Cloud Storage にアップロードしたCSVファイルを BigQuery に自動インポートする





こんにちは、クラウドエース株式会社の許です。
この記事では、Cloud Storage にアップロードした CSV ファイルを BigQuery に自動インポートする方法について紹介します。
大まかな構成
以下のような構成で実装していきます。

Cloud Storage に CSV ファイルをアップロードすると、Cloud Run Functions がトリガーされ、BigQuery に自動インポートされます。
Cloud Run Functions は、いくつかトリガーが存在していますが、今回は Cloud Storage のファイルアップロード時にトリガーされる Cloud Storage トリガーを使用します。
事前準備
事前に以下の準備が必要ですが、今回の主題からは逸れるため省略します。
- Big Query データセット、テーブルの作成
- Cloud Storage バケットの作成
- CSV ファイルの準備
事前に用意する CSV ファイルは、以下のようなファイルになります。
Big Query テーブルのそれぞれのカラムの型は、それぞれのカラム名と同じです。
string,int,float,date,datetime
hello,1,1.1,2018-01-01,2018-01-01 00:00:00
world,2,2.2,2018-01-02,2018-01-02 00:00:00
apple,3,3.3,2018-01-03,2018-01-03 00:00:00
orange,4,4.4,2018-01-04,2018-01-04 00:00:00
banana,5,5.5,2018-01-05,2018-01-05 00:00:00
pineapple,6,6.6,2018-01-06,2018-01-06 00:00:00
grape,7,7.7,2018-01-07,2018-01-07 00:00:00
strawberry,8,8.8,2018-01-08,2018-01-08 00:00:00
Cloud Run Functions の作成
- Cloud Run のコンソール画面から、[関数を作成] をクリックします。

- サービス名、リージョンを設定します。
- ランタイムを選択します。今回は Java 21 を選択します。
- トリガーを選択します。今回は Cloud Storage トリガーを選択します。
- トリガーの名前: 自動設定
- バケット: 事前に作成した Cloud Storage バケット
- イベントプロバイダ: Cloud Storage
- イベントタイプ: google.cloud.storage.object.v1.finalize
- サービスアカウント: Default compute service account
- 今回はデフォルトのサービスアカウントを使用していますが、本番環境などで利用する場合は、適切な権限を持ったサービスアカウントを使用してください。
- 認証にて、[認証が必要] を選択します。
- 未承認の呼び出しによる関数の実行を禁止する意図があります
- [作成] をクリックします。
作成を押すと自動的に関数がデプロイされます。
デプロイされた関数にソースコードを追加
先ほど作成した関数の[ソース]に以下のコードを記述します。
StorageFunction.java
package gcfv2storage;
import com.google.cloud.bigquery.*;
import com.google.cloud.functions.CloudEventsFunction;
import com.google.gson.JsonObject;
import com.google.gson.JsonParser;
import io.cloudevents.CloudEvent;
import java.util.Objects;
import java.util.logging.Logger;
public class StorageFunction implements CloudEventsFunction {
private static final Logger logger = Logger.getLogger(StorageFunction.class.getName());
// 各種環境情報を設定
private static final String PROJECT_ID = {プロジェクトID};
private static final String DATASET_ID = {データセットID};
private static final String TABLE_ID = {テーブルID};
@Override
public void accept(CloudEvent event) {
// Cloud Run Functionsからの入力を受け付ける
String eventName = new String(Objects.requireNonNull(event.getData()).toBytes());
logger.info("Cloud Event data: " + eventName);
// 入力情報をGsonを使ってJson型に変換し、各種情報を取得
JsonObject data = JsonParser.parseString(eventName).getAsJsonObject();
String bucketName = data.get("bucket").getAsString();
String fileName = data.get("name").getAsString();
logger.info("Processing file: " + fileName + " from bucket: " + bucketName);
String sourceUri = "gs://" + bucketName + "/" + fileName;
// BigQueryの各カラムの設定を行う
// Schema schema = Schema.of(
// Field.of("string", LegacySQLTypeName.STRING),
// Field.of("int", LegacySQLTypeName.INTEGER),
// Field.of("float", LegacySQLTypeName.FLOAT),
// Field.of("date", LegacySQLTypeName.DATE),
// Field.of("datetime", LegacySQLTypeName.DATETIME)
// );
Schema schema = Schema.of(
Field.newBuilder("string", LegacySQLTypeName.STRING).setMode(Field.Mode.NULLABLE).setDescription("string Column").build(),
Field.newBuilder("int", LegacySQLTypeName.INTEGER).setMode(Field.Mode.NULLABLE).setDescription("int Column").build(),
Field.newBuilder("float", LegacySQLTypeName.FLOAT).setMode(Field.Mode.NULLABLE).setDescription("float Column").build(),
Field.newBuilder("date", LegacySQLTypeName.DATE).setMode(Field.Mode.NULLABLE).setDescription("date Column").build(),
Field.newBuilder("datetime", LegacySQLTypeName.DATETIME).setMode(Field.Mode.NULLABLE).setDescription("datetime Column").build()
);
// CSVファイルをBigQueryにアップロードための各種設定と処理
try {
BigQuery bigQuery = BigQueryOptions.getDefaultInstance().getService();
// 先頭行をスキップ
CsvOptions csvOptions = CsvOptions.newBuilder().setSkipLeadingRows(1).build();
TableId tableId = TableId.of(PROJECT_ID, DATASET_ID, TABLE_ID);
LoadJobConfiguration loadConfig =
LoadJobConfiguration
.newBuilder(tableId, sourceUri + fileName, csvOptions)
.setSchema(schema)
.build();
// ロードジョブを作成し、完了するまで待機
Job job = bigQuery.create(JobInfo.of(loadConfig));
job = job.waitFor();
if (job.isDone() && job.getStatus().getError() == null) {
logger.info("Job completed successfully");
}
else {
logger.severe("Job failed: " + job.getStatus().getError());
}
} catch (BigQueryException | InterruptedException e) {
logger.severe("Error: " + e.getMessage());
}
}
}
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>gcfv2storage</groupId>
<artifactId>http</artifactId>
<version>0.0.1</version>
<name>Cloud Storage Function for GCFv2</name>
<properties>
<maven.compiler.release>21</maven.compiler.release>
</properties>
<dependencies>
<!-- Google Cloud Storage client -->
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-storage</artifactId>
<version>2.45.0</version>
</dependency>
<!-- Google BigQuery client -->
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigquery</artifactId>
<version>2.44.0</version>
</dependency>
<!-- Apache Commons CSV for CSV parsing -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-csv</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>com.google.cloud.functions</groupId>
<artifactId>functions-framework-api</artifactId>
<version>1.0.4</version>
</dependency>
<dependency>
<groupId>io.cloudevents</groupId>
<artifactId>cloudevents-api</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.11.0</version>
</dependency>
</dependencies>
</project>
記述が終わったら、[保存して再デプロイ] をクリックしてデプロイします。
Cloud Storage にファイルをアップロードして BigQuery にインポート
-
事前に準備していた CSV ファイルを Cloud Storage にアップロードします。

ファイルをアップロードすると、自動的に関数がトリガーされます。 -
Cloud Run Functions のログを確認し、処理が正常に完了していることを確認します。

画像にあるように、ログにJob completed successfullyと表示されていれば、処理が正常に完了しています。 -
BigQuery のデータセット、テーブルを確認し、データがインポートされていることを確認します。
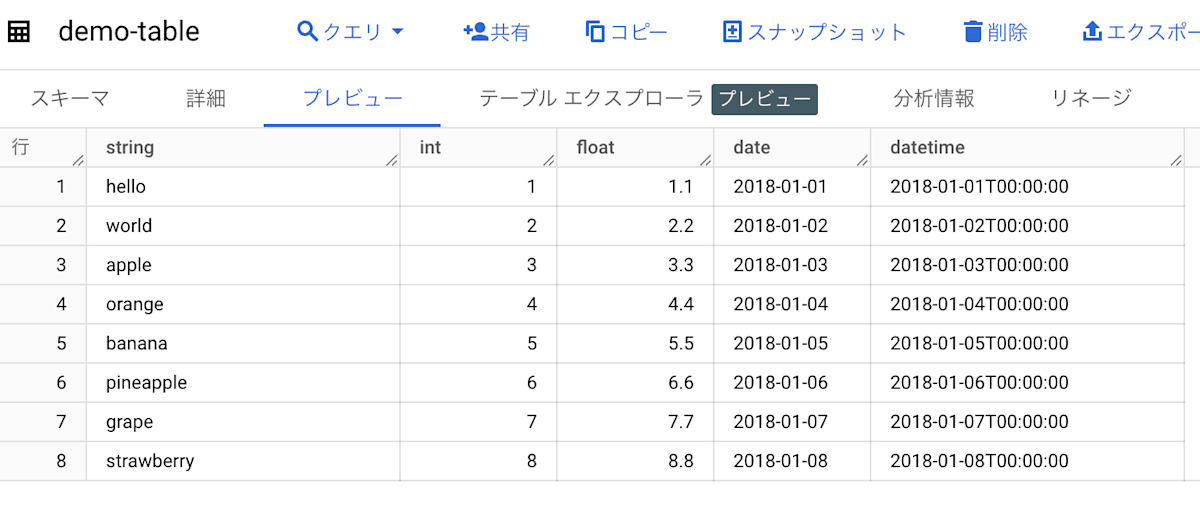
正常にデータがインポートされていることが確認できればインポート完了です。
終わりに
Cloud Storage にアップロードした CSV ファイルを BigQuery に自動インポートする方法について紹介しました。
Cloud Run Functions は、他にもいくつかのトリガーが存在しており、それぞれのトリガーに合わせて処理を実装することができます。
今回の記事が皆様のお役に立てれば幸いです。
番外編
Python での実装
Python で実装する場合、Python の本体コードである main.py と、依存関係を記述した requirements.txt を作成します。
import functions_framework
from google.cloud import bigquery
# Triggered by a change in a storage bucket
@functions_framework.cloud_event
def hello_gcs(cloud_event):
data = cloud_event.data
event_id = cloud_event["id"]
event_type = cloud_event["type"]
bucket_id = data["bucket"]
file_name = data["name"]
gcs_uri = f"gs://{bucket_id}/{file_name}"
# BigQuery
dataset_id = "{データセット名}"
table_id = "{テーブル名}"
client = bigquery.Client()
job_config = bigquery.LoadJobConfig(
schema=[
bigquery.SchemaField("string", "STRING"),
bigquery.SchemaField("int", "INTEGER"),
bigquery.SchemaField("float", "FLOAT"),
bigquery.SchemaField("date", "DATE"),
bigquery.SchemaField("datetime", "DATETIME"),
],
skip_leading_rows=1,
source_format=bigquery.SourceFormat.CSV,
)
try:
load_job = client.load_table_from_uri(
gcs_uri, f"{dataset_id}.{table_id}", job_config=job_config
)
print(f"Starting job {load_job.job_id} for file {file_name}")
load_job.result()
print(f"File {file_name} successfully loaded into {dataset_id}.{table_id}")
except Exception as e:
print(f"Failed to load file {file_name} into BigQuery: {e}")
requirements.txt
functions-framework==3.*
google-cloud-bigquery
Go での実装
Go で実装する場合、Go の本体コードである main.go と、依存関係を記述した go.mod を作成します。
// Package helloworld provides a set of Cloud Functions samples.
package gcf
import (
"cloud.google.com/go/bigquery"
"context"
"fmt"
"log"
"time"
"github.com/GoogleCloudPlatform/functions-framework-go/functions"
"github.com/cloudevents/sdk-go/v2/event"
)
func init() {
functions.CloudEvent("HelloStorage", helloStorage)
}
// StorageObjectData contains metadata of the Cloud Storage object.
type StorageObjectData struct {
Bucket string `json:"bucket,omitempty"`
Name string `json:"name,omitempty"`
Metageneration int64 `json:"metageneration,string,omitempty"`
TimeCreated time.Time `json:"timeCreated,omitempty"`
Updated time.Time `json:"updated,omitempty"`
}
const PROJECT_ID = "{プロジェクト名}"
const DATASET_ID = "{データセット名}"
const TABLE_ID = "{テーブル名}"
// helloStorage consumes a CloudEvent message and logs details about the changed object.
func helloStorage(ctx context.Context, e event.Event) error {
log.Printf("Event ID: %s", e.ID())
log.Printf("Event Type: %s", e.Type())
var data StorageObjectData
if err := e.DataAs(&data); err != nil {
return fmt.Errorf("event.DataAs: %v", err)
}
log.Printf("Bucket: %s", data.Bucket)
log.Printf("File: %s", data.Name)
log.Printf("Metageneration: %d", data.Metageneration)
log.Printf("Created: %s", data.TimeCreated)
log.Printf("Updated: %s", data.Updated)
gcsURI := "gs://" + data.Bucket + "/" + data.Name
client, err := bigquery.NewClient(ctx, PROJECT_ID)
if err != nil {
return fmt.Errorf("bigquery.NewClient: %v", err)
}
defer client.Close()
// Insert data into BigQuery
gcsRef := bigquery.NewGCSReference(gcsURI)
gcsRef.SourceFormat = bigquery.CSV
gcsRef.SkipLeadingRows = 1
gcsRef.Schema = bigquery.Schema{
{Name: "string", Type: bigquery.StringFieldType},
{Name: "int", Type: bigquery.IntegerFieldType},
{Name: "float", Type: bigquery.FloatFieldType},
{Name: "date", Type: bigquery.DateFieldType},
{Name: "datetime", Type: bigquery.DateTimeFieldType},
}
loader := client.Dataset(DATASET_ID).Table(TABLE_ID).LoaderFrom(gcsRef)
job, err := loader.Run(ctx)
if err != nil {
return fmt.Errorf("loader.Run: %v", err)
}
status, err := job.Wait(ctx)
if err != nil {
return fmt.Errorf("failed to load data: %v", err)
}
if status.Err() != nil {
return fmt.Errorf("job completed with error: %v", status.Err())
}
log.Printf("Job completed successfully")
return nil
}
go.mod
module example.com/gcf
go 1.23.1
require (
cloud.google.com/go/bigquery v1.66.0
github.com/GoogleCloudPlatform/functions-framework-go v1.9.1
github.com/cloudevents/sdk-go/v2 v2.15.2
)
Discussion