
野村総合研究所の社員1万人が活用するセキュアな社内生成AI 環境のつくり方
もはや企業においてAI活用は当たり前になりつつある。野村総合研究所(以下、NRI)では2023年4月頃から、生成AIの本格活用を開始。全社展開するため構築した社内AI基盤は1万人以上の社員が累計1000万回以上の利用実績があるという。NRIではどのようにAI活用を進めていったのか。全社戦略までのロードマップ、ガバナンス体制などの仕組みや文化づくりから、大人数に使ってもらうための具体的なサービス設計の方法などについて、全社基盤構築に関わった3人のエンジニアが紹介した。
もはや企業においてAI活用は当たり前になりつつある。野村総合研究所(以下、NRI)では2023年4月頃から、生成AIの本格活用を開始。全社展開するため構築した社内AI基盤は1万人以上の社員が累計1000万回以上の利用実績があるという。NRIではどのようにAI活用を進めていったのか。全社戦略までのロードマップ、ガバナンス体制などの仕組みや文化づくりから、大人数に使ってもらうための具体的なサービス設計の方法などについて、全社基盤構築に関わった3人のエンジニアが紹介した。
アーカイブ動画
1万人が1000万回以上使った!“セキュア社内AI”のつくり方-全社AI推進の戦略と導入経緯
株式会社野村総合研究所
AIソリューション推進部
シニアテクニカルエンジニア
渡辺 圭祐(わたなべ・けいすけ)氏
AI活用は課題を解決するための1つの選択肢
渡辺氏は2019年にNRIに入社したシニアテクニカルエンジニア。現在は幅広い技術スタックを活用して、生産性向上をテーマに活動しており、直近は全社規模でのAI推進活動に従事している。
「私たちの活動としてはAIありきではなく、課題を解決するための1つの選択肢としてAI活用を考えています」(渡辺氏)
NRIが生成AI活用を推進するのは、「AIとともに仕事をすることが当たり前になりつつあること」と渡辺氏。先の時代を見据えると、なるべく早く取り組むことが得策となるからだ。
NRIではGPT-4がリリースされた直後の2023年4月より、全社チャットツールからワンクリックで呼び出せる気軽な業務パートナーとして生成AIの利用を開始した。現在は「AIオーケストレーション設計をして、頼れる同僚へと進化させています」(渡辺氏) AIオーケストレーション設計とは、AIツールを提供するだけではなく、既存の業務を分解・分析し、どの部分にどのような形でAIを組み込むと最も効果的かを設計することである。
今はChatGPT EnterpriseやMicrosoft 365 Copilotなどの生成AIを利用できるSaaSが多数存在している。「それらのツールを使っていくことも大切です」と言いつつも、NRIが独自のインターフェースで運用を続ける理由を次のように明かした。
「利便性と安全性に加え、コストや要件への柔軟な対応力を重視することとなり、総合力として独自の基盤が必要だということになりました」(渡辺氏)
とはいえこうした基盤を独自開発していくには「それなりに体力がないと厳しい」とも吐露する。APIひとつ取っても、1年ほどで非推奨(deprecated)になってしまったり、インターフェースに大きな(破壊的な)変更が入ることがあるからだ。またプロダクトのライフサイクルを伸ばすとともに、どの方向に進化するかを予想してアプリ化することも重要になるという。そこでNRIではLLMが今後も進化し続けることを前提として、インターフェースを設計しているという。
たとえ精度が出なかったとしても、別の切り口を探したり、一定期間後に再実行する柔軟な運用をすることも必要だという。「特にOCR系は飛躍的に性能が上がっています。1年前にうまくいかなかったドキュメントの読み取りが、実用レベルになっていた。そんなことも珍しくありません」(渡辺氏)
どのようなAIプラットフォームを築いたか
NRIでは全社サービスと個別環境構築という2つの軸を設けて生成AIプラットフォームを構築している。「個別環境構築を設けたのは、特定の本部やグループ会社、プロジェクト向けに個別のカスタマイズ機能を入れ、より業務に直結する形で提供するためです」(渡辺氏)
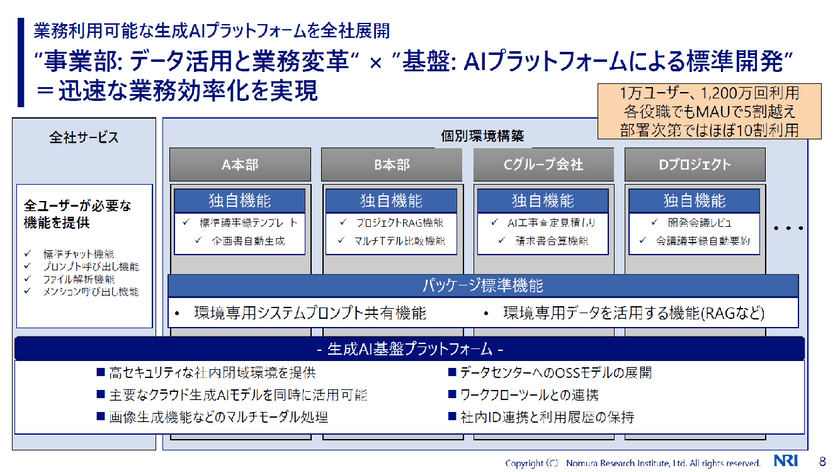
事業部はデータ活用と業務変革を担当し、渡辺氏のチームはAIプラットフォームによる標準開発を行う。このような体制にすることで、生成AI開発を活発に進められるようになっているそうだ。
「実際、1万人超の社員が利用しており、利用回数も累計1200万回を超える基盤となっています」(渡辺氏)
マネージャー層を加えても利用率は5割を超えており、利用率がほぼ10割の部署もあるという。
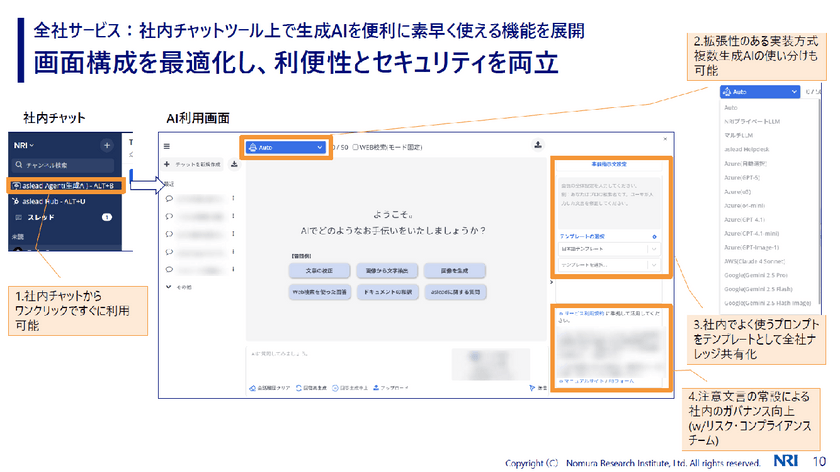
冒頭でも触れたが、全社サービスでは社内チャットツール上で生成AIを便利に素早く使える機能を展開している。「画面構成を最適化して、利便性とセキュリティの両立を重視することにこだわった」と渡辺氏は話す。
それを実現する工夫が4点ある。1点目は社内チャットツールからワンクリックで利用可能にしていること。
2点目は、拡張性のある実装方式を採用し、複数の生成AIの使い分けを可能にしたこと。とはいえ、全社員が自身の判断で使い分けるのは難しい。そこで標準機能として、例えばユーザーが画像生成をしたいときは画像生成用のAIを呼び出し、文章の校正をしたいときには、それを得意とするモデルを呼び出せる仕掛けも整備している。
3点目は、社内でよく使うプロンプトをテンプレートとして共有していること。
4点目は、社内に存在する様々な機微な情報が適切に扱われるよう、注意文言を常に表示するなど、社内ルールやコンプライアンスを守る仕組みを設けていることだ。「仕組みづくりにはコンプライアンスを担当するチームに協力してもらいました」(渡辺氏)
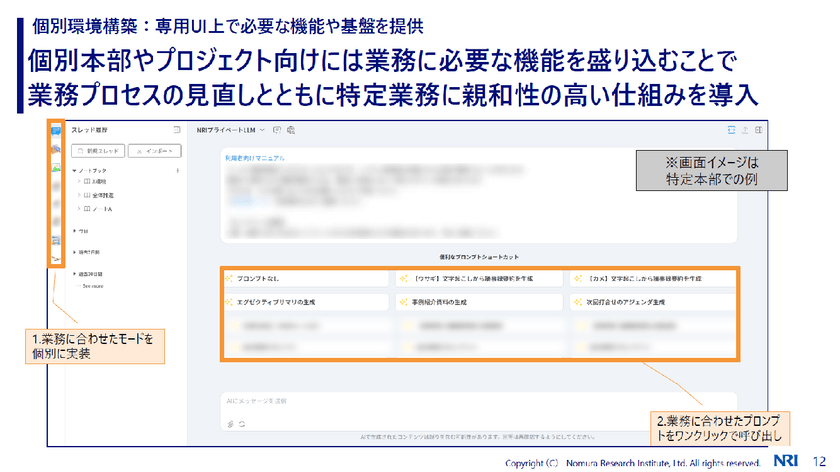
一方の個別環境は、専用のWeb UIに本部やプロジェクトごとのニーズに応じた機能を組み込み、提供している。「業務プロセスを見直し、特定業務用に特化したモードなどを追加して、個別に実装しました」(渡辺氏)
個別環境では一般的なチャット形式でAIに質問をしたり指示を出したりできるのはもちろん、ワークフローとして実行する処理や、特定業務に特化したプロセスを追加できる柔軟な構成になっている。個別環境では組織に合わせて、よく使うプロンプトをショートカットで表示し、それをワンクリックするだけで呼び出せる。通常モードだけではなく、データ参照や画像生成、ワークフロー実行などさまざまなモードを用意し、多様な業務を環境内で完結できるようにしている。例えば、データ参照モードはRAGを利用して構築している。
「資料などはベクトルDBに格納し、検索できるようにしています」(渡辺氏)
単純なRAGを利用するだけではなく、プレビューや元データのダウンロードを可能にするなど、社内データを参照するうえで必要な機能も開発している。さらに継続会話やWeb検索との組み合わせも可能で、AIの検索プロセスも提示できるようにしているという。
データ参照の処理の流れを図にすると次のようになる。
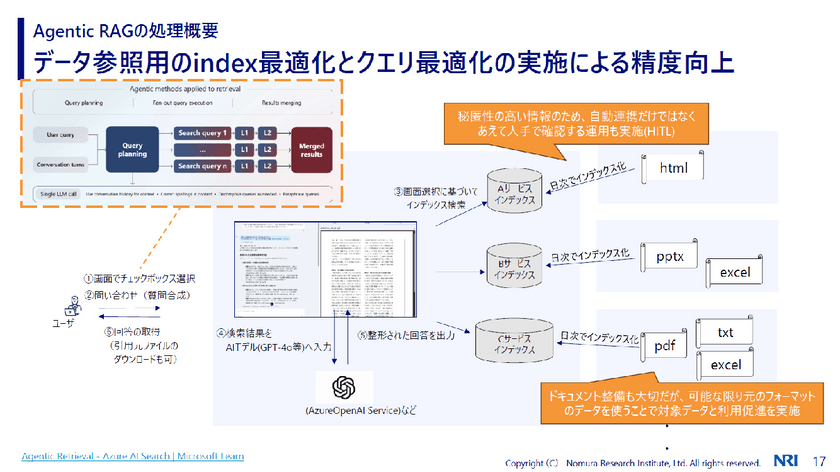
まずユーザーがチェックボックスで検索対象を選択する。すると、問い合わせの質問が合成される。単純なRAGではなくAgentic RAGを提供しているのは、「質問の意図を正しく汲み取るため」と渡辺氏。AIに質問する場合、短文になったり、前提を抜かしたりすることがあるので、単純なRAGだけでは、回答の精度が下がりがちになるからだ。
こうして画面選択に基づいてインデックス検索が行われる。インデックスの作り方について渡辺氏は、「秘匿性の高い情報の場合は、自動連携せず、あえて人手で確認する運用(Human-in-the-Loop)を実施することもあります」と説明する。
その一方で、「ある程度汎用的に作る場合は、ドキュメント整備も大切だが、可能な限り元のフォーマットのデータを使うことを最初から諦めない方が良いと思います」と言う。利用促進につながるからだ。
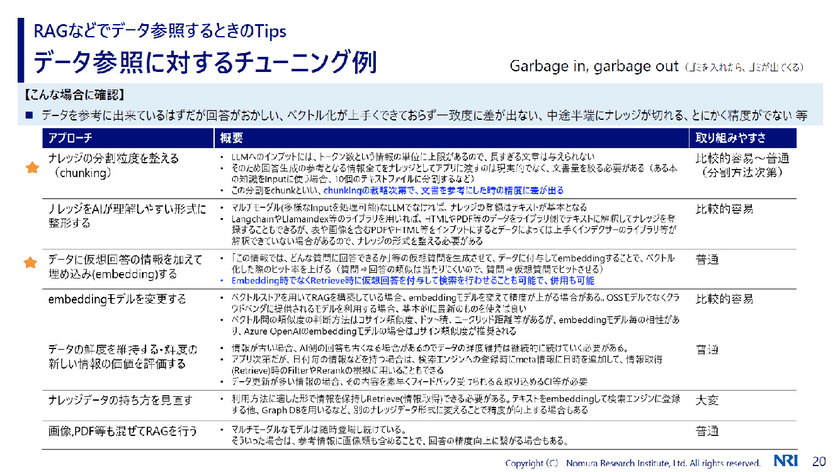
RAGなどでデータ参照するときの主要なチューニングポイントは6点あるという。だがこれから取り組むのであれば、「こういう聞き方をしてほしいというように、まずは利用方法に対するチューニングから進んでいくと良いと思います」と渡辺氏はアドバイスする。
またチューニングは精度向上を目指すために実施するが、「精度を目標にしないことも重要です」と渡辺氏。精度を目標にすると、際限なく求められるからだ。そこで重要になるのが、目指す精度のレベル感とそれをどうやって評価するかの認識合わせをすることである。目指すレベル感の合意をするため、例えば質問と理想的な回答のセット(データセット)を複数用意し、それらについて「正答率○%以上」というような想定質問回答率を設定するという工程を設けているという。
データ参照に対するチューニングとして特に重要になるのが、「ナレッジの分割粒度を整える(chunking)」と「データに仮想回答の情報を加えて埋め込み(embedding)する」というアプローチだ。
特に前者は文章を参照したときの精度に差が出るという。例えば10万字のデータを4000文字でチャンクしても、後の方の4000文字のチャンクには概要の話は入らなくなる。そのような場合は、全チャンクの冒頭に100文字程度の要約文を付けるなどをすれば、「精度が上がりやすくなる」と渡辺氏は言う。
後者は、この情報ではどのような質問に回答できるかという仮想質問を生成させ、データに付与して埋め込みをすることで、検索の精度を上げるアプローチだ。「実際に実行するのは難しいかもしれないが、出てきてほしいデータが出てこない場合は、このアプローチが有効に使えると思います」(渡辺氏)
いずれにしても生成AI活用を推進するには、業務×データ×技術をバランス良く保ち続けることが大切になる。そのためにもまずは自社データをどのように生成AIに活用すべきかを定める。次に業務フローを正確に把握する。「生成AIという言葉に惑わされることなく、既存の業務をしっかり分析する泥臭い工程は不可欠です」(渡辺氏)
そして持続的に運用できる体制をもつことだ。「AIのライフサイクルは早いからこそ、都度体制を整えたり、承認を通していると最善なものがつくれないことがあるからです」(渡辺氏)
AI活用で業務効率化に結び付けた3つの事例
では具体的にNRIではどのように生成AIを活用しているのか。渡辺氏が紹介した第1の事例は、「工事査定での標準化を目指したAI見積もり活用による支援」である。
工事査定とは、施工会社が提出した見積もりが適正かどうかをチェックする業務を指す。ここでは、担当者が過去の査定内容をすべて覚えておくのが難しく、作業が個人に依存する属人化が進んでいた。このままでは技術や判断基準の継承が難しくなるため、その課題を解消する手段として AI の活用を決めた経緯がある。
工事査定では、AIに過去のドキュメント情報をインプットし、それを基に金額の妥当性を判断してもらっている。「このような仕組みであれば、生成AIを使わなくても機械学習でできるのでは」と思うかもしれない。
「業者によって、文言や言い回しが異なるため、それをすべて辞書に登録するには労力もかかり、漏れも出てくる。それを防ぐために生成AIを活用しています」(渡辺氏)
見積金額の予測値だけではなく、前回の工事と比較した値も出すようにしているという。
第2の事例は、「システム設計のレビューを実施する会議における、指摘内容を補足するAI機能の開発」だ。もちろん有識者に指摘してもらうことも大切だが、有識者もその人自身の知見をもとに回答している。そこで、全体を網羅した状態での妥当性を高めるため、過去の指摘事項をプロンプトに組み込み、新規資料に対して適した類似指摘を行える仕組みを作っているという。
「私たちAIソリューション推進部と各事業部とがタッグを組み、より精度の高い指摘ができるようプロンプトエンジニアリングを進めています」(渡辺氏)
この仕組みは、すでに稼働し始めており、結果も出ているそうだ。
第3の事例は「ヘルプデスク業務の半自動化施策によるシステム運用業務の簡素化」である。 従来は、担当メンバーの経験やスキルの差によって回答の品質にムラが出たり、やり取りが増えることで対応に時間がかかるといった課題があった。こうした非効率を解消するために、半自動化の施策が導入された。
半自動化するための施策としては、「テストケースの作成→入力データの準備→生成AIテストの実施→評価分析・改善」という4ステップからなるサイクルを1週間程度で実施。評価結果が良くない場合は、参照データや質問方法、プロンプトの見直しなどをして、再検証をして各プロセスを進めていったという。
検証プロセスは3回実施。それだけで「約7割のケースで、平均約5割程度の作業時間の削減が見込めた」と渡辺氏は言う。とはいえ、複雑な質問の場合、誤回答するケースもあった。「だからといって使えないと判断するのではなく、どの程度自信のある回答かをAI自身に判断させるようにしました。そこで出力された値が一定の値を下回ったらマネージャーに相談するなどのプロセスを踏むことで、生成AIの活用を進めています」(渡辺氏)
第4の事例は提案書生成への適用である。「3割以上の業務を支援することを目標に、業務を分析して体系化しています」(渡辺氏)
構造化のところでは、生成AIの活用はストーリー初案や資料割り初案の作成に留めているという。「1から10まで作らせようとすると、あらぬ方向に進んでしまうことがあるため」だと渡辺氏は述べる。
プロジェクト実績リストの作成にこの仕組みを適用したところ、これまで1時間の定型作業を10秒程度で完了できるようになったという。
工夫したポイントとしては、AIによる高度なマスキング処理、現場とともに育てるアジャイル開発、またプロジェクト実績リスト作成という汎用的な業務に着目し、横展開可能な「定型pptx(Microsoft PowerPointの標準ファイル形式)自動生成」をコンセプトにしたこと。今ではこのノウハウを用いて、他のpptx自動生成への横展開が可能となった。
他にも、自律性と安全性を両立させる、実用的なAIエージェント設計にも取り組んでいる。エージェントはLLMを軸に、計画、実行、検証、記憶という工程で構成される。「状況に応じて2つ以上の工程の選択、順序を変更する必要がある場合に採用している」と渡辺氏は話す。手順が固定ならAPIやワークフローで十分対応できるからだ。そのためまずAPIやワークフローが固定フローで十分かを判断したうえで、エージェントで何を自律化したいかを明確にするという。
全社に浸透させ、育てていく方法とは
NRIでは全社にAI活用を推進するため、縦串で組織的に活動することを重要視している。色々なチームと連携して活動を進めているが、なかでも意外と重要なのがガバナンス領域だと指摘する。
「リスクやコンプライアンス、情報セキュリティを管理している部署と連携しながら進めるのが良いと思います」(渡辺氏)
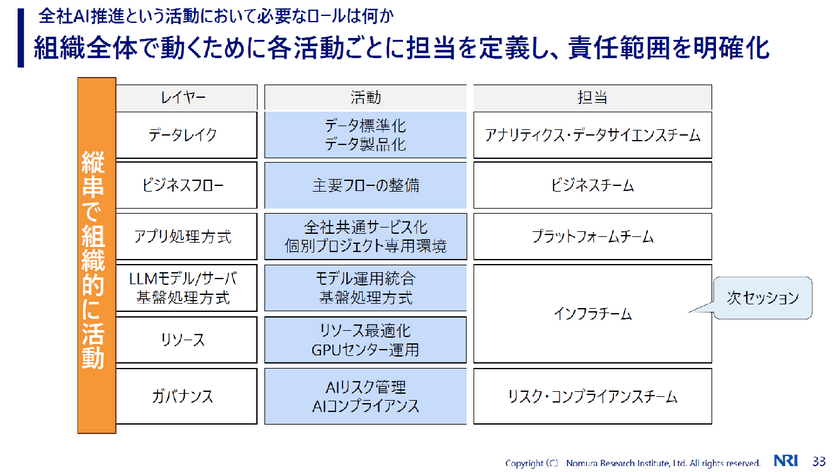
生成AIを利用する際の利用規約例の整備はその1つだ。利用者の責務やよりどころとなる規定、利用者ログの取得など、具体的に定めることが大切になるという。
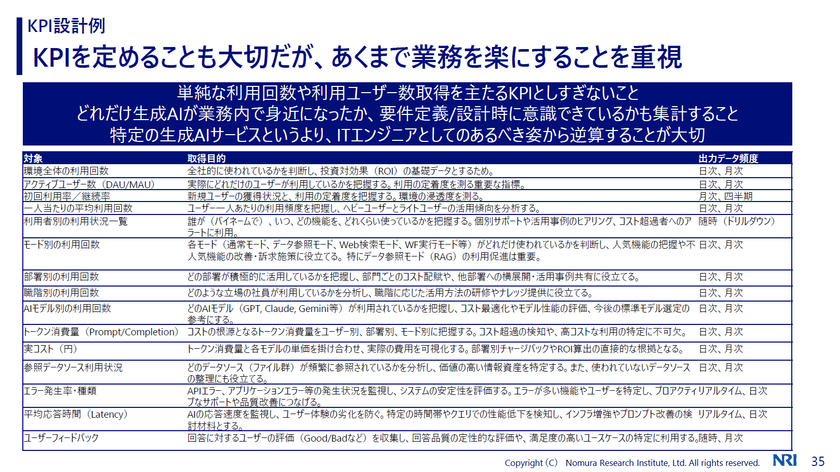
またもう1つ、推進するための留意事項として渡辺氏は、「KPIを定めることも大切だが、あくまで業務を楽にできるのが重要」と話す。どれだけ生成AIが業務内で役に立っているのかなど、ユーザーにアンケートを実施してユーザーの声を把握することも大事だと言う。ちなみにKPIとして集計する項目としては次のようなものが考えられるという。
AIを全社に推進していくためには、まず現状業務の可視化を行うこと。次にAIの適用領域と方式を特定する。さらに未来の業務フローを設計し、効果検証と継続的な改善を行っていく。このようにAIオーケストレーション設計を実施してロードマップをつくること。そこから全社AI推進は始まる。
自社DC内のGPU基盤の構築と実利用を想定したサービス設計
株式会社野村総合研究所
クラウドサービスマネジメント部
エキスパートテクニカルエンジニア
山田 時弥(やまだ・ときや)氏
NRIが自社データセンター内に構築したGPU基盤とは
山田氏は2010年にNRIに入社。ネットワーク系のインフラ、プライベートクラウドなどの担当を経て、2023年より生成AIを活用するためのインフラ担当となり、プライベートGPU事業の立ち上げに携わった。
渡辺氏の話にもあった通り、NRIでは3大クラウドのLLMと、自社で運用しているOSSのAIモデルを併用している。「このOSSのAIモデルは、自社データセンター内のGPU基盤で構築し運用しているため、OSSのAIモデルを利用する限り、外部サービスのような従量課金は発生しない」と山田氏は説明する。
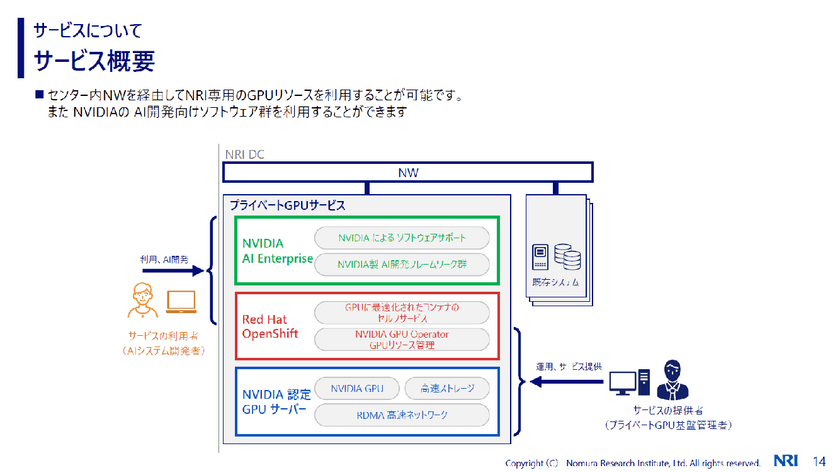
GPUサーバはNVIDIAの汎用性の高いPCIeタイプとSXMタイプを採用。「SXMタイプを採用するのは、GPUの性能を最大限に引き出すため」と山田氏。同社ではDGX(HGX)を導入しているという。
GPUのインフラが高額になる要因の一つが、「ネットワーク部分」と山田氏は指摘する。GPUの処理は推論・学習ともに並列分散処理を行う。GPU間の処理をいかに高速に行うかが重要なポイントになるというわけだ。SXMタイプに搭載されるGPUでは、NVLinkと呼ばれる専用の高速内部バスでGPU間のデータが処理される。例えばNVIDIA H100 GPUに搭載されているNVLinkは、世代にもよるが、900GB/秒という速度を実現している。
一方、PCIeタイプは5.0世代が128GB/secとなっており、「この時点でかなり速度に差があることがわかる」と山田氏は言う。
DGXシステムなどでは、複数の筐体(サーバー)間をネットワークスイッチに接続して並列処理を行うケースもある。その場合、ネットワークスイッチに対しても、「100Gbps〜400Gbps(ギガビット/秒)のインターフェースが必要になるなど、それなりの高性能が求められる」と山田氏は説明する。
さらにネットワークに関して「重要な技術要素がある」と前置きし、山田氏が紹介したのがGPUDirect RDMA/Storage。前者はCPUを介さずにネットワークデバイスとGPUメモリ間のデータ転送を可能とする技術。後者はストレージとGPUメモリ間の直接データパスを可能とする技術だ。
筐体間のGPUや外部ストレージとの通信を高速にするには、GPUDirect RDMA/Storageが必要になる。「こういった技術に対応しているネットワーク機器を用意することも重要なポイントになります」(山田氏)
続いて山田氏は自社GPU基盤のGPUチップについて紹介した。最新のGPUとしてはBlackwellが流通しており、ハイパースケーラーなどでは採用しているが、同社では2023年に最新だったH100 SXMを導入しているという。
NVIDIA GPUのCUDAのライブラリをベースにAIワークロードを立ち上げて実際の処理が行われる。その際、演算ユニットとメモリの間で頻繁にデータの読み書きが発生する。「メモリ容量とメモリバンド帯域幅が非常に重要な処理性能の指標になります」(山田氏)
GPUのリソース管理に必要なコンテナオーケストレーションとジョブスケジューラーの選択については、「それぞれ異なる特性を持つため、システムの運用要件、既存インフラストラクチャなどを考慮したうえで適切に選択することが重要です」と山田氏は言う。
一般的にHPC系のシステムであればジョブスケジューラー、マルチテナントや複数の利用者にGPUリソースを分けて利用してもらうケースは、コンテナオーケストレーションを採用する。NRIでもコンテナオーケストレーションを採用している。
コンテナを導入してもGPUが使えるようになるわけではない。扱えるようにするにはいくつかのドライバーが必要になる。NRIではエンタープライズ対応のKubernetesコンテナプラットフォームであるOpenShiftを採用しており、OpenShift環境を運用・管理するためのOperatorを導入することでサーバの管理を行っている。
導入しているOperatorは次の3つ。
- NFD(Node Feature Discovery)Operator:OpenShiftクラスタ内のハードウェア情報の管理を行うOperator
- NVIDIA GPU Operator:GPUのプロビジョニングに必要なNVIDIA DriverやDevice Pluginなどのソフトウェアコンポーネントの管理を行うOperator
- NVIDIA Network Operator:RDMAおよびGPUDirect RDMAのワークロードを有効化し、ネットワーク関連のNVIDIAコンポーネントの管理を行う
NRIでは、このような技術で構築されたGPU基盤を、サービス提供形態の一つとして『GPU as a Service』を展開しており、社内利用者向けに必要な分だけのGPU環境を提供している。
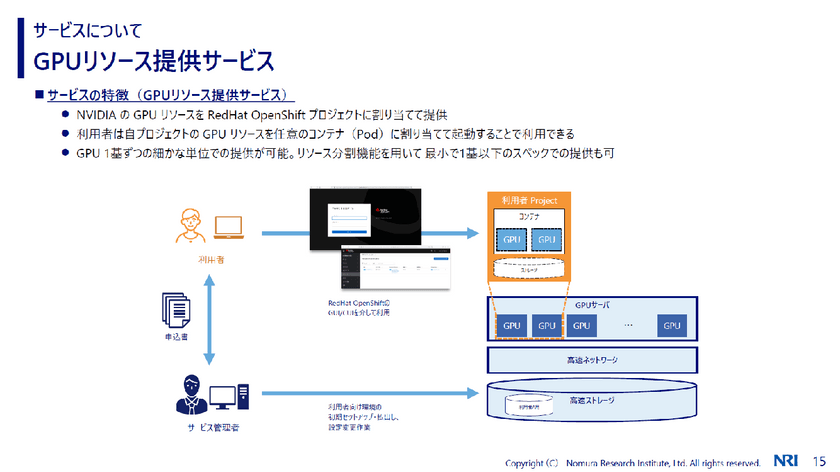
GPUリソース効率活用のためのパフォーマンス検証
山田氏はGPUリソース効率活用のためのパフォーマンス検証の方法についても紹介。GPUリソースはかなり高額になるため、適切にサイジングして提供する必要がある。「処理量に耐えられるかという検証を行っている」と山田氏は話す。推論処理のリクエスト数を増やしていき、計算リソース(GPU)のボトルネックを確認するという方法だ。
また山田氏はvLLMにおけるメモリの使われ方の検証方法についても説明した。

vLLMは推論エンジンに使うが、その約1割が管理用の領域として割り当てられるため、vLLMとしては9割をメモリとして使う。山田氏の検証に使ったvLLMはELYZA-Shortcut-1.0-Qwenなので、パラメータ数が32B、精度をFP16で扱った場合、デプロイに約64GBのモデルが必要になる。
これを4つのGPUに分散して重みをロードするため、1GPUあたり16GBの重みが乗ってくる。残りの部分をKV Cacheでトークンを生成するなどの処理に使われるのだが、並列度を上げて大量のプロンプトを発生させたうえで、KV Cacheを埋めるとどうなるのか。e2eレイテンシ(推論リクエスト投入後、LLMからすべての出力トークンが返るまでの時間)とTPS(1秒当たりの出力トークン数)という指標を設定して計測した。
「TPSは並列度を上げていくと実行数は伸びていくが、150を超えると頭打ちになりました」(山田氏)
またe2eレイテンシについては、並列実行数が100未満の場合は、全リクエストが均等かつ安定した時間で処理されるという結果になった。だが並列実行数が150を超えると差分が拡大し、並列リクエスト間で応答時間に差が生じたという。
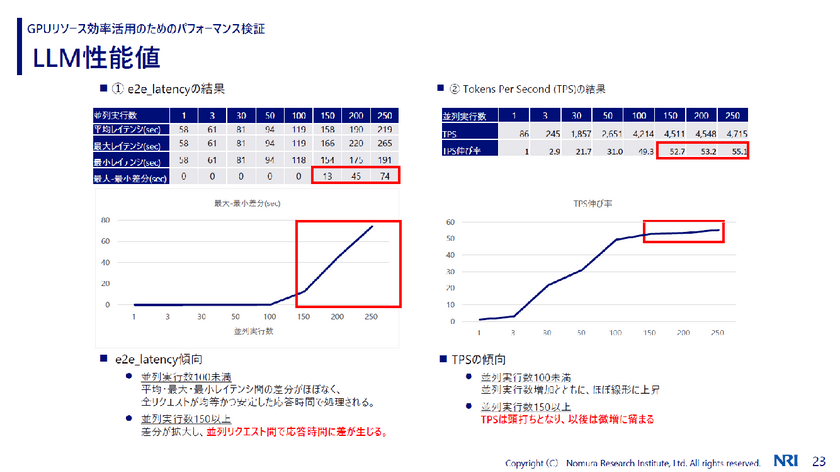
これらの検証結果からわかったことの1点目は、GPU計算リソース利用率よりもGPUメモリ(特にKV Cache)が先にボトルネックになる傾向があること。2点目は物理的にGPUリソースを保有する場合は、適切なサイジングが重要になるため、GPUメモリの制約がボトルネックにならないよう、推論以外のワークロードやGPUの特性に合わせた運用方法を検討すること。第3は推論以外のワークロードを実行する際には、タスクの優先順位付けやスケジューリングを工夫すること。
「例えば学習ジョブは空き時間に実行するなど、空き時間を有効に使うようにすることも運用上、不可欠な考慮事項です」(山田氏)
パネルディスカッション「運用中に起きた失敗事例と学び」
ここからは株式会社野村総合研究所の近藤健氏が参加。渡辺氏、山田氏、近藤氏によるパネルディスカッションが行われた。近藤氏は2006年にNRIに入社。研究開発やサービスの企画・設計・開発、新技術のプロジェクトへの導入支援などを経験。現在はaslead事業部にて、社内外向けの生産性向上ソリューションの企画・マーケティング・営業・技術支援を行うグループのマネジメントを担当している。司会進行はTECH PLAY事務局が務めた。
株式会社野村総合研究所
aslead事業部 事業企画グループ
グループマネージャー
近藤 健(こんどう・たけし)氏
運用中に起きた失敗事例と学び
──山田さん、お願いします。
山田氏:当時、AIモデルとして最初に検討したのが、評判がよかった「Swallow 70B」。これを全社に展開すべく、2つのGPUで動かそうとしたのですが、先ほど説明したKV Cacheに気づいていなかったため性能が出ず、不安もありましたが、チューニングするなどして、だんだん使えるようになりました。最初は手探りで進めた部分もかなりありましたが、検証を繰り返すことで今のような仕組みが作れました。
渡辺氏:途中でOSS自体も2回切り替えるなど、大変だった記憶があります。
山田氏:vLLM自体も切り替えたタイミングでした。AIの移り変わりが激しいので、性能も変わります。全社で利用してもらうインフラなので、メンテナンスには結構、気を遣っています。
近藤氏:GPUはCPUと比べて性能指標が違うので、測定が難しかったのではないでしょうか。
山田氏:その部分のナレッジがなかったので、苦労しました。今はPrometheusとGrafanaを導入して、GPUのリソースを一元的に見える形にするなど、工夫しています。
Agentをどの範囲で自律化すべきか
──エージェントの自律化について、渡辺さんの考えを教えてください。
渡辺氏:これについては悩まれている方も多いと思います。私たちも試行錯誤中ですが、自律化すべきかどうかは、どんな対象システムをつなぐかがポイントになると思います。どんなAPIが提供されているかはもちろんですが、まずは実現したい業務から逆算して、自律化を考えるようにしています
近藤氏:AI エージェントでデータの参照範囲をコントロールするは結構難しいと思うんです。そこで渡辺さんに質問です。個人の権限で見られる情報を全部参照できるようにするのか、それともプロジェクトや組織単位で情報を限定したうえで、権限を設定していくべきなのか。どんな基準で整理していくのが良いのでしょうか?
渡辺氏:権限設計を考えるときは、人がどれだけ理解しやすいかを基準に整理しています。自分が普段見えている範囲と同じように参照範囲を設定すれば、個人として迷わず認識できますよね。ですが、プロジェクト単位のように複雑な権限にすると、1個人からは分かりづらくなる。だからこそ、個人で扱える範囲と、組織として管理すべき範囲の「2軸」で認証・認可を整理することが大事だと思います。
──その件で、実際にトラブルになったことがありますか。
渡辺氏:プロジェクト内でナレッジを共有したいという要望は多いのですが、「やりたいこと」と「できること」のギャップ、いわゆる期待値コントロールに悩まされることが多いですね。まずは、そのギャップを認識してもらうところが出発点になります。というのも、個人レベルでも自分がどこまでアクセスできるのかを把握しきれていないケースがあるからです。
今のエージェントだと、『この人はこのプロジェクトでこの権限だから、この範囲まで見せる』という設計はなかなか難しい。質問の仕方ひとつで、意図せず権限の範囲が変わってしまうこともありますから。そうしたリスクのある業務は対象外にして、エージェントが価値を発揮しやすい領域に集中しています。
使うAIから育てるAIへ。社員全員がビジネスアナリストになる未来
──社員全員がビジネスアナリストになる未来に向けて、どんな取り組みをしているのでしょう。
近藤氏:「使うAI」から「育てるAI」になるには、3つのステップがあると思います。まずはセキュアな基盤をしっかり作っていくこと。これができれば、感度の高い人たちは使ってくれるようになり、そういう人を中心に社内に広まっていくと思います。
次は忙しい人に使ってもらえるようにすること。忙しい人ほど勉強する時間はありません。そこで今、私たちが進めているのは、AI導入の専門チームを作り、忙しい人をサポートしていく取り組みです。ここまでくると、自分たちでAIを改善して業務を効率化することができるようになるのではないでしょうか。
3つ目のステップが、生産性の高いものを組織として横展開していくこと。そうすることで組織としてAIを育てるフェーズに入っていけると考えています。当社も2026年度以降、このような取り組みをしていく予定です。
渡辺氏:忙しい人がAIを活用するための具体的な仕組みを教えてください。
近藤氏:今進めているのは組織としての取り組みです。1つは役員を通して本部全体に活用を促す方法と、もう1つはハッカソンに参加してもらうことです。忙しい人でも半日ぐらいは時間を作れると思うので、ハッカソンに参加して、AI活用を自分事化してもらう。そういう2軸でAI活用を推進しています。
山田氏:私たちの部署でも取り組まなければと思うものの、現業が忙しくてなかなかAI活用に時間が割けません。だからこそ、伴走して支援する仕組みや、業務効率化につながるモデルがあれば、もっとスムーズに進むのではないかと思っています。
近藤氏:まさに今、そうした伴走支援の仕掛けを立ち上げようとしているところです。まずは特定の個人に密着して、伴奏型で生産性向上を支援する。それをユースケースとして他の人にも横展開する。規模は小さいですが、そのための専任チームもつくりました。
Q&Aセッション
Q. 提案書や見積もりは機密情報を含むと思いますが、データマスキングの考慮はありますか。また、LLMベンダー側のデータ保持を防いだり、情報が学習に使われないようにする規約があるのでしょうか。
渡辺氏:後者から先に回答します。LLMベンダーの利用規約には、学習に使われないと明記されていることが多いです。利用規約には、データの分析への使用の有無、チャットの保持期間などが記載されています。利用規約を読んでもよくわからない場合は、各LLMベンダーに問い合わせて確認することが大切です。例えば当社のように自社のAzure基盤を使うのであれば、マイクロソフトの規約を見る必要があります。その中でも気をつけたいのが、Microsoft 365のプラン。エンタープライズ向けのプランを契約することは、最低限、必要になると思います。
その上で、データマスキングの考慮については、本当に機微なものに関してはプライベートLLMを使うか、人手である程度マスキングをすることです。我々はお客様名が直接出ないようにプライベートLLMでマスキングし、その業務を担当する部署の人に、チェックしてもらっています。
Q. 多くの方にAIを有効的に使っていただき生産性を高めるためには、精度だけではなくTTFT(Time to First Token)をうまく調整することが不可欠のように感じます。応答速度はどのくらいの時間を基準にするのが良いのでしょうか。
渡辺氏:ユーザーへの応答時間は、0.5秒から長くても2秒くらいが良いと言われています。ですが、実際に多段でエージェント処理したり、RAGを使ったりすると、その速度で応答するのはほぼ不可能です。我々はそのための工夫として、画面上に返答までの目安時間を最初に出すようにしています。ユーザーの期待値を下回らないよう、UI/UXでカバーすることも1つの手です。
Q. モデル運用のミドルウェアとしてはvLLM以外にNVIDIA NIMのGPU最適化されたコンテナなども選択肢としてありそうですが、他のミドルウェアとのメリット・デメリットの比較検討などありましたでしょうか。
山田氏:推論エンジンに関しては、他のミドルウェアの選択肢がありました。ですがNRIの中に推論エンジンに関する評価をしていたチームがあり、その情報を参考にして、今回はvLLMが最適だと判断し採用しました。NVIDIA NIMについては、今内部で検証しています。 推論エンジンとしてvLLMが稼働しているようなところがある、TensorRTを動かせるモデルが限られるなど、NIMを扱うにはモデルを考慮する必要性があるということが分かってきました。
Q. 社内業務の場合ナレッジを溜める文化がないケースがあるのですが、どうやってナレッジをデータ化していったのでしょうか。
近藤氏:NRIでもコアな業務ほど、ナレッジが溜まっていないところがあります。それをどうしていくか、私たちも今、議論しているところです。実際にその環境に入り、AIを使ってナレッジを抽出し形式知化できないか、試しています。
文=中村 仁美
※所属組織および取材内容は2025年10月時点の情報です
株式会社野村総合研究所
https://www.nri.com/jp/
株式会社野村総合研究所の採用情報
https://career.nri.co.jp/
おすすめイベント


関連するイベント










