパーティション分割しています。)
また、パーティショニングでは取り込み時間または時間単位の列で分割されたパーティションを作成する場合、パーティショニングの有効期限を設定することが可能です。これにより、有効期限が切れたデータを削除してコスト削減することが可能です。 -
クラスタリング: テーブルを保存する際に、テーブル内のデータを特定の列の値に基づいてソートし、同じ値を持つ行をまとめてストレージ内の近い位置に配置します。これにより、特定の列でフィルタリングしたり、集計する場合のクエリのパフォーマンスが向上します。
(※上図の例では中央のテーブルが該当し、Country列をクラスタリング列として指定しています。)
尚、パーティショニングとクラスタリングは組み合わせて使用することができ、クエリのパフォーマンスを最大限向上させることが可能です。
マテリアライズドビュー

出典: マテリアライズドビュー
クエリパフォーマンスを向上させる方法として、マテリアライズドビューを使用する方法があります。マテリアライズドビューは実体テーブルとビューの中間のようなテーブルであり、クエリ結果を事前に実体テーブルとして保存することでキャッシュのような役割を果たすことができます。これにより、クエリを高速化できます。また、元テーブルのデータが変更されると、マテリアライズドビューも自動的に更新されます。
クエリキャッシュ
BigQuery で同じクエリを複数回実行する場合は、クエリキャッシュにより応答速度が向上します。これは、一度実行したクエリ結果を「キャッシュ結果テーブル」として内部的に一時保存し、キャッシュが保持されている間(初めにテーブル作成されてから約 24 時間以内)に同じクエリを再度実行するとキャッシュが機能し、応答速度が向上するという機能です。
BI Engine
BI Engine は、Looker Studio などの BI ツールなどから頻繁にアクセスされるデータをインメモリとして保存することで、クエリを高速化したい場合に使用するサービスです。また、マテリアライズドビューと組み合わせることで、クエリパフォーマンスをより最適化できます。
クエリパフォーマンス最適化
上記以外にも、クエリパフォーマンスの最適化に関するベストプラクティスが以下の公式ドキュメントにて紹介されていますので、目を通しておくと良いでしょう。
外部データソースへの直接クエリ
BigQuery には、BigQuery 以外のストレージにあるデータに対して直接クエリできる機能があります。この外部テーブルを使用することでデータのコピーや移動なしにクエリ実行ができ、外部ストレージのデータが更新されても、最新データをほぼリアルタイムで取得できるなどの利点があります。

BigQuery における外部データソースへの直接クエリ
サポートされている外部データソースへの直接クエリの方法として以下がありますので、押さえておきましょう。
- BigLake テーブル: Cloud Storage や Amazon S3、Azure Blob Storage の構造化データをサポートしており、直接クエリできます。(※Amazon S3 と Azure Blob Storage に対するクエリは、BigQuery Omni を使用する必要があります。)
- BigQuery Omni : BigLake テーブルを使用して、Amazon S3 または Azure Blob Storage に保存されたデータに対して直接クエリできます。
- オブジェクト テーブル: Cloud Storage バケット内に格納されている非構造化データに対してクエリし、メタデータを取得することができます。
- 連携クエリ(フェデレーションクエリ): BigQuery Connection API を使用して Cloud SQL 、AlloyDB、Spanner と接続し、外部データベースに対して直接クエリを実行できます。尚、クエリの実行は外部データベースのコンピューティングリソースを使用して行われ、その結果を BigQuery に引き渡す仕組みとなっているため、データベースに対する処理負荷は考慮しておく必要があります。
- 外部テーブル(上記以外の直接クエリ): 上記以外の外部データソースに対する直接クエリの方法として、Bigtable、Google ドライブなどのストレージにおける構造化データへの直接クエリが可能です。(※BigLake テーブル と同様に Cloud Storage への直接クエリが可能ですが、BigLake テーブルの方がアクセス制御の観点で推奨されています。)
BigLake テーブルのクエリパフォーマンス最適化
BigLake テーブルでは、クエリパフォーマンスの最適化における以下の機能についても理解しておきましょう。
-
Hive パーティショニング:
gs://my-bucket/data/year=2023/month=10/day=26/file.csvのように、year=2023、month=10、day=26といった形式で、ストレージのディレクトリを分割して作成することで、クエリ実行時にそのパーティション情報を基にして必要なディレクトリのオブジェクトのみをスキャンすることが可能です。 - メタデータキャッシュ: Cloud Storage や Amazon S3 の BigLake テーブルでは、メタデータ(ファイル名、パーティショニング情報、ファイルの物理的なメタデータ(行数など))をキャッシュしておくことが可能であり、例えば、Hive パーティショニングに必要なパーティショニング情報などの取得が高速化されるため、クエリ全体のパフォーマンスが向上します。
- マテリアライズドビュー: Cloud Storage や Amazon S3 の BigLake テーブルでは、メタデータキャッシュが有効化されているテーブルに対して、前述した BigQuery のマテリアライズドビューと同様の機能が提供されています。詳細については、以下の記事で解説されていますのでご参照ください。
バッチロードとストリーミングインサート
BigQuery へのデータロードとして以下の方法がありますので、押さえておきましょう。
- バッチロード: バッチ処理でソースデータを BigQuery テーブルにロードする方法です。CSV や JSON 形式などのファイルを Cloud Storage またはローカルから読み込んだり、クエリ結果のテーブル書き込み、Storage Write API によるデータ書き込みなどが可能です。
- ストリーミングインサート: BigQuery テーブルに対してストリーミングでデータをインサートする方法です。Storage Write API でデータ投入する方法や Dataflow、Datastream、Pub/Sub 経由でデータ投入する方法があります。
バックアップと復元
BigQuery における以下のバックアップ方法について、押さえておきましょう。
- タイムトラベル機能: 現時点から最大で過去 7 日間のデータを自動バックアップしたい場合に使用する機能です。データ保持期間内であればどの時点のデータにもアクセスでき、データ復旧などに利用できます。データ保持期間を過ぎると(例えば、現時点から 7 日より過去の場合)データは自動的に削除されます。尚、タイムトラベル期間の長さはデフォルトで 7 日間であり、2 ~ 7 日の範囲で設定を変更できます。
- フェイルセーフ: 削除されたデータがタイムトラベル期間が経過した後、さらに 7 日間のデータを自動バックアップしたい場合に使用する機能です。尚、フェイルセーフは緊急復旧用の仕組みのため、復元時は Google Cloud カスタマーケアに連絡する必要があります。
- スナップショット: 特定の時点でのテーブルをスナップショットとしてコピーしてデータをバックアップできます。タイムトラベルのデータ保持期間 7 日間以上のデータ保持が必要な場合に使用します。スナップショットは「コピーオンライト」と呼ばれる仕組みによって、ストレージ費用を最小限に抑えることができます。尚、スナップショットに対するデータの変更はできません。
- クローン: スナップショットと同様に、「コピーオンライト」の仕組みを利用してテーブルコピーしますが、クローンされたテーブルに対しての書き込みが可能です。データの追加はあるが、ベーステーブルの変更が少ない場合にストレージ費用を抑えることができます。
コピーオンライト(Copy-On-Write)とは
コピーオンライト(Copy-On-Write)は、データ共有におけるストレージ管理の最適化技術です。簡単に言うと「変更があったらコピーする」仕組みです。変更がないデータに関してはベーステーブルを参照し、変更部分だけコピーを持っておくことができます。
アクセス制御
BigQuery に関する以下のアクセス制御方法を押さえておきましょう。
- IAM : ユーザーやグループに役割を付与し、BigQuery のデータセットやテーブルなどへのアクセス権限を制御します。特に、IAM の事前定義ロールにどんなものがあるかは把握しておくと良いでしょう。
- 承認済みビュー: テーブルの特定の列や行に対するデータへのアクセスを制限したい場合、そのテーブルから列や行をフィルタリング、変換・集計したビューを作成し、そのビューに対してアクセス権を付与することで、元のテーブルへの直接アクセス権なしに特定のデータへのアクセスを許可できます。
-
行または列レベルのセキュリティ: 機密性の高いデータへのアクセスを制限する場合は、ユーザー属性に基づいて制御可能な以下のセキュリティ設定を使用できます。
- 行レベルセキュリティ: データをフィルタし、ユーザーの資格条件に基づいてテーブル内の特定の行へのアクセスを許可することができます。
- 列レベルセキュリティ: ポリシータグを使用して、特定の列へのアクセスを制限することができます。
- VPC Service Controls : 前述の Cloud Storage と同様に、BigQuery も VPC Service Controls により、外部からの不正アクセスや外部へのデータ流出を防ぐことができます。
データ暗号化
データ暗号化に関する内容も押さえておきましょう。BigQueryでは、以下のデータ暗号化が可能です。
- Google 管理の暗号鍵(デフォルトの暗号化): Cloud Storage と同様に、BigQuery は、 Google が管理する暗号鍵によって、データ保存時にデータをデフォルトで暗号化します。
- 顧客管理の暗号鍵(CMEK): Cloud Storage と同様に、顧客自身が Cloud KMS により鍵管理サービスにて暗号鍵を生成・管理し、暗号化に使用できます。
- Cloud KMS Autokey: Cloud KMS Autokey を使用することで、CMEK の作成・使用を簡素化し、鍵生成やサービスアカウント作成を自動化することで鍵管理が容易になります。この Cloud KMS Autokey を使用した BigQuery の暗号化もサポートされています。
- 暗号化関数: BigQuery テーブル内の個々の値を暗号化する場合は、認証付き暗号(AEAD)の暗号化関数を使用することができます。AEAD 暗号化に関する詳細は、公式ドキュメントをご参照ください。
- クライアントサイド暗号化: クライアントサイド暗号化は、BigQuery 保存時の暗号化とは異なり、ユーザーがデータを暗号化してから BigQuery に書き込む方法です。事前にユーザー側で暗号した後、さらに Google 管理の暗号鍵にて暗号化されるため、二重の暗号化となります。
詳細については、以下をご参照ください。
料金体系
BigQuery の料金体系についても試験で問われる可能性があるため、押さえておきましょう。
BigQuery の料金は主に「ストレージ料金」と「コンピューティング料金」で構成されています。それぞれの料金については以下の通りです。
※2023 年 7 月ごろに BigQuery の料金の変更があったため、その内容を踏まえての解説となります。
ストレージ料金
ストレージ料金は、BigQuery のストレージにデータを保存した場合に発生する料金です。従来は「圧縮前サイズ」に対して料金が発生していましたが、新料金では「圧縮後サイズ」に対して料金が発生します。料金比較に関しては以下の通りです。
| 項目 | 新料金 | 従来料金 |
|---|---|---|
| 料金の基準 | 圧縮データのサイズ | 非圧縮データのサイズ |
| 課金対象 | ・保存されたデータ ・タイムトラベルデータ ・フェイルセーフデータ |
・保存されたデータ |
| 課金形式 | ・アクティブストレージ ※1 ・長期保存 ※2 |
・アクティブストレージ ※1 ・長期保存 ※2 |
| 料金 ※3 | ・アクティブストレージ:$0.04 / GB ・長期保存:$0.02 / GB |
・アクティブストレージ:$0.023 / GB ・長期保存:$0.016 / GB |
※1 アクティブストレージは、過去 90 日間で変更されたテーブル(パーティションされたテーブルも含む)が課金対象になります。
※2 長期保存は、90 日間連続して変更されていないテーブル(パーティションされたテーブルも含む)が課金対象になり、料金はアクティブストレージの約 50% 値に自動で引きされます。
※3 上記の料金は us-central1 リージョンの場合です。
コンピュート料金
コンピュート料金には、従来の「オンデマンド料金」と新料金の「BigQuery Editions 料金」があります。
-
オンデマンド料金: クエリでスキャンされたデータの容量に対して課金されます。
料金として us-central1 リージョンでは$6.25 / TiBが発生します。 - BigQuery Editions 料金: クエリ実行時に消費するコンピューティングリソースであるスロット(仮想 CPU)の数に対して課金されます。(BigQuery Editions を使用するためには、後述する「スロット予約」が必要です。)
BigQuery Editions 料金には「Standard」「Enterprise」「Enterprise Plus」の 3 つのプランがあります。これらプランの主な違いは以下の通りです。
| 項目 | Standard | Enterprise | Enterprise Plus |
|---|---|---|---|
| スロット料金※1 | $0.04 / slot hour | $0.06 / slot hour | $0.10 / slot hour |
| 長期コミットメント料金※1 (詳細は後述) |
利用不可 | 1 年:$0.048 / slot hour 3 年:$0.036 / slot hour |
1 年:$0.08 / slot hour 3 年:$0.06 / slot hour |
| 主な利用可能な機能 | ・スロットの自動スケーリング ・Google 管理の暗号鍵 |
Standard の機能に加えて以下機能が使用可能。 ・BigQuery ML ・VPC Service Controls ・BI Engine ・非構造化データのサポート ・行、列レベルのセキュリティ など |
Enterprise の機能に加えて以下機能が使用可能。 ・顧客管理の暗号鍵(CMEK) ・Assured Workload によるコンプライアンス管理 など |
| スロット上限 | 1,600 スロット | 割り当ての上限まで | 割り当ての上限まで |
| SLA | 99.9% 以上 | 99.99% 以上 | 99.99% 以上 |
※1 上記の料金は us-central1 リージョンの場合です。
BigQuery Editions の詳細については、以下の公式ドキュメントをご参照ください。
また、現在は「オンデマンド料金」と「BigQuery Editions 料金」の両方の料金体系を利用できますが、課金形式の違いから以下のような観点での比較によって利用する料金体系を決定する必要があります。
- 「オンデマンド料金」と「BigQuery Editions 料金(各プラン)」のどちらの方が安くなりそうか(「スキャンデータ容量」と「使用スロット数」を比較し、どちらが安くなりそうか)を比較し、費用対効果に優れているか。
- 機能要件やサービスレベル契約(SLA)などを考慮し、「オンデマンド料金」と「BigQuery Editions 料金(各プラン)」のどちらが要件を満たすか。
コスト見積もり方法に関しては、以下の公式ドキュメントをご参照ください。
スロット予約
スロット予約は事前に使用するスロットをワークロードの用途に応じて割り当てる方法です。例えば、本番環境とそれ以外(テストなど)のワークロードが存在する場合、予約名 prod で本番環境用のワークロードを割り当て、区別して利用することが可能です。尚、BigQuery Editions を利用する際は、このスロット予約が必要になります。
詳細については、以下の公式ドキュメントをご参照ください。
長期のコミットメント
コミットメントは指定した期間のスロット数を事前に購入することでコスト削減ができる方法です。コミットメントの種類として「3 年間のコミットメント」と「年間コミットメント」があります。詳細については、以下の公式ドキュメントをご参照ください。
3. Bigtable(重要度:★★★★☆)
Bigtable は、大規模データ処理に特化した NoSQL(非リレーショナル)データベースサービスです。
まずは以下の特徴を押さえておきましょう。
- Key-Value ストア: データの書き込みと読み取りはキー(行キー)に基づいて行われます。行キーはデータの分散にも使用され、これにより大規模なデータセットでも高速なデータアクセスが可能となります。
- データモデルの柔軟性: Bigtable は NoSQL データベースでありスキーマレスなため、データモデルに高い柔軟性があります。
- 高スループットと低レイテンシ: 大量のデータを高速に処理できます。読み取り・書き込みともに高速です。(ただし、後述する行キー設計には注意が必要です。)
- 高いスケーラビリティ: データ量の増加やトラフィックの変動に合わせて、スケールアップ・ダウンできます。
その他の重要なポイントを以下に記載していますので、理解しておきましょう!
Bigtable の仕組み
Bigtable の仕組み自体が直接的に試験で問われることはないとは思いますが、後述する行キー設計を理解するために必要なので理解しておきましょう。
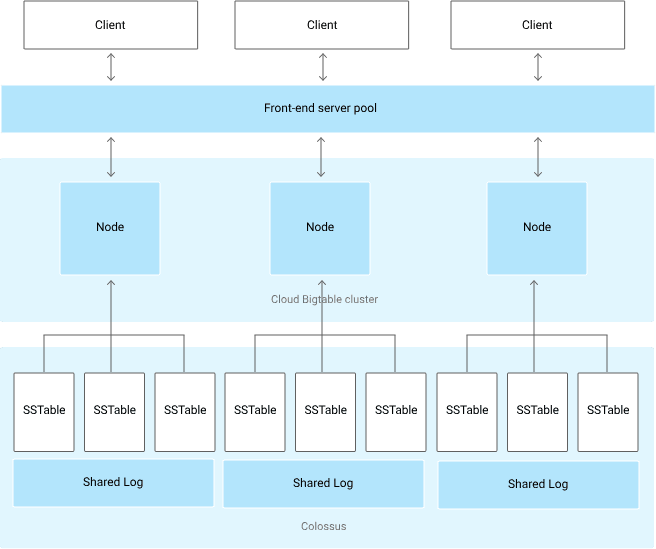
出典: Bigtable のアーキテクチャ
Bigtable を構成する要素は以下の通りになります。
- クライアント(Client): ユーザーアプリケーションやサービスなど、Bigtable にアクセスする主体になります。データの読み書き要求を送信します。
- フロントエンドサーバープール(Front-end server pool): クライアントからの要求を受け付け、適切な Bigtable ノードにルーティングする役割を担います。これにより、負荷分散と高可用性を実現しています。
-
クラスタ(Bigtable cluster): Bigtable の中核となる部分で、複数のノードで構成されています。
- ノード(Node): 実際にデータの格納と処理を行うサーバーです。各ノードは複数の SSTable を管理しており、SSTable から必要なデータを読み込みます。(尚、ノードのことを「タブレットサーバー」と呼ぶことがあります。)
-
Colossus : Google のグローバルファイルシステムです。Bigtable のデータ(SSTable と共有ログ)を永続的に保存します。高い信頼性と可用性を提供します。
- SSTable(Sorted String Table): Bigtable のデータ格納形式です。ソートされた行キーと値のペアを格納する不変のファイルです。データ保存時は、テーブルのデータが複数の SSTable に分かれて保存されます。また、データ取得時は、これら SSTable の必要なファイルのみを読み込みます。
- 共有ログ(Shared Log): 書き込み操作のログを保持します。障害発生時のデータ復旧に使用されます。
行キー設計
Bigtable で最も押さえておきたいポイントは「行キー設計」です。
前述の通り、Bigtable では行キーによってデータがソートされて保存されます。これにより、ソート順が近いデータほど同じノードに割り当てられます。もし、アクセスする行キーに偏りがあった場合、 ホットスポットとよばれるノードへの集中アクセス状態になり、パフォーマンスに悪影響を及ぼしてしまいます。そのため、アクセスの傾向を考慮した行キー設計が重要になります。
Bigtable テーブルでは、行キーは 1 つだけ設定可能です。そのため、複数のデータをソートしたい場合は下図のようにコロン、スラッシュ、ハッシュ記号などの区切り文字で区切りながら複数の値を含ませます。

出典: 行キー
ホットスポットを回避するために、以下のような行キー設計することが推奨されています。
- キーの接頭辞: 複数の要素を組み合わせてキーを作成する場合、アクセス頻度の高い要素を接頭辞として設定しないようにしましょう。
- 単調増加するキーの回避: タイムスタンプや連番など、単調増加する値をそのまま行キーに使用すると、新しいデータが常に同じノードに書き込まれるため、ホットスポットが発生しやすくなるため、できる限り回避する必要があります。
- 行サイズ: 1 行に格納するデータ量を適切に保つことも重要です。行が大きすぎると、読み書きのパフォーマンスに影響します。
行キー設計に関するその他のベストプラクティスに関しては、以下の公式ドキュメントに目を通しておくと良いでしょう。
Key Visualizer
Key Visualizer は、Bigtable の使用パターンの分析に利用するツールです。特定の行キーでホットスポットが発生しているかを確認することができます。
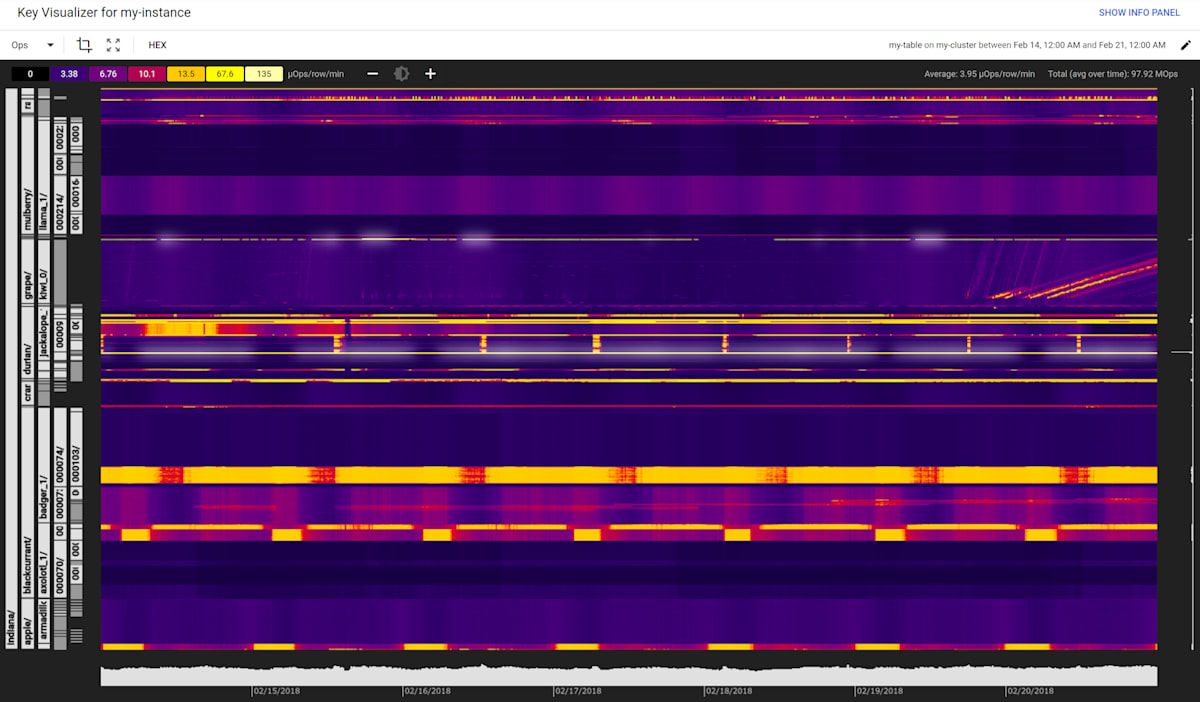
Key Visualizer は、上図のようにノードの負荷状況をヒートマップで表現しています。縦軸は行キーの範囲、横軸は時間を表し、色の濃淡でアクセス頻度を示します(暖色系ほど高負荷)。これにより、特定の行キー範囲へのアクセス集中(ホットスポット)や時間帯ごとのアクセス状況を把握できます。
可用性
Bigtable では、レプリケーションの機能により、データを複数のリージョンまたは同じリージョン内の複数のゾーンにコピーして、データの可用性と耐久性を向上させることができます。詳細については、以下の公式ドキュメントをご参照ください。
バックアップと復元
Bigtable では以下の方法でデータのバックアップと復元が可能です。
- 標準バックアップ: 長期保持用のバックアップ方法です。標準バックアップから SSD クラスタに復元する場合、復元オペレーションで Bigtable による追加の最適化が必要になります。詳細については、復元時のパフォーマンスをご参照ください。
- ホットバックアップ: 迅速な復元のために最適化されたバックアップ方法です。復元直後に新しいテーブルから読み取る際のレイテンシが低くなり、標準バックアップから復元するよりも高速です。
詳細については、以下の公式ドキュメントをご参照ください。
4. Firestore(重要度:★★☆☆☆)
Firestore は、NoSQL のサーバーレスなデータベースサービスです。柔軟なデータ構造とリアルタイムなデータ同期機能を備えており、モバイルアプリや Web アプリケーションなどのバックエンドとして利用されます。以下の特徴を押さえておきましょう。
- ドキュメント指向: データを JSON 形式のドキュメントとして格納します。
- フルマネージドサービス: サーバーの管理やインフラストラクチャの運用は Google がすべて行うため、開発者はアプリケーションの開発に集中できます。
- スケーラビリティ: 自動スケールが可能であり、トラフィックの変動に柔軟に対応できます。
- クライアントサイドからの直接接続: モバイルアプリやウェブアプリのクライアントサイドから直接接続ができます。
- リアルタイム同期: 同じデータベースに接続している他のデバイスとのデータの同期が可能です。
- オフラインモード: ネットワークが不安定な環境でも、データをローカルにキャッシュして操作できます。
- セキュリティ: 細かい権限設定やセキュリティルールでデータを保護できます。
5. Cloud SQL(重要度:★★★☆☆)
Cloud SQL は、MySQL、PostgreSQL、SQL Server をサポートするリレーショナルデータベースのマネージドサービスです。ウェブアプリケーション、モバイルアプリケーション、エンタープライズアプリケーションなど、様々なデータベース要件に対応できます。
Cloud SQL については、以下の内容を理解しておきましょう!
可用性
まずは可用性に関わる以下の内容を押さえておきましょう。
高可用性(HA)構成

出典: Cloud SQL 高可用性
高可用性(HA)構成は、プライマリとスタンバイのインスタンスで構成され、プライマリに障害が発生するとスタンバイに自動フェイルオーバーします。異なるゾーンにインスタンスを配置することでゾーン障害に備え、同期レプリケーションによりフェイルオーバー時のデータ損失を最小限に抑えることができます。
リードレプリカ
リードレプリカは、プライマリデータベースの読み取り専用コピーで、読み取りクエリの負荷分散とパフォーマンス向上に役立ちます。
リードレプリカは、プライマリインスタンスのデータが更新されると、ほぼリアルタイムでリードレプリカにレプリケーションされます。高可用性構成(HA構成)と似ていますが、HA構成は可用性向上を目的とするのに対し、リードレプリカは読み取りワークロードの負荷分散を目的とする点で異なります。
ただし、リードレプリカは高可用性を直接の目的とはしないものの、手動でプライマリインスタンスに昇格(リードレプリカをプロモート)させることが可能です。また、プライマリインスタンスとは異なるリージョンに作成されたリードレプリカ(クロスリージョンリードレプリカ)を用いることで、リージョンを跨いだ災害対策(DR)を実現できます。
バックアップと復元
Cloud SQL のバックアップには、オンデマンド(手動)バックアップと自動バックアップがあります。自動バックアップは、4 時間のバックアップ時間枠内で毎日行われ、デフォルトで最新 7 件(最大 365 件まで設定可能)が保持されます。
また、復元は以下のような場合に行います。
- 同インスタンスへの復元: 元の Cloud SQL インスタンスにデータを復元し、障害復旧や誤操作からの復旧に利用します。
- 別インスタンスへの復元: 別の Cloud SQL インスタンスにデータを復元し、テスト環境構築やデータ移行、災害復旧などに利用します。元のインスタンスに影響を与えずにデータのコピーを作成できます。
- ポイントタイムリカバリ(PITR):特定の時点(過去のある時点)にデータを復元し、誤操作などによるデータ損失をより細かく復旧できます。バックアップからの復元後に、PITR で目的の時点までデータを巻き戻す形で使用します。
詳細については、以下の公式ドキュメントをご参照ください。
メンテナンス
Cloud SQL はマネージドサービスであり、物理基盤や OS 、データベースエンジンは Google Cloud が管理していますが、定期的なメンテナンスが必要で、このメンテナンスによってダウンタイムが発生します。以下のメンテナンスに関する設定を理解しておきましょう。
- メンテナンスウィンドウ: メンテナンスを実施する曜日と 1 時間単位の時間枠を指定し、システムの利用率が低い時間帯に設定することでダウンタイムをコントロールします。
- メンテナンスタイミング: メンテナンス通知後、実際にメンテナンスが実施されるまでの期間(Any、Week 1、Week 2、Week 5)を選択し、準備期間を確保します。
- メンテナンス拒否期間: システムの繁忙期など安定稼働が最優先される期間にメンテナンスを延期(最長 90 日間)し、ダウンタイムを回避します。
詳細については、以下の公式ドキュメントをご参照ください。
ネットワークとセキュリティ
- 承認済みネットワーク: 接続を許可する IP アドレス範囲を指定し、不正アクセスを防ぎます。
- SSL/TLS : Cloud SQL への接続は SSL/TLS で暗号化され、データがネットワーク上で傍受されるリスクを軽減します。
- Cloud SQL Auth proxy : Cloud SQL Auth proxy は、承認済みネットワークや SSL の構成を必要とせず、安全にインスタンスにアクセスできる Cloud SQL コネクタです。IAM 権限に基づいたデータベース認証も可能です。
- プライベートIP: 外部 IP アドレスを持たない Cloud SQL インスタンスは VPC ネットワーク内からのみアクセス可能で、インターネットからの直接アクセスを防ぎます。
- IAM : IAM はユーザーの認証、認可、アクセス制御を行い、最小権限の原則に従って必要な権限のみを付与することでセキュリティを確保します。
詳細については、以下の公式ドキュメントをご参照ください。
ベストプラクティス
Cloud SQL のパフォーマンス、耐久性、可用性を向上させるためのベストプラクティスについて、以下の公式ドキュメントで紹介されておりますので、目を通しておくと良いでしょう。
6. AlloyDB for PostgreSQL(重要度:★★★☆☆)
AlloyDB for PostgreSQL は、PostgreSQL と互換性のあるフルマネージドのリレーショナルデータベースサービスです。
AlloyDB は、セルフマネージド(※) のPostgreSQL と比較して、トランザクション ワークロードが 4 倍以上高速で、コスト パフォーマンスが最大 2 倍向上しています。また、後述するカラム型エンジンによる分析クエリの高速化や AlloyDB AI による AI 機能が提供されていることも特徴です。
※ここでのセルフマネージドとは、ユーザー自身がデータベースをサーバーにインストール、構成、管理、保守を行い自己管理することです。
AlloyDB については、以下の内容を理解しておきましょう!
AlloyDB の仕組み
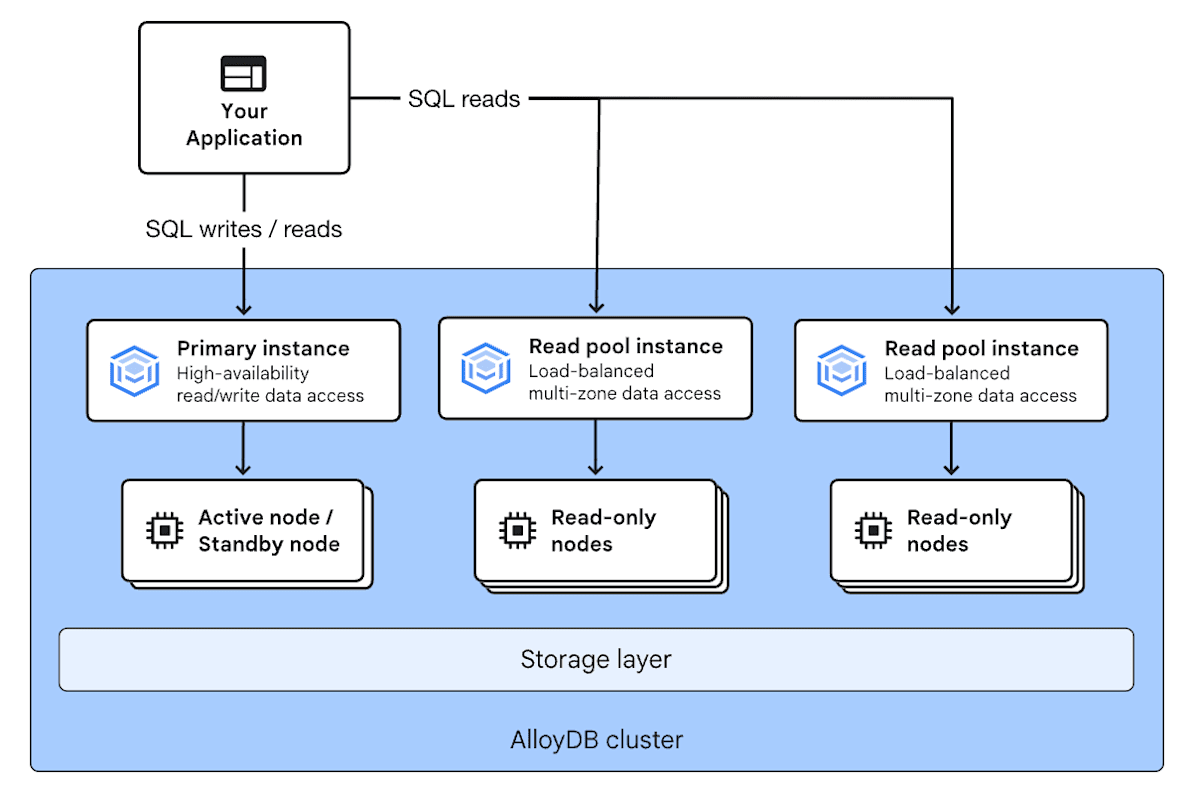
出典: AlloyDB の仕組み
AlloyDB でまず押さえておくべきことは「ストレージ」と「コンピューティング」が分離されていることです。これは前述した BigQuery の仕組みと同じ概念であり、ストレージとコンピューティングを個別にスケールさせ、高いコスト効率とパフォーマンスを実現しています。
また、AlloyDB を構成する要素は以下の通りになります。
- クラスタ(Cluster): AlloyDB を構成する上で最も基本的な単位です。クラスタ内の要素として、インスタンス、ノード、ストレージが含まれます。
- ノード(Node): データベースエンジンとしてクエリを実行する仮想マシンインスタンスです。
-
インスタンス(Instance): ノードをまとめたもので、アプリケーションがデータベースに接続するためのアクセスポイントを提供します。各インスタンスは、VPC 内にプライベート静的 IP アドレスを持ちます。AlloyDB には以下 2 種類のインスタンスがあります。
-
プライマリインスタンス(Primary Instance): 各クラスタには 1 つのプライマリインスタンスがあり、データへの読み取りまたは書き込みアクセスポイントを提供します。プライマリインスタンスとして、以下を選択することが可能です。
- HA プライマリインスタンス: アクティブノードとスタンバイノードの 2 つのノードを持ち、アクティブノードに障害が発生した場合は、スタンバイノードをアクティブノードに自動昇格させることで、高可用性(HA)を実現しています。
- 基本インスタンス: 高可用性が不要な環境では、基本インスタンスでコスト削減が可能です。基本インスタンスは単一ノード構成で、スタンバイノードは提供されません。
- 読み取りプールインスタンス(Read Pool Instance): 読み取り専用のインスタンスです。クラスタには、必要に応じて 1 つ以上(クラスタ全体で最大 20 個)の読み取りプールインスタンスを含めることができます。
-
プライマリインスタンス(Primary Instance): 各クラスタには 1 つのプライマリインスタンスがあり、データへの読み取りまたは書き込みアクセスポイントを提供します。プライマリインスタンスとして、以下を選択することが可能です。
- ストレージ層(Storage layer): Google 分散ファイルシステムの Colossus を基盤としたデータ永続化の役割を担います。
可用性
AlloyDB は、前述の通り HA プライマリインスタンスにより高可用性(HA)を実現できます。また、2 つ以上のノードを含む読み取りプールインスタンスを追加すると、マルチゾーンでの高可用性のあるアクセスポイントが作成できます。詳細については、以下の公式ドキュメントをご参照ください。
バックアップと復元
AlloyDB では以下の方法でデータのバックアップと復元が可能です。
- 継続的なバックアップと復元: 同じプロジェクトとリージョン内の別クラスタの最新状態を基にして、新しいクラスタを作成する機能です。この機能は、デフォルトで全てのクラスタに対して有効になっています。
- 個別バックアップと復元: クラスタのデータベースの完全なコピーを含むファイルベースのバックアップと復元の方式です。オンデマンドまたは定期スケジュールによってバックアップを作成し、新しいクラスタに復元できます。
詳細については、以下の公式ドキュメントをご参照ください。
カラム型エンジン

カラム型エンジンは、インスタンスのメモリ上でデータを列形式で保持し、分析クエリを高速処理できるエンジンです。プライマリインスタンス、読み取りプールインスタンスの両方に適用できます。
カラム型エンジンは、インスタンスのメモリ上にある行データを AI/ML によって自動的に列型形式へ変換します。また、インスタンスのメモリと超高速キャッシュによる複数キャッシュによって高速なパフォーマンスを実現しています。
インデックスアドバイザーを使用すると、実行されているクエリを定期的に分析し、クエリのパフォーマンスを高める新しいインデックスが提案してくれます。
AlloyDB AI
AlloyDB AI は、AlloyDB に AI 機能を組み込み、pgvector 互換の高速なベクトル検索や Vertex AI でホストされている機械学種モデルの使用などが可能な AI 対応データベースです。
アクセス制御
AlloyDB のアクセス制御として、他の Google Cloud サービスと同様に IAM や VPC Service Controls によるアクセス制御が可能です。
また、AlloyDB の接続設定に関しては以下の公式ドキュメントに目を通しておくと良いでしょう。
データ暗号化
AlloyDB のデータは、他の Google Cloud サービスと同様にデフォルトで Google が管理する暗号鍵により暗号化されています。加えて、特定のコンプライアンス要件または規制要件がある場合に CMEK を使用することが可能です。
ベストプラクティス
AlloyDB のパフォーマンス、耐久性、可用性を向上させるためのベストプラクティスについて、以下の公式ドキュメントで紹介されておりますので、目を通しておくと良いでしょう。
7. Spanner(重要度:★★★☆☆)
Spanner は、リレーショナルデータベースの構造と非リレーショナルデータベースの水平スケーラビリティを兼ね備え、グローバルに分散する強整合性を備えたフルマネージドの分散データベースサービスです。
Spanner については、以下の内容を理解しておきましょう!
Spanner の仕組み

出典: Spanner のアーキテクチャ
Spanner は、AlloyDB などと同様に「ストレージ」と「コンピューティング」が分離されており、高いコスト効率とパフォーマンスを実現しています。
Spanner を構成する主な要素は以下の通りになります。
- インスタンス: Spanner のリソースを管理する基本単位です。ユーザーはインスタンスを作成し、その中にデータベースを作成します。地理的に異なるリージョンにまたがって配置することも可能です。
- ノード: データを処理するコンピューティングリソースです。インスタンスは複数のノードで構成され、データはこれらのノードに分散配置されます。ノードは、障害発生時に他のノードに処理を引き継ぐことで高可用性を実現しています。
- スプリット: ストレージ保存におけるデータを分割する単位です。データはキーの範囲(※後述)によって分割され、各スプリットは連続したキー範囲のデータを保持します。ノードの追加やデータ量の増減が発生した場合、スプリットは自動的に分割や各ノードへの割り当てが行われます。
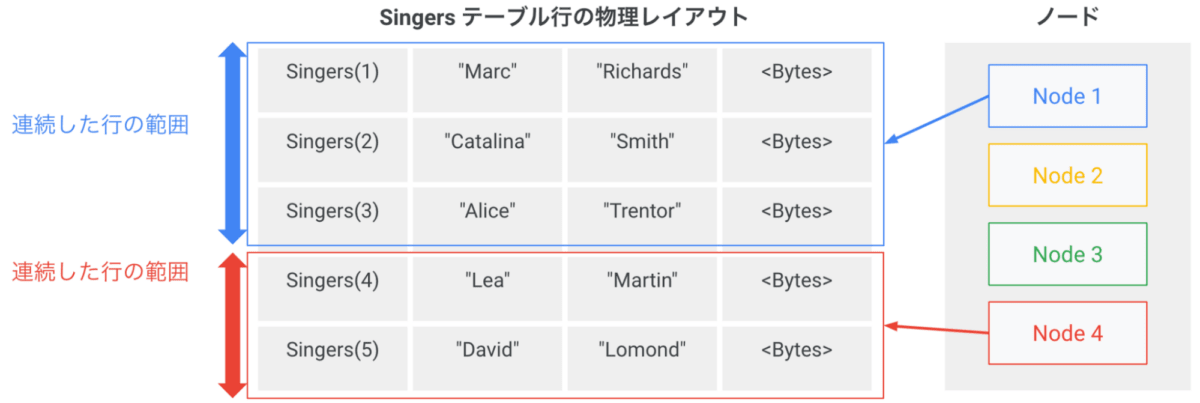
出典: Spanner のスプリット範囲
スプリットの範囲は、連続したデータのキー(上図の Singers の id = 1 ~ 5)を基にして決められます。
スプリットされた後、特定のスプリット範囲に紐づくノードに対してアクセスが集中するとホットスポットが発生します。(前述の Bigtable のホットスポットと同様の原理です。)そのため、このホットスポットを回避するためのキー設計が必要となります。
キー設計のベストプラクティスに関しては、以下の公式ドキュメントをご参照ください。
可用性
Spanner は、インスタンスを物理的に異なるリージョンにまたがった配置とレプリケーションが可能です。インスタンス作成時に、リージョン、デュアルリージョン、マルチリージョンの構成を選択することが可能です。
詳細については、以下の公式ドキュメントをご参照ください。
バックアップと復元
Spanner では「バックアップと復元」もしくは「インポートとエクスポート」の機能が使用できます。
バックアップと復元では、インスタンスと同じロケーションにバックアップすることが可能です。また、インポートとエクスポートでは、Cloud Storage に存在する CSV や Avro などのファイルをインポートまたはエクスポートすることが可能です。
詳細については、以下の公式ドキュメントをご参照ください。
Spanner Data Boost

Spanner Data Boost は、既存の Cloud Spanner インスタンスのリソースに負荷をかけず、別のコンピューティングリソースにてデータ処理が可能な機能です。トランザクション処理に影響を与えることなく、データ分析やデータエクスポートしたい場合に利用します。
Spanner Vertex AI インテグレーション
Spanner Vertex AI インテグレーションは、 Vertex AI にホストされている機械学習モデルを使用したい場合に使う機能です。Spanner と Vertex AI を統合し、GoogleSQL や PostgreSQL のインターフェースを介して Vertex AI の機械学習モデルを使用できます。
アクセス制御
Spanner のアクセス制御として、他の Google Cloud サービスと同様に IAM や VPC Service Controls によるアクセス制御が可能です。
データ暗号化
Spanner のデータは、他の Google Cloud サービスと同様にデフォルトで Google が管理する暗号鍵により暗号化されています。加えて、特定のコンプライアンス要件または規制要件がある場合に CMEK を使用することが可能です。
8. Memorystore(重要度:★☆☆☆☆)
Memorystore は、Google Cloud が提供するフルマネージドのインメモリデータストアサービスです。Redis と Memcached をサポートしており、アプリケーションの高速なデータアクセスとキャッシュ機能を提供します。これにより、データベースへの負荷を軽減し、アプリケーションのパフォーマンスを大幅に向上させることが可能です。
-
Memorystore for Redis: Redis は、文字列、ハッシュ、リスト、セット、ソート済みセットなど多様なデータ構造をサポートしている分散型インメモリキャッシュシステムです。Memorystore for Redis は、この Redis を Google Cloud 上で利用できるフルマネージドサービスです。
-
Memorystore for Valkey: Valkey は、Redis をフォークして開発されたインメモリキャッシュシステムです。非同期 I/O とマルチスレッドを活用し、大量データを並行して処理することで高速化を実現しています。Memorystore for Valkey は、この Valkey を Google Cloud 上で利用できるフルマネージドサービスです。
-
Memorystore for Memcached: Memcached は、シンプルなキーバリューストアとして高速なキャッシュ用途に特化した分散型インメモリキャッシュシステムです。マルチスレッドで動作し、容易なスケーリングが可能です。Memorystore for Memcached は、この Memcached を Google Cloud 上で利用できるフルマネージドサービスです。
まとめ
今回の記事では、Professional Data Engineer 試験対策として、Google Cloud の主要なデータストレージプロダクトについて解説しました。この記事を通して、それぞれのプロダクトの特徴、ユースケースなどをしっかりと理解し、試験に臨めると良いと思います。また、記載しているポイントに関連する公式ドキュメントも併せて参照することで、より深い理解が得られますので、ぜひ取り組んでみてください!
Discussion