
【NTT tsuzumi Open Days~キャリア編~】 LLM独自モデル開発リーダーに聞く! LLM開発を成功へと導く“生成AI時代のLead Engineerの条件”とは?
NTT株式会社は、大規模言語モデル「tsuzumi」の開発現場を紹介するオンラインイベント「NTT tsuzumi Open Days~キャリア編~ LLM独自モデル開発リーダーに聞く!LLM開発を成功へと導く"生成AI時代のLead Engineerの条件"とは?」を開催した。 海外の巨大モデルが次々と登場するなか、同社はなぜ独自開発にこだわるのか。目まぐるしく変わる技術動向、100%がない世界での意思決定、そして専門外からでも飛び込める組織──。生成AI時代を迎えた今、大規模言語モデル・LLM開発の現場で求められるエンジニア像とは何か。アーカイブ動画
基調講演:LLMをつくっているのは、どんなエンジニア?-NTT tsuzumiの事例-
NTT株式会社 人間情報研究所
主幹研究員
甘粕 哲郎(あまかす・てつお)氏

海外の巨大モデルが次々と登場するなか、なぜ日本企業は独自にLLMを開発するのか──。NTT株式会社が開発する大規模言語モデル「tsuzumi」のグループリーダーを務める甘粕氏が、LLM開発の最前線で求められるエンジニア像と、40年以上にわたる自然言語処理研究の蓄積を武器に挑む開発現場のリアルを語った。
40年の積み重ねが生んだ国産LLM「tsuzumi」
甘粕氏: 私は1999年に当時の日本電信電話株式会社のサイバースペース研究所に入社し、音声対話システムやコンタクトセンター向け音声認識など、人とAIのコミュニケーション領域を長く研究してきました。事業会社ではスマホ電話アプリ「050 plus」の開発にも関わり、AI開発と非AI開発の両方を経験しました。現在はNTT人間情報研究所で、LLM「tsuzumi」の研究開発を進めています。

ここから話題は、本題である同社の自然言語処理技術の研究開発について。
同社は、1980年代から日本語の自然言語処理を研究してきた。ディープラーニング時代には日本語に特化したNTT版BERTを独自技術としてリリース。2023年11月にNTT版LLM「tsuzumi」を発表。その半年後に商用提供を開始した。
甘粕氏:「tsuzumi」というのは、日本の伝統楽器「鼓」のように小さくてもよく響く、そんなイメージを込めています。日本語を40年以上研究してきた蓄積から、日本語に強いモデルをつくろうという目標を掲げました。さらに小型で柔軟にチューニングできること。1GPUで動作しながら高性能を発揮するモデルを目指しています。
小型・高性能モデル「tsuzumi」の開発思想
甘粕氏:NTTが目指したのは、お客さまのデータを安全に扱いながら実環境で動かせること。そのために、「1GPUで動作」「日本語特化」「オンプレでの利用」を前提に設計しています。

甘粕氏:和楽器の鼓は、打楽器のなかでも比較的小さく、美しく調律できる楽器です。装飾には金や革が使われ、見た目の美しさも特徴的です。実はこの美しさという視覚的な要素にも意味があります。私たちは早い段階から、テキストだけでなく、文書中の図表や写真なども含めて理解・対話できるマルチモーダルモデルの研究を進めてきました。そうした実績を「tsuzumi」の特徴に重ね、名前にも込めています。
甘粕氏:また、お客さまのなかには、機密性の高いデータをネットワーク越しに扱うことを避けたい方がいらっしゃいます。オンプレミスで動かせる小型モデルであれば、そうした現場でも安心して導入できます。
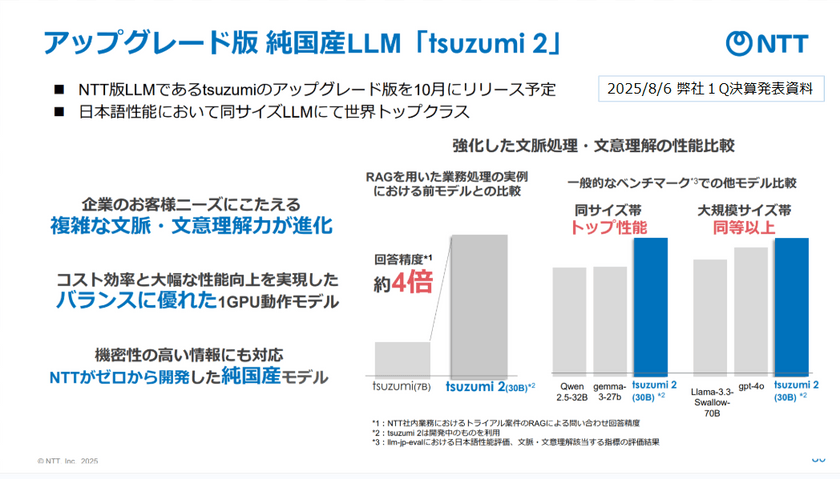
2025年秋に公開予定の「tsuzumi2」は、同サイズ帯のモデル中トップクラスの性能を示し、一部のベンチマークでは「GPT-4o」を上回る結果も報告されている。しかも、同社が事前学習から自ら手がけた準国産モデルだ。
スクラッチ開発とLLM開発のプロセス
ここで、甘粕氏はLLMが同社でどのように開発されるか説明した。
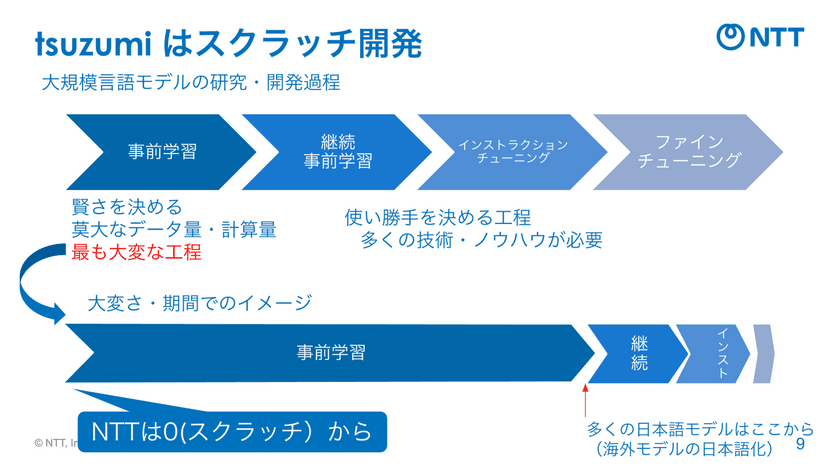
甘粕氏:LLMの開発は大きく4つの工程で構成されています。最初に、モデルの賢さを決める事前学習があります。ここで膨大なデータと計算量を使って基礎能力を培います。次に、用途や言語特性に合わせて知識を追加する継続事前学習。例えば日本語をより強化したり、特定領域の知識を埋め込んだりします。
甘粕氏:その後、実際に人と自然にやり取りできるようにするためのインストラクションチューニングを行い、最後にお客さまのタスクやドメインに特化させるファインチューニングを実施します。これらの工程はすべて、モデルの使い勝手を決める重要なフェーズであり、それぞれに多くのノウハウと技術が求められます。
甘粕氏:そのなかでも最も開発が大変なのは、最初の事前学習です。感覚的にいえば、開発エネルギーの4分の3を費やす部分ですね。多くの他社モデルは海外モデルをベースに日本語データで継続学習をしていますが、NTTはゼロから事前学習を行っています。

一方で、LLMの進化スピードは驚異的だ。
甘粕氏:2025年前半だけでも、1月に「DeepSeek」、2月に「GPT-4.5」、3月に「Llama 3」、4月に「Meta」の新シリーズと、次々に大型発表がありました。さらに、毎日のように新しいモデルやコードが公開される。その波に追いつきながら開発を続けるのが現場のリアルです。
100%がない世界で問われるリーダーシップ
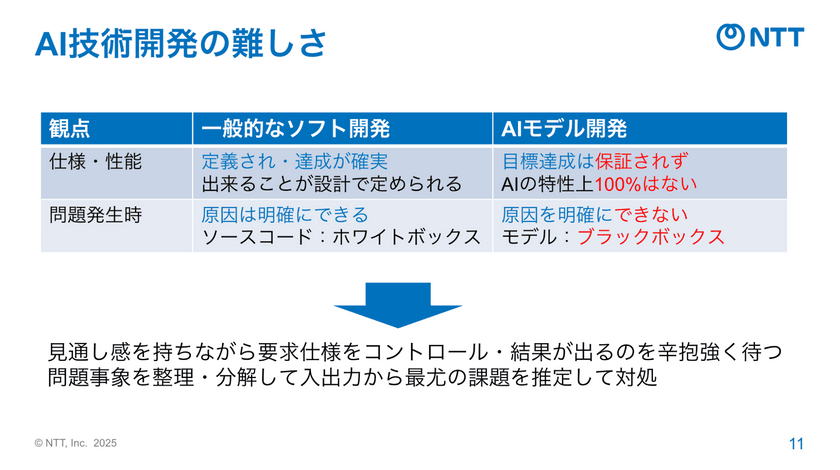
甘粕氏:AI技術開発の難しさは、このスピード感だけではありません。一般的なソフトウェア開発と違って、AIモデルには「理論的に正しさを保証できない」という本質的な難しさがあります。モデルは膨大なパラメータの集合体であり、その相互作用をすべて予測することはできません。問題の原因を完全に明確にできない世界なんです。
その不確実な世界といかに向き合うのか。
甘粕氏:見通しの不確実さを受け入れ、仕様をコントロールしながら結果が出るのを辛抱強く待つ。問題が起きたときは、入出力の関係を整理し、仮説を立てて検証する──。そういった対処しながら日々、我々は研究開発を進めています。
甘粕氏:こういった背景から、AI開発のリーダーに必要なのは、モデル開発から導入までの工程全体への好奇心、最新情報を追う習慣、そして不確実性を受け止める胆力です。多角的に分析し、仮説思考で問題を対処しながら前に進む人が求められます。
なぜNTTは、独自開発にこだわるのか
最後に甘粕氏は、チャレンジングなLLM開発に、同社がなぜ向き合うのか、改めて語った。

甘粕氏:まず、すべての学習データを自分たちでコントロールできる点があります。著作権やバイアスの問題にも一人称で対応できますし、基盤モデルのライセンス条件の変更に振り回されることもありません。
甘粕氏:何より、日本を代表する技術開発機関として、ゼロから開発してお客様に届ける。その全工程を自前で責任を持って進めること、そのスキルを身につけることに価値があると思っています。改めて、日本語のLLMを基盤モデルから国産で育てることに意義を感じています。こうした思いに共感していただける方は、ぜひ一緒に挑戦しましょう。
【現在募集中の経験者採用職種】
ライトニングトーク①:LLM開発は一般的なソフトウェア開発とココが違う!
NTT株式会社 人間情報研究所
主任研究員
本間 幸徳(ほんま・ゆきのり)氏

最新の技術を取り込みながら、社会で安心して使える信頼性も確保する──。この相反する課題の間で、どのように開発を進めるのか。NTT人間情報研究所で大規模言語モデル「tsuzumi」の学習・推論システムを統括する本間氏が、LLM開発の現場で得た知見を語った。

フルスクラッチでLLMを開発する希少性
本間氏: 私はNTTに入社後、情報抽出などの研究に携わり、その後、事業会社で商用サービス開発を経験しました。現在は独自LLM「tsuzumi」の学習・推論ツールの構築を担当しています。ゼロからモデルを学習するチームは国内でなかなかなく、貴重な経験をさせてもらっていると思っています。
本間氏: 我々の研究所では「tsuzumi」というゼロから学習をしているスクラッチの言語モデルの開発を進めています。2025年10月に次世代モデル「tsuzumi2」をリリース予定で、約30億のモデルとして準備を進めており、推論でも1GPUで動作し、学習でも1ノードで動作可能。日本語性能は世界トップクラスを記録しており、利用者にとって無理のないバランスを重視しています。
LLM開発における相反する課題:技術進歩のスピードと信頼性
ここから本間氏は、LLM開発における課題について、本間氏は2つの相反する要求を挙げた。
⚫︎技術の進歩が非常に速い

本間氏: まず、技術の進歩がとても早いです。LLM開発の世界は、技術の進歩が本当に速いと日々感じています。例えば「リーズニングモデル(推論モデル)」という言葉は、2024年9月にOpenAI社が「o1-preview」を発表したことで注目されました。その後わずか半年のうちに各社が次々と同系統のモデルを公開し、今では一般的な技術として浸透しています。

本間氏:さらに、入力テキストの前処理を自動化するchat_template技術も、2023年10月HuggingFace社のライブラリに導入されて以降、継続的に機能が追加・アップデートされている状況です。このように技術の進歩に合わせて最新機能をソフトウェアに取り入れるには、どうしても開発期間を短くして追随しなければならないわけです。
⚫︎NTT株式会社として高い信頼性が求められる

本間氏: 2つ目の課題は、NTTとして高い信頼性が求められることです。事業会社と連携してさまざまな商用サービスに用いられること、さらに頻繁なアップデートを前提としない運用環境で、リリース段階から信頼性が求められることから、従来のソフトウェア開発と同じように、厳格な検証と十分な試験期間を設けるプロセスを維持する必要があります。このように、「スピード」と「信頼性」と相反する要素を両立しなければならないことが、まさにLLM開発の難しさでした。

この2つの課題に、同社ではどのように立ち向かっているのか。
本間氏:急速な技術革新に追随する一方で、品質も確保するために「できることはやってみよう」と試行錯誤してきました。OSSを軸に設計し、単体試験まではスピード重視で機能を取り込みながら、最終段階では十分な試験期間を確保する。さらに、事業会社でプロトタイプを試してもらい、フィードバックを反映するなど、色々と試してきました。
本間氏:魔法のような解決策は見つかりませんでしたが、取り組みを進めるうえで大切なのは「誠実な翻訳者」としてのスタンスだと考えています。つまり、最先端の技術を正しく理解し、それを使う人に分かりやすく伝えること。この姿勢を貫くことを開発で重視しています。
技術知見を磨き、利用者視点で伝える
「誠実な翻訳者」としてのスタンスを取るべく、技術知見をつけ、利用者に分かりやすく伝えること。ここからは、本間氏がこの両輪をどのように回してきたかを説明した。
⚫︎「翻訳元」である技術・知識を理解する

本間氏: 技術を正しく理解するためには、まず基礎理論をしっかり身につけることが何より大切だと感じています。LLMの分野では自然言語処理、ベイズ統計、機械学習といった基礎分野を体系的に学んでおくと、論文や新技術が何を狙っているのか、どんな背景で提案されたのかをすぐに理解できるようになります。

本間氏: 理論を押さえれば、研究成果を現場でどう生かすかを自律的に判断できるようになります。開発中、OSS上の学習処理でバグが見つかったときも、その修正によって性能がどの程度変わるか、どこまで手を入れるべきかを冷静に見極められました。

本間氏: もう一つ大切なのが、研究者と対話することです。研究論文を公開するオンラインサーバ「arXiv(アーカイブ)」や国際会議の動向を定期的にウォッチしつつ、社内では研究者とエンジニアがコミュニケーションツール「Slack」や勉強会で頻繁に技術議論をしています。論文やコードだけでは読み取れない研究の意図を理解できるのは、こうした直接のコミュニケーションがあるからこそ。研究側がこれからどんな方向に進もうとしているのかを共有できれば、開発側もその方針を踏まえて機能を設計できます。
⚫︎利用者に分かりやすく伝える

本間氏: もう一つ大事にしているのが、「分かりやすく伝える」ことです。「tsuzumi」では、機能説明だけでなく、実際の利用シーンを想定したマニュアルづくりに力を入れました。ユーザーがどんな目的で、どのようにモデルを使うのかを踏まえて、学習データの作り直し方や継続事前学習の順序、運用のポイントまでを具体的に整理しています。このマニュアルはNTTグループ全体で共有し、誰もが同じ水準でモデルを扱えるよう工夫しました。

本間氏: また、開発チームとしては、利用者の視点でプロダクトを見ることを常に意識しています。LLMは精度や動作が環境によって微妙に変化します。不具合発生時も、出力結果を細かく確認しながら、研究所の環境と同等の精度を利用者側でも再現できるよう改善を重ねてきました。

本間氏: さらに、デフォルトパラメータの適切な設定と説明にもこだわりました。LLMごとに最適値は異なりますが、スクラッチ学習で得た「tsuzumi」固有のノウハウを整理し、最も汎用的かつ安定した値を探索しました。利用者は、まずこのデフォルト設定で迷わず最良の状態から使い始められる。一方で、上級ユーザーは用途に合わせて細かく調整できる――そんな柔軟性を設計段階から意識しています。
最先端の研究を「使える技術」に変える

最後に本間氏は、LLM開発で大切にしていることをまとめた。
本間氏:「tsuzumi」の開発では、ファインチューニングや推論を現実的なコストで実現できるよう、バランスの良いモデルサイズを追求しました。その結果、日本語性能は世界トップクラスを記録し、研究としても、実用としても誇れる水準に到達できたと思っています。
本間氏:そして、それを支えるツール群についても、最新技術を分かりやすく伝え、安心して使ってもらうことを大切にしてきました。そうした工夫を積み重ねたことで、NTTグループ全体で共通の環境を整え、各事業領域に「tsuzumi」の技術を広く展開できる基盤ができたと感じています。最先端の研究を現場につなぎ、実際に使える形で届ける。それが私たちエンジニアの役割であり、これからも大切にしていきたい姿勢です。
ライトニングトーク②:正直、NTT研究所に入社してみてどうだった?
NTT株式会社 人間情報研究所
研究員
野沢 綸佐(のざわ・つかさ)氏

挑戦的な研究開発に携わりながら、自分らしいキャリアも描ける環境とは?NTT株式会社人間情報研究所で視覚言語モデル「tsuzumi」の研究開発に取り組む野沢氏が、経験者採用で入社して半年。転職の決め手、研究開発現場のリアル、得られる成長機会やキャリアステップの3点を中心に、率直に語った。
「挑戦できるR&D」を求めて──NTTへの転職を決意した理由
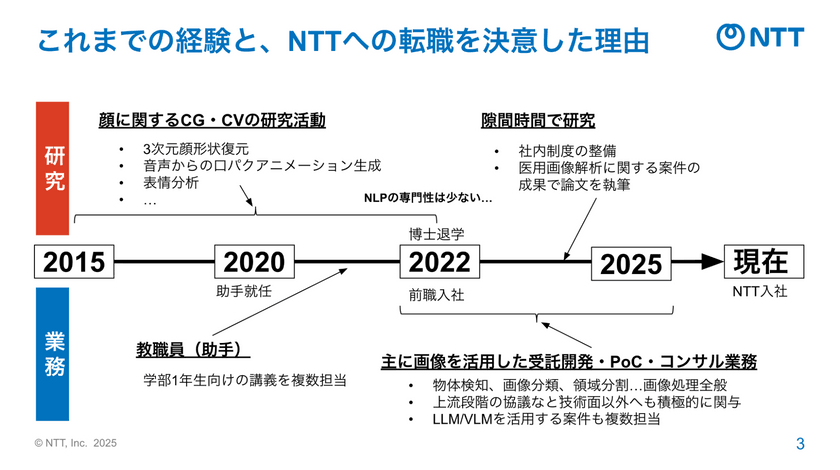
まず野沢氏は、自身のこれまでのキャリアを示した。
野沢氏:もともと、大学の研究室で約10年前から人間の顔に関するCGやCVの研究を専門に行ってきました。修士を卒業して博士に入学する過程で、大学で先進理工学部 応用物理学科の教職員としても勤務していました。
野沢氏:その後、一度博士を退学し、株式会社エクサウィーズに入社し、機械学習エンジニアとして動画像を扱うPoCやコンサル業務に従事していました。2025年の3月に、NTT株式会社に中途入社し、「tsuzumi」の研究開発グループに所属し、主に視覚言語モデル・VLMの研究開発を担当しています。
ここで、NTT株式会社に入社した背景が明かされる。
野沢氏:前職ではスピード感を持って楽しく仕事していましたが、短期的な成果を優先するなかで挑戦的な社内R&Dが難しいことにモヤモヤを感じていました。さらに、LLMやVLMのようなモデルを自社でゼロから学習するにはリソースが足りない壁もありました。それらに加え、将来的に復学して研究に戻りたいという思いを持っていたこともあり、挑戦的な研究と長期的な開発・キャリア形成が実現できる次の環境としてNTT株式会社の人間情報研究所を選びました。
研究者としての挑戦に専念できる環境──研究現場のリアル
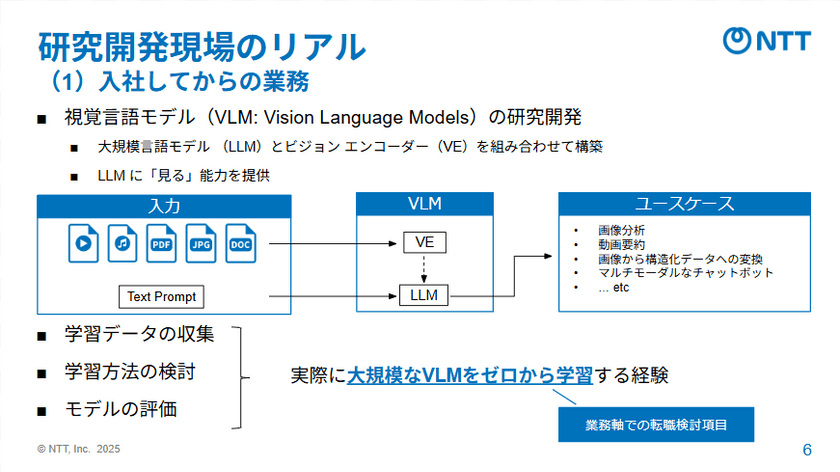
ここから話題は、研究開発現場のリアルに移る。転職後の働き方についても、野沢氏は率直に語った。
野沢氏: 現在は、VLMの研究開発を担当しています。データ収集から学習設計、モデル評価まで一通りを担当しており、まさに「ゼロから大規模モデルをつくる」という経験をしています。以前からやってみたかった挑戦的なテーマに、今まさに取り組めているということです。
野沢氏: 働き方はフルリモート・裁量労働制(年次によっては適用外)で、柔軟性が高いです。家庭や生活の事情にも理解があり、100%在宅で研究を進められます。
野沢氏: また、大企業ならではだと思いますが、職位ごとの役割や責任の所在が明確で、心理的安全性が高いと感じています。自分の裁量で判断できる部分は積極的に提案でき、上長とのすり合わせが必要な場合でも挑戦的な提案がしやすいのが魅力です。
野沢氏: 私は短期的には、さらにエンジニアリングのスキルを経験し、最終的にマネジメントに携わりたいというキャリアを描いています。上長とすり合わせて、開発業務に専念させてもらっているのですが、実際にこれまで資料作成を含むペーパーワークはほとんどありませんでした。
リモート環境だからこそ積極的にコミュニケーションを取りに行く

ここからは、入社後に野沢氏がどのように組織に馴染んでいったかを振り返った。
野沢氏: 実は、自然言語処理は専門外で実装の経験がない、ほぼ初心者の状態で入社しています。最近はライブラリがとても充実しているので、とにかく手を動かして実装しながら学び、分からない部分は優秀な同僚にじっくり質問して吸収するようにしています。
野沢氏: リモート勤務の会社であればよくある課題だと思いますが、対面で議論できない分、コミュニケーションコストは多少かかります。ですが、迷惑にならない範囲で会議を設定したり、オープンな場に積極的に参加したりして、意識的に情報を取りに行くようにしています。
野沢氏: 私自身、小さな会社から大きい会社に移ることで、スピード感が落ちたり、複雑な社内システムがあったりとさまざまな制約があるのでは、という点に最も不安を感じていました。しかし、実際には、システム面では多少の慣れは必要だったものの、研究開発に支障を感じることはほとんどありません。
「100%目標が達成できると思える」人間情報研究所で働く魅力

最後に野沢氏は、同社の人間情報研究所で働く魅力を改めてこう語った。
野沢氏: 入社して半年たちますが、一言で言えば「転職して良かった」です。短期的には開発のみに注力させてもらえているので技術を磨けていますし、長期的にも出向やPoCなどを通じてキャリアを広げるチャンスが多いと感じます。また博士復学を希望する場合にもそれをさまざまな形で支援してもらえる制度があり、このまま努力すれば自分の目標は100%達成できるだろうと思えています。
【Q&Aセッション】
Q&Aセッションでは、ここまでで登壇した3名(甘粕氏・本間氏・野沢氏)が、イベント参加者から寄せられた質問に回答した。
Q. NTT株式会社のR&Dでは、どのような体制でLLM開発を進めているか?
甘粕氏: 以前は自然言語処理の分野ごとにチームを分けていましたが、現在は1つの組織に集約しています。LLMは応用範囲が広いため、各分野の知見を持ち寄って一体となって開発を進めています。
Q. LLMの領域には巨大先駆企業があるなかで、NTT株式会社はどのような領域に需要を見出しているか?
甘粕氏: 私たちは日本のDXを支える基盤として、金融・医療・地域の公共団体など、データを外部に出しづらい分野のお客さまをメインターゲットとして想定しています。そのため、「tsuzumi」ではスクラッチ学習の際からそういったお客様を意識したデータキュレーションを行い、オンプレミス環境で安全に動作するLLMを開発するなど、そうした業界に向けた導入を意識して進めています。
Q. 技術の進化が速いなかで、研究者の皆さんはどのように最新情報をキャッチアップしているか?
本間氏:「arXiv」で自動的に新しい論文が入ってくるように設定してチェックしたり、SNSで専門家の発信を追ったりしています。研究所の「Slack」でも情報共有が活発で、その辺りから逐次情報を集めて、どれを使うかキャッチアップしています。
野沢氏: 私も本間さんとほとんど同じで、地道にやっていくのが一番の近道だと思います。社内の情報を積極的に見に行く、「arXiv」を逐一チェックする、国際学会のリストを見る、そして研究のインフルエンサー的な方の投稿を頻繁にチェックする。主にこの3つですね。
甘粕氏:弊社の LLM開発には多くの専門性を持ったメンバーが関わっており、社内での情報共有も非常に密です。お互いの知見をもとに、常にキャッチアップしながら開発を進めています。
Q. フルスクラッチのLLM開発は時間がかかると思う。開発途中で新たなモデルが登場して方向性が急遽変わるなど、苦労話はあったか?
甘粕氏: 新しいモデルが出ると確かに驚くこともありますが、まずは新モデルを徹底的に分析します。弊社では評価専任のチームがあり、早速性能を検証したうえで、実際のレベル感を確認しています。
ただ、技術だけでソリューションの優位性が決まるわけではない、というのが私の持論です。お客さまとの関係性や課題解決の力も含めて開発力・提案力だと考えています。技術トレンドを追いつつも、ビジネスの目的を明確に据えて研究・開発を進めています。
Q. コーディングで生成AIを積極的に活用できる環境になっているか?
野沢氏: 私自身はあまり使っていませんが、活用しているチームメンバーが大半を占めています。主に「Microsoft Copilot」を活用していて、アイデアを実現するまでのリードタイムが短くなっています。
本間氏: 私も「Microsoft Copilot」を活用しています。会社的にも使える環境が整っていて、開発の速度を上げるのに役立っています。特にテキスト解析やバグの修正で便利に使っています。
Q. 公開済みのモデルを分析する際、オープンウェイトとオープンソースではどのように分析手法が異なるか?
本間氏: この2つに分けて分析しているわけではないですね。どちらかというと、より競争力のあるモデルに着目して分析しています。例えば「Llama」なら、どういう方法で学習すれば数値が上がっているのか、どういう学習データを使っているのかといった視点です。より良いレシピが公開されていればそれを評価対象にしますし、特定の学習データが使われていれば、それを加えてみるといった形で検討を進めています。
採用情報
NTT研究所では現在、「tsuzumi」シリーズをはじめとするAI・自然言語処理技術の研究開発に携わるっていただける仲間を募集しています。
【募集職種】
その他の経験者採用情報はこちら:NTT R&D 経験者採用
文=宮口 佑香(パーソルイノベーション)
※所属組織および取材内容は2025年9月時点の情報です。
おすすめイベント


関連するイベント

【NTT tsuzumi Open Days~キャリア編~】 LLM独...
2025年10月01日 (水)おすすめの記事






