
はじめに
本記事ではABCI ハッカソンで実施した日本語 VLM(Vision-Language Model)作成の取り組みについて紹介します。ABCI 3.0を活用したVLMの学習に関する内容であり、以下の読者を想定しています。
- ABCI ハッカソンの概要を知りたい方
- ABCI 3.0でVLMの学習がどの程度高速化できたか知りたい方
ABCI 生成AIハッカソン
ABCI 生成AIハッカソンは2025年2月4日から2月13日にかけて開催された生成AIモデルの開発や最適化を目的としたイベントです。
主催は産業技術総合研究所(産総研)で参加者は 「ABCI 3.0」(H200 GPUを搭載) を無料で利用できます。具体的には期間の10日間、SSHでABCIのログインサーバーにアクセスし、データのダウンロードや依存ライブラリのインストールなどの環境構築を行い、割り当てられたH200 GPU搭載の計算ノードで自由にスクリプトを実行できます。
深層学習や自然言語処理のスペシャリスト及びNVIDIAのエンジニアがチューターとして参加しており、専用のSlackチャネルで質問を受け付けてくれ、サポートを受けながらモデルの性能向上や効率化に取り組むことができます。
3人程度のチームでの参加を対象としており、参加チームに対して以下の計算資源が提供されます:
より詳しい情報は下記の公式サイトをご確認ください。
ABCI 3.0 生成AIハッカソン公式ページ
ABCI 3.0
ABCI(AI Bridging Cloud Infrastructure: AI橋渡しクラウド)は産総研が運営するAI向け計算インフラです。プリペイド制(前払い方式)で利用したCPU/GPUの時間やストレージの容量に応じて料金が決まります。
ABCI 3.0は2025年1月にABCI 2.0からアップグレードしたものであり、計算能力やストレージ性能が大幅に向上しています:
- 高性能GPUの搭載:最新のNVIDIA H200 SXM5 GPUを6,128基搭載し、半精度で6.2エクサフロップス、単精度で3.0エクサフロップスのピーク性能を実現
- 大容量・高速ストレージ:物理容量75PBのオールフラッシュストレージシステムを採用し、従来比で容量・読み書き性能ともに2倍以上の向上を達成
より詳しい情報は下記のABCI 3.0の技術的詳細や利用方法が書いてるユーザガイドをご確認ください。
ABCI 3.0ユーザガイド
ハッカソンでの取り組み
我々のチームはVLMの学習速度の性能比較を目的として本ハッカソンに参加しました。具体的には、TuringがGENIAC 2期で使用しているAWS環境と比較してABCI 3.0でVLMの学習がどれほど高速化できるかを検証することを課題としました。
VLMを継続事前学習
NVILA
VLMのモデルアーキテクチャはNVILAを採用しました。NVILAはLLaVA-1.5をベースとしたVLMであるVILAを改良したもので、アーキテクチャとしては高解像度画像入力とトークン圧縮の工夫を追加しています。
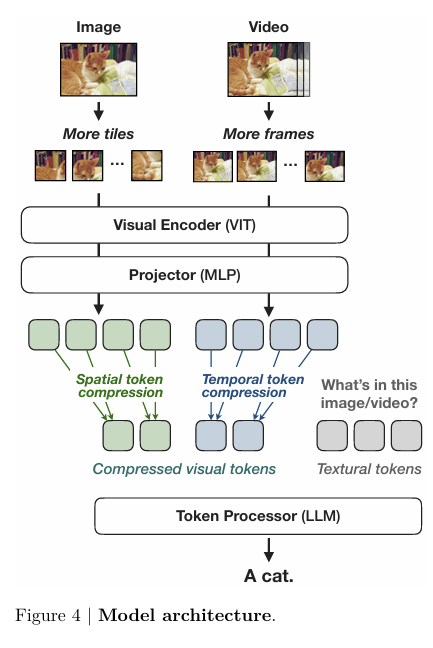
NVILAの学習コード(GitHub: NVlabs/VILA)は公開されており、本ハッカソンではこの学習コードを活用しました。本家のコードでは分散学習ライブラリとしてDeepSpeedを使用しているため、同様にDeepSpeedを採用しました。ハッカソンの期間は10日間と限られているため、学習の高速化が重要となり、計算コストを抑えるために比較的小規模なLLMを使用しました。
使用したアーキテクチャの構成要素とDeepSpeed の設定は以下の通りです。
オープンソースの日本語・英語データセットで学習
オープンソースの日本語・英語データセットを用いてVLM の継続的な事前学習を行い、モデルの性能向上を目指しました。NVILAの論文では5ステージの学習(学習データや学習率を段階的に変更し、計5回の学習を実施)を採用しています。しかし、5ステージ学習に対応する日本語データの確保が困難であったため、前身であるVILAの3ステージ学習を採用しました。
以下の表は各学習ステージの概要です。
| 学習ステージ | 役割 | 学習内容 | データ件数 |
|---|---|---|---|
| Stage 1 | Alignment | Projector のみ学習 | 約 1.1M |
| Stage 2 | Pretraining | Projector と LLM のみ学習 | 約 12M |
| Stage 3 | Supervised Fine-tuning | Vision Encoder, Projector, LLM すべて学習 | 約 2.7M |
以下の表は各学習ステージで使用したデータセットです。
| 学習ステージ | 言語 | データセット | データ件数 |
|---|---|---|---|
| Stage 1 | Japanese | Japanese image text pairs | 558K |
| English | LLaVA-Pretrain | 558K | |
| Stage 2 | Japanese | Japanese image text pairs (subset) | 5.7M |
| Japanese | Japanese interleaved data (subset) | 2.0M | |
| English | mmc4-core (subset) | 4.3M | |
| Stage 3 | Japanese | llava-instruct-ja | 156K |
| Japanese | japanese-photos-conv | 12K | |
| Japanese | ja-vg-vqa | 99K | |
| Japanese | synthdog-ja (subset) | 102K | |
| Japanese+English | The Cauldron JA + LLaVA v1.5 Instruct JA + Open_Orca_200k | 2.1M | |
| English | LLaVA Instruct | 158K |
学習中明らかな loss spike(急激な損失の増加)は見られず、なだらかにlossが低下しました。以下が各ステージのtrain lossの推移です。

ABCIで学習実行するためにしたこと
基本的にAWS環境で動作している学習コードはほぼそのまま利用可能でした。しかし、ジョブスケジューラの違いや環境構築の方法が異なるため、以下の対応を行いました。
特に苦労したのは環境構築でした。AWSではvenvを用いて仮想環境を構築していましたが、同じ方法ではABCIでのマルチノード分散学習が失敗しました。サポートのアドバイスを参考に PyTorchのバージョンを変更するなど試行錯誤しましたが問題は解決せず、最終的にSingularityを用いたコンテナ環境を構築することにしました。ABCIでは Singularityを利用可能であり、コンテナ環境を整備したことでマルチノードの分散学習が正常に動作するようになりました。
AWSのH100との性能比較
ハードの障害なのか割り当てられた4ノードすべてではジョブ実行ができなかったため、2ノードだけを使用してGLOBAL_BATCH_SIZE(全GPU合計のバッチサイズ)を統一した条件で実行しました。AWSのH100(VRAM 80GB) に対し、ABCIの H200(VRAM 141GB) はより大容量のVRAMを搭載しているため、学習Stage 2と3では PER_DEVICE_BATCH_SIZE(1GPUあたりのバッチサイズ)をH100の2倍に設定しています。
ABCIの方が有利な条件での比較となり、実際 ABCIの方が学習速度が速いことが確認されました。以下の表は各ステージでの1エポックあたりの学習時間です。
| 学習ステージ | 1epの学習時間: ABCI (H200) | 1epの学習時間: AWS (H100) | 備考 |
|---|---|---|---|
| Stage 1 | 約 2.9 hour | 約 3.3 hour | ABCI, AWSどちらもPER_DEVICE_BATCH_SIZE=8 |
| Stage 2 | 約 51 hour | 約 70 hour | ABCIはPER_DEVICE_BATCH_SIZE=8, AWSはPER_DEVICE_BATCH_SIZE=4 |
| Stage 3 | 約 17 hour | 約 25 hour | ABCIはPER_DEVICE_BATCH_SIZE=8, AWSはPER_DEVICE_BATCH_SIZE=4 |
ABCIとAWSの詳細なスペックは以下です。
| 項目 | ABCI | AWS(P5.48xlarge) |
|---|---|---|
| CPU(2Socket) | Intel Xeon Platinum 8468 Processor 2.1 GHz, 48 Cores(Total: 96Cores/192Threads) | AMD EPYC 7R13 Processor 2.65GHz,48 Cores(Total: 96Cores/192Threads) |
| Memory | 64 GB DDR5-4800 x 32 (Total:2048GB) | 2048GB |
| SSD | NVMe SSD 3.2 TB x 4 | NVMe SSD 3.84TB x 8 |
| Interconnect | InfiniBand HDR (200 Gbps) x 4 (Total: 800Gbps) | AWS EFA (100Gbps) x32 (Total:32,000Gbps) |
| Storage | DDN Lustre | FSx for Lustre (40,800MB/s) |
Heron VLMリーダーボードで性能評価
Heron VLM リーダーボードはW&B Japanが構築・運営する日本語VLMの性能を評価するためのプラットフォームです。このリーダーボードでは以下の2つのベンチマークデータを用いてモデルの評価を行います。
- Heron Bench:日本の文化的文脈を反映した画像と質問のペアデータセット
- LLaVA Bench (In-the-Wild): LLaVA Benchの日本語版
今回学習したモデルをHeron VLM リーダーボードで評価しました。各評価スコアは以下のとおりです。
| Average Score | ave_heron | ave_llava | heron_conv | heron_detail | heron_complex | llava_conv | llava_detail | llava_complex |
|---|---|---|---|---|---|---|---|---|
| 3.930 | 4.283 | 3.576 | 4.524 | 4.095 | 4.231 | 3.313 | 3.667 | 3.750 |
カラムの説明
- Average Score: 総合平均, ave_llava_itw と ave_heron の平均値
- ave_heron: Heron Bench のスコア3種の平均
- ave_llava: LLaVA Bench (in the wild) のスコア3種の平均
- サフィックスの説明
- _conv, Conversation (会話):
画像に関する質問と回答からなる対話データです。オブジェクトの種類、数、動作、位置、オブジェクト間の相対的な位置などの視覚的な内容に関する多様な質問が含まれています。明確に答えられる質問のみを対象としています。
- _detail, Detailed description (詳細な説明):
画像の詳細な説明を生成するための質問リストです。
- _complex, Complex reasoning (複雑な推論):
上記の2つのタイプは画像の視覚的な内容自体に焦点を当てていますが、これらの情報を基にさらに掘り下げた推論を行う質問を作成しています。回答には通常、厳密なロジックに従った段階的な推論プロセスが必要とされます。
以下のグラフは学習したモデルと他のVLMの評価スコアを比較したものです。縦軸がave_heron, 横軸はave_llavaを表しています。学習したモデルは LLaVA Benchのスコアがやや低いものの、Heron Benchのスコアはgemini-1.5-flashと同程度の性能を示しました。 グラフで強調した赤い点(NVILA-Lite_3b_abci)が学習したモデルです。

まとめ
ABCI 3.0でNVILAを用いたVLMの学習から性能評価まで行い、学習速度はAWSのH100と比較して ABCIのH200の方が2〜3割速いことが確認できました。ノード障害や環境構築の問題に直面しましたが、それを通じてABCI 3.0を理解する機会となりました。
本プロジェクトを通じて大規模計算環境の活用に関する貴重な経験を得ることができました。このような貴重な機会をいただき、ハッカソンの関係者の方々に心より感謝を申し上げます。
最後に宣伝ですが、私の所属するチューリングの生成AIチームは、自動運転への活用を目指してVLMや動画生成モデルなどさまざまな基盤AIの開発を行っています。この記事を読んで興味を持っていただけた方は、ぜひ一緒に働けることを楽しみにしています。
詳細については、X(Twitter)のDMにご連絡いただくか、チューリングの採用情報をご覧ください。

Discussion