
AIエージェントの本番運用を成功に導くアーキテクチャ設計とデータ前処理の実践
企業におけるAIエージェントの構築・導入は、セキュリティとガバナンスの設計や、AIが状況を正しく認識し自律的に計画・実行するためのデータ前処理が重要となる。 本イベントでは、AIエージェント実装を「本番で動く形」に落とし込むためのアーキテクチャ設計や抑えるべき勘所について、NTTデータ先端技術社員が詳しく解説を行った。企業におけるAIエージェントの構築・導入は、セキュリティとガバナンスの設計や、AIが状況を正しく認識し自律的に計画・実行するためのデータ前処理が重要となる。
本イベントでは、AIエージェント実装を「本番で動く形」に落とし込むためのアーキテクチャ設計や抑えるべき勘所について、NTTデータ先端技術社員が詳しく解説を行った。
アーカイブ動画
AIエージェントを“動かし続ける”基盤とは?― NTTデータ先端技術流の設計と実践 ―
小山 哲平(こやま・てっぺい)氏
株式会社NTTデータ先端技術
デジタルビジネス事業本部
テクノロジー&ソリューション事業部
データインテリジェンス担当 担当部長
最初に登壇した小山 哲平氏は、NTTデータ先端技術のデータインテリジェンス担当部長として、ITインフラとデータ活用の両面からAIエージェントの本番運用に向けたアーキテクチャ設計に取り組んでいる。
2025年は「AIエージェント元年」になると言われたなか、システムの精度や機能面に加え、エンタープライズ利用に欠かせない「認証・認可」の重要性が強調された。
まず、AIエージェントの定義とその特徴について語られた。
従来の生成AIは、ユーザーがプロンプトを入力し、AIが要約や翻訳などを出力する「成果物」が中心だったのに対して、「AIエージェントは与えられた目標(ゴール)に対して状況を理解し、自律的に推論、計画、実行までを担うシステム」だと小山氏は説明した。
AIエージェントの代表的な特徴として、以下の4点が挙げられる。
第一に、単発の質問ではなく目標やタスクといった大きな枠組みを最初に考える「目的志向」であること。さらに、その目的に対して「自律的・半自律的」に動作し、状況を正確に認識しながら適応できるほか、実際の動作ではLLMだけで完結せず、外部のツールを適切に活用して実行する点も大きな特徴だ。

当初の生成AIの活用は、ユーザーから質問や依頼内容がプロンプトとして与えられ、それに対してLLMが応答し、文章生成や要約、翻訳といった成果物を出力する「プロンプトドリブン」の形が中心だった。
それに対して、AIエージェントの世界ではこの構造が変化している。ユーザーから与えられるのは個別の質問ではなく、「目標」や「タスク」といった形の依頼になる。これに対して、計画立案から実行までのプロセスをAIが担い、段取りも含めて自律的に進めていく。
判断についても基本的にはAIが行うが、必要に応じて人が介在するヒューマン・イン・ザ・ループの仕組みを取り入れ、精度や安全性を担保する。
このように、単発のアウトプット生成から、目的達成型のプロセス実行へと進化してきていると言えるわけだ。
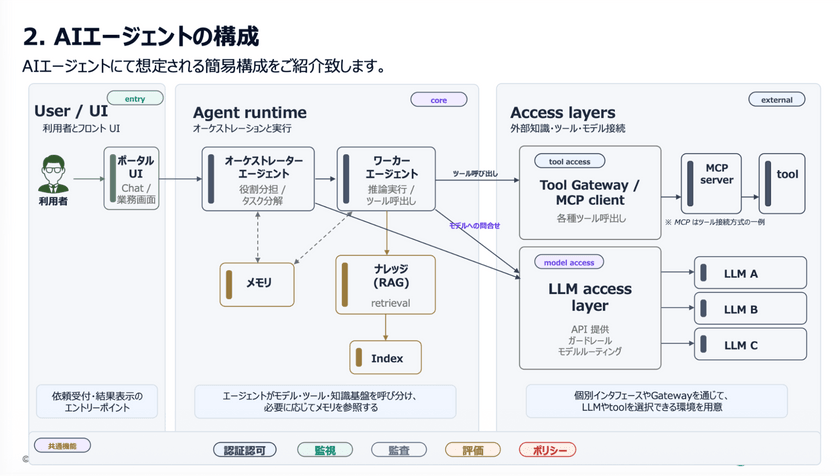
次にAIエージェントで想定される構成だが、ユーザーの依頼をタスク分解する「オーケストレーター」と、具体的な作業を担う複数の「ワーカー」の多層構造となる。
ユーザーからの依頼は、チャットや業務画面などのUIを通じて行われ、その処理はエージェントレイヤーが担う。具体的には、最初にオーケストレーターエージェントがタスクの分解や役割分担を実施。
分解されたタスクは個別のワーカーエージェントが実行し、必要に応じて手順書や社内コードなどのナレッジを参照しながら処理を進める。
加えて、LLMや外部ツールの連携も重要な要素である。
近年はMCP(Model Context Protocol)の活用が進んでおり、これを通じて外部ツールにアクセスする構成が一般的になりつつある。これらのツールは、ゲートウェイやレジストリのレイヤーで一元管理することが求められる。
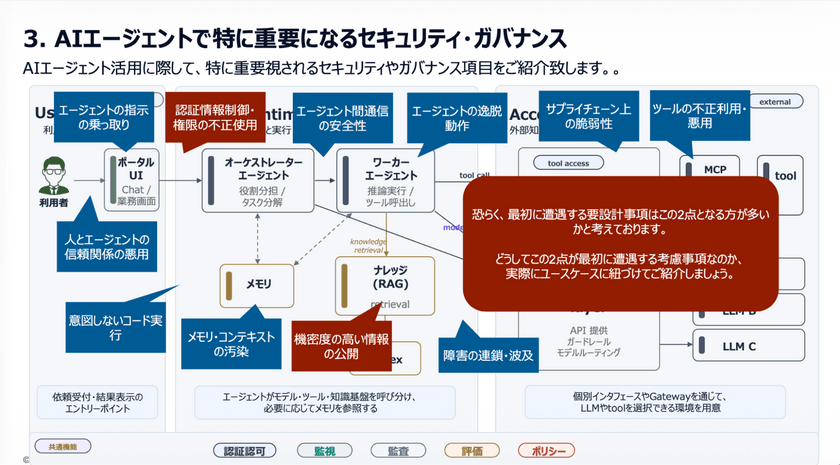
セキュリティガバナンスの観点で、どのような点に注意を払うべきかを整理したのがこちらの図となっている。
まず、利用者がAIエージェントに依頼を行う入口部分では、エージェントの指示の乗っ取りや不正操作が最も大きなリスクとなるため、厳格なセキュリティ対策が求められる。
また、UIからエージェント、さらにその先のシステムへと処理が連携する過程では、適切な認証・認可の仕組みが不可欠だ。
さらにエージェント間通信においても、改ざんや盗聴を防ぐための安全性の担保が求められるほか、エージェントの実行環境では想定外の挙動や逸脱した動作を防ぐための制御も重要となる。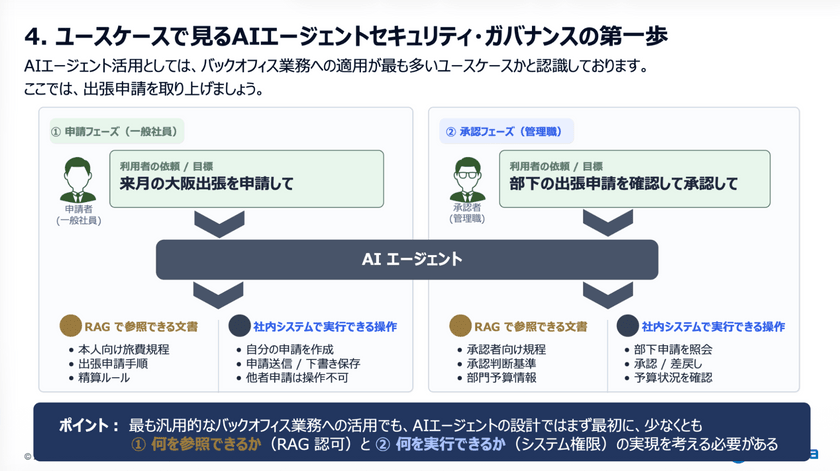
最も汎用的なバックオフィス業務への活用においても、AIエージェントの設計では最初に「何を参照できるか(RAG認可)」と「何を実行できるか(システム権限)」の実現を考える必要があると小山氏は述べた。
RAGによる認可を実装する際には2つの手法があるという。
まずは、一般社員や管理職といったユーザーの属性によって、検索結果にフィルタリングをかける方法だ。もうひとつのやり方は、「インデックスに権限情報を持たせ、検索時にフィルタリングする」というもの。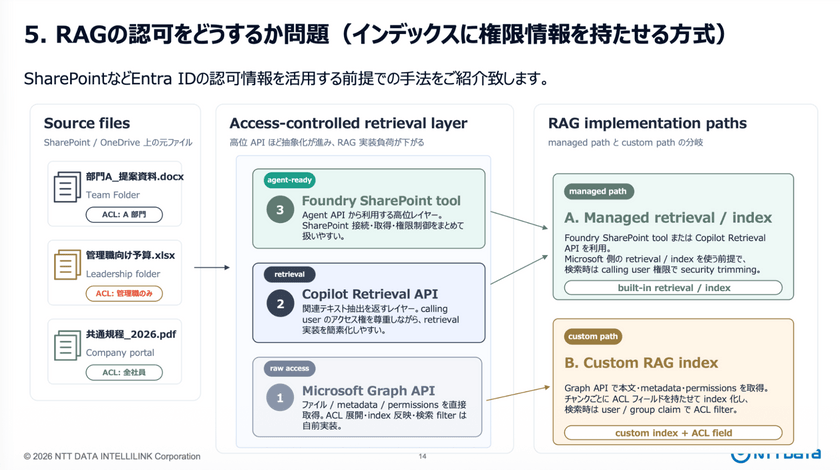
具体的には、Microsoft Entra ID上のパーミッション情報をRAGに反映させる仕組みや、Microsoft 365 Copilot Retrieval APIを活用することで、元のファイルの権限を踏襲した安全な検索が可能となるという。
小山氏は、社内システムへのAIエージェントのアクセス権限には、「ユーザーを代理して使う」方式と「エージェント自身に持たせる」方式の2つがあり、状況に応じて使い分ける必要があると述べた。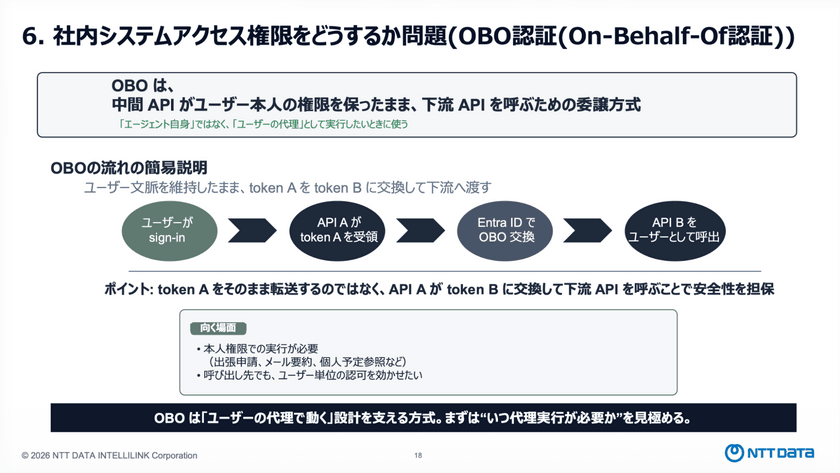
「ユーザーを代理して使う」方式ではOBO認証(On-Behalf-Of認証)を用いて、認証・認可を実現しているという。OBO認証とは、中間APIがユーザー本人の権限を保持したまま、下流のAPIに対してその権限を委譲できる仕組み。
ユーザーの認証トークンをそのまま後続に渡すと漏えいリスクが生じるため、OBOではトークンを安全に交換し、新たな認証情報として後続のAPIに引き渡す。この認証方式により、セキュアに権限移譲を行うことができる点が特徴となっている。
AIエージェントの導入にあたっては、どうしても精度や機能面を重視しがちだが、業務への適用を考えるフェーズにおいては「精度や機能に加えて、認証・認可についても十分に向き合っていただきたい」と小山氏は強調した。
生成AI時代のデータマネジメントと前処理
鈴木 旭(すずき・あきら)氏
株式会社NTTデータ先端技術
デジタルビジネス事業本部
テクノロジー&ソリューション事業部
データインテリジェンス担当
次いで登壇したのは、データ分析基盤エンジニアの鈴木 旭氏。2018年にNTTデータ先端技術へ入社し、生成AI向けの基盤構築・保守の案件に携わっている。
冒頭では、生成AI時代のデータマネジメントについて説明を行った。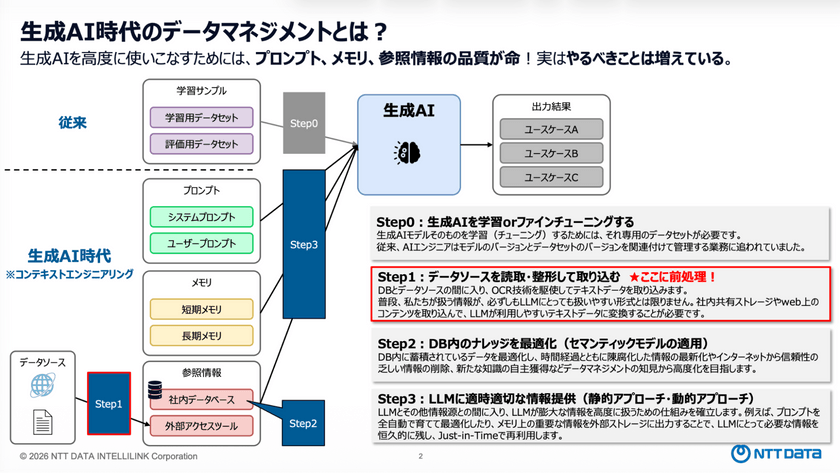
従来の生成AI開発は学習サンプルを用意し、モデルを構築・ファインチューニングするという「どう作るか」が中心だった。しかし、生成AI時代に入ると、この構造は劇的に変化した。プロンプト、メモリ、参照情報、データソースなど扱う領域が大きく広がっており、「どう作るか」から「どう使うか」へと移行している。
こうした状況のなか、生成AIを高度に使いこなすためには「前処理」が不可欠だと鈴木氏は話した。必要な情報が「漏れなく」「無駄なく」「矛盾なく」取り込まれないと、生成AIがうまく活用できずに失敗につながりやすくなる。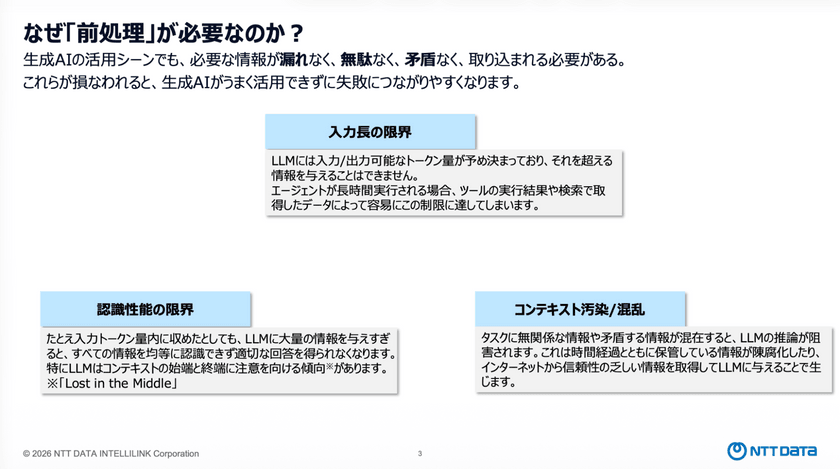
生成AIの利用には「入力長の限界」「認識性能の限界」「コンテキスト汚染・混乱」の3つの制約が存在する。
生成AIには入力できるトークン量が事前に決まっており、上限を超える入力はできないため、トークン量を適切に制限する必要がある。
また、トークン上限まで情報を詰め込んでも、LLMは情報過多によって適切に認識できなくなる。特に入力の始めと終わりに注目し、中間部分の情報が認識されにくくなる「ロスト・イン・ザ・ミドル(Lost in the Middle)」が生じるため、その点に意識を向けることが肝になる。
加えて、トークン内に無関係な情報や矛盾するデータが混在すると、LLMが正しく推論できなくなるため、正確で一貫した情報を入力することが重要になるのだ。
これらの課題を解決するため、前処理の工程で情報の選別・整理・構造化を実施し、LLMが適切に処理できる状態に整えることが求められるわけである。
前処理の流れは、以下の4段階で構成される。
まず最初のステップとして、AzureのOCRツールなどを活用し、ドキュメントからテキストを抽出。
OCRによって認識された箇所は黄色で表示され、テキスト化された情報はJSON形式で出力される。
表データについては、基本的にマークダウン形式やHTML形式に変換するが、特に「ページをまたぐ大きな表」はOCRだけでは正しく認識できないため、前処理において「同じ表である」と判定し、結合する必要がある。
そのため、「表のタイトル」「キャプション」「ページ番号(フッター)」などを論理的に判断し、分割された表を一つのまとまりとして結合するロジックを構築することが求められるという。
図の場合は、必ずしもテキスト変換する必要はなく、重要な情報が抜け落ちないように、要約やキャプションのみに留めることや、URLで元の図を参照できるようにしておく。フローチャートなどの形式は、日本語テキストよりもMermaid記法のようなドメイン固有言語(DSL)で表現する方が適している。
ノイズ除去は、ドキュメントの不整合を取り除くために実施する。例えば行政文書では、見出しが慣習的な書き方で括弧に囲まれているケースがある。この場合は正規表現などを用いて括弧で括られた部分を「見出し」として変換する処理が必要となる。
本文中の番号付きの記述についても、箇条書きであるにもかかわらず、通常の文章と混同される場合があるため、「これは箇条書きである」と判別できるように変換しておくことが大事だと鈴木氏は説明した。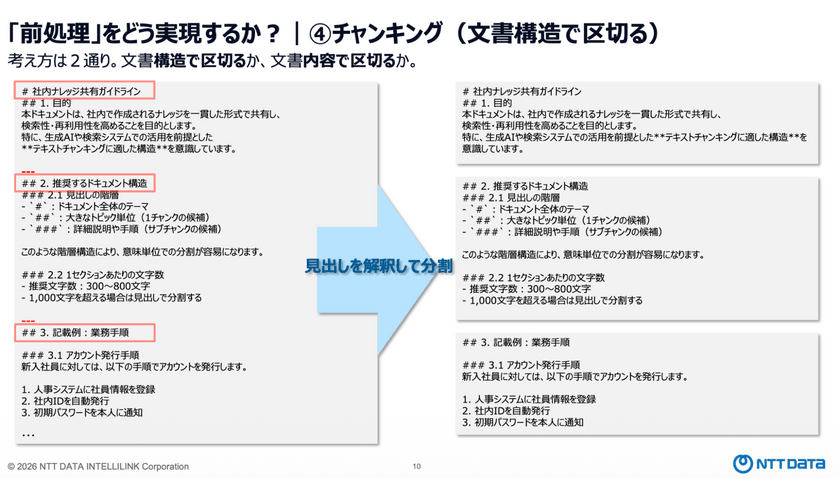
LLMが理解しやすい形にテキストを分割する「チャンキング」には、「文章構造で区切る」か「内容で区切る」かの2つの方法がある。
テキスト化の段階で見出し情報が正しく取得できていれば、その見出し単位でチャンクを分割することができる。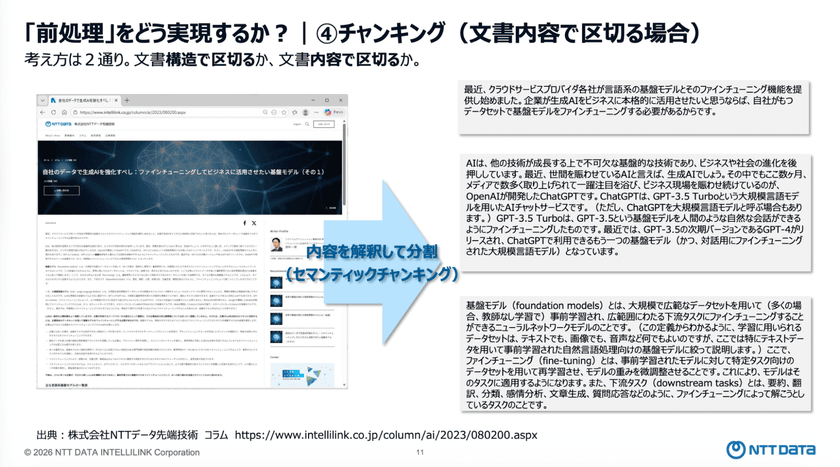
一方で、HTML構造が整理されていないWebページのように、文書全体が一つの塊として扱われてしまう場合、どこが見出しか判別できず、そのままでは適切にチャンキングできない。
その際は、文章の意味や内容をまとまりごとに分析してチャンク化する「セマンティック・チャンキング」と呼ばれる手法を適用することが有効だという。
AIエージェントで自分専用のラジオ番組制作にトライする!
西山 大樹(にしやま・ひろき)氏
株式会社NTTデータ先端技術
デジタルビジネス事業本部
テクノロジー&ソリューション事業部
データインテリジェンス担当
続いて登壇したのは、西山 大樹氏。普段はシステムの基盤領域の開発に従事していることもあり、エンドユーザーが直接利用するアプリケーションに触れる機会はこれまで多くなかったそうだ。
そこで、一人のユーザーであり開発者でもある立場から、LLMを使って自作のラジオ番組制作に挑戦。
その過程で得た「気づき」や「発見」をセッションで共有した。
今回作成したアプリケーションの構成要素は、Dify、SaaS版のChatGPT、Dockerコンテナをベースとしている。また、一部はスクラッチで実装しており、PythonやBashによる簡単なプログラミングも行っている。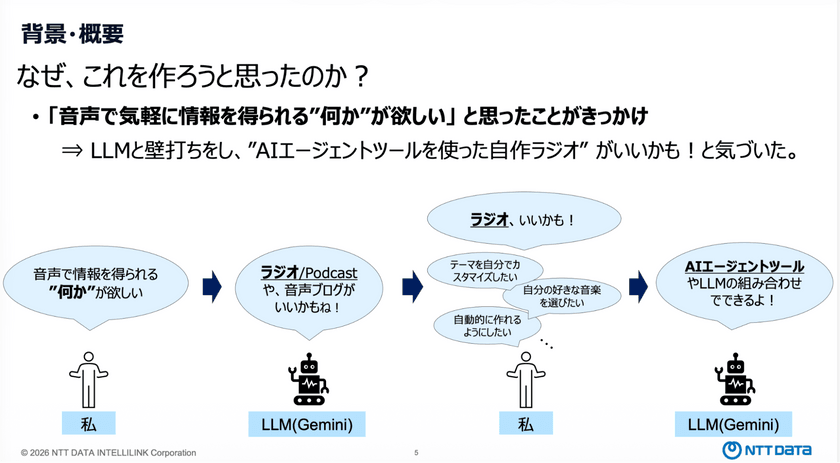
開発のきっかけは、「音声で気軽に情報を取得できるツールが欲しかったから」だという。西山氏自身、普段は文書で情報を得ることが多く、文字を読む作業に疲れを感じていた。そこで、耳から情報を得ながら理解できる手段があれば便利だと考えたことが、今回の取り組みの動機だと話した。
まずはアイデアを具体化するために、LLMを使って壁打ちを行い、アイデアの候補出しを行った。
「音声で情報を得る手段としてどのような形があり得るか」を問いかけたところ、「ラジオ形式がよいのではないか」という提案が得られた。これを受けて、自分自身がラジオを好んでいることもあり、方向性として適していると判断した。
さらに検討を進めるなかで、「テーマを自分でカスタマイズしたい」「好きな音楽を選びたい」「テーマや音楽の選定を自動化したい」といった要件が出てきた。こうした要望を踏まえて検討を重ねた結果、AIエージェントと複数のLLMを組み合わせれば実現可能ではないかという結論に至ったという。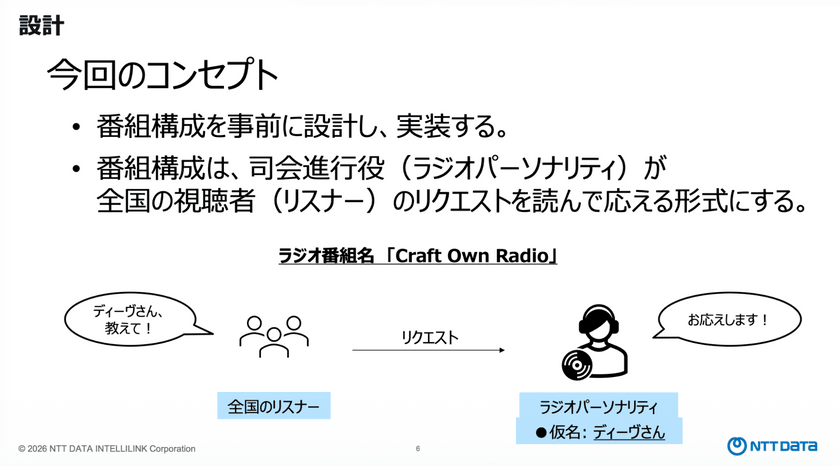
設計にあたっては、まずコンセプトを定義した。
今回は、「番組構成を事前に設計し、それに基づいて生成する」というアプローチを採用。具体的には、パーソナリティがリスナーからのリクエストを紹介し、それに応えていく王道のラジオ形式を選択した。
仮想のパーソナリティとして「ディーヴ」というキャラクターを設定し、この人物がリスナーからの投稿に応える形で番組を進行する構成としている。
その他の要件については、以下のように自身のこだわりや実現したいポイントを整理した。
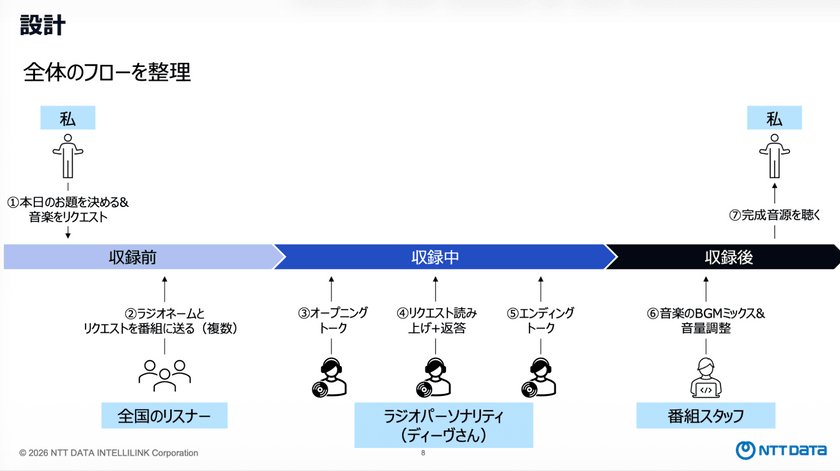
ここからは、実際にどのように開発・実装していくかのプロセスを紹介した。今回のケースでは、「収録前」「収録中」「収録後」の3つのフェーズに分け、それぞれで必要な処理を定義した。
自分の役割は、「本日のお題」と「再生したい音楽」を指定すること。それを起点に処理が始まり、テーマに基づいて全国のリスナーがリクエストを投稿する仕組みになっている。
リクエスト数も事前に指定できるようになっており、一定数に達した時点で番組の収録フェーズへと進む。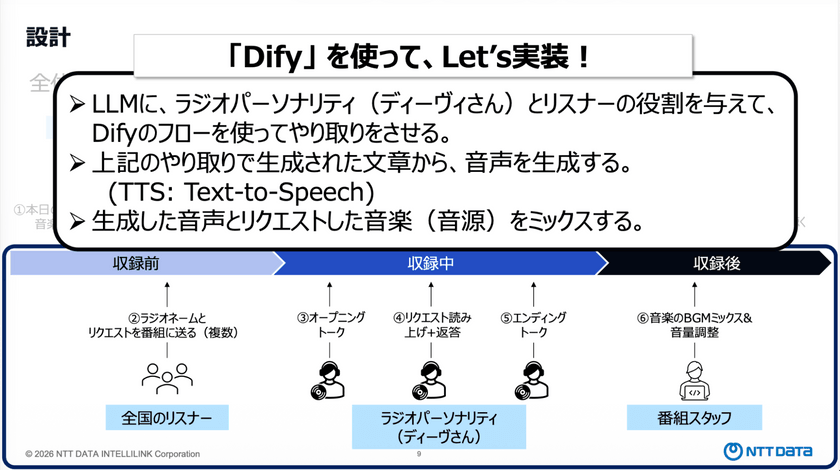
収録では、最初にオープニングトークを行い、その後にリクエストを順に読み上げ、ラジオパーソナリティの「ディーヴ」が応答する。最後に締めのトークを入れることで、番組らしい構成となるように工夫した。
収録後は、音声コンテンツとしての仕上げを行う。
生成されたトーク音声に対して、事前に指定した音楽をBGMとして後付けでミックスし、最終的な音源として出力。この音源をユーザーが受け取る形で処理は完了する。
以上の一連の処理はすべて自動化を前提とし、Difyを用いて実装した。具体的には、LLMに対して「ラジオパーソナリティ」と「リスナー」の役割をプロンプトで定義し、それぞれの発話を生成させることで番組のやり取りを構築。生成されたテキストが揃った段階でTTS(Text-to-Speech)により音声化し、最後に音声とリクエストされた音楽を合成して完成とする。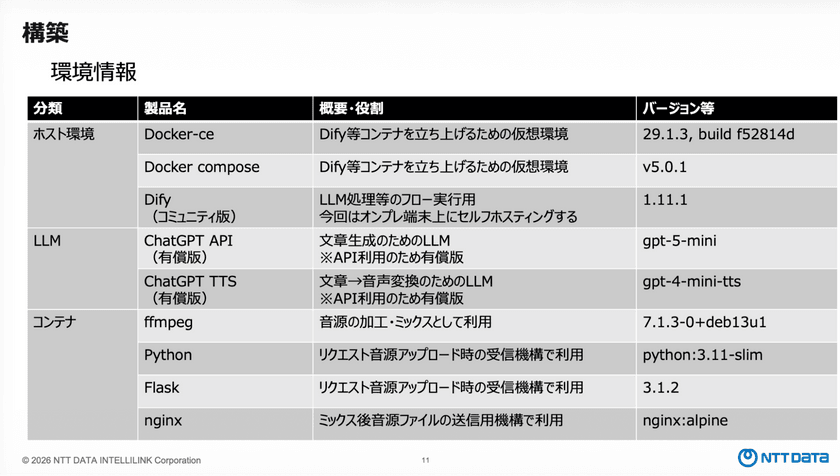
ホスト環境はDockerを中心に構築し、Difyをコンテナとして起動している。LLMにはChatGPTの有償APIを利用し、音声生成にはGPT-4o miniのTTSを採用。音声の加工やミックス処理にはOSSであるffmpegを使用し、Web APIとしての受付部分はPython、FlaskおよびNginxで構成している。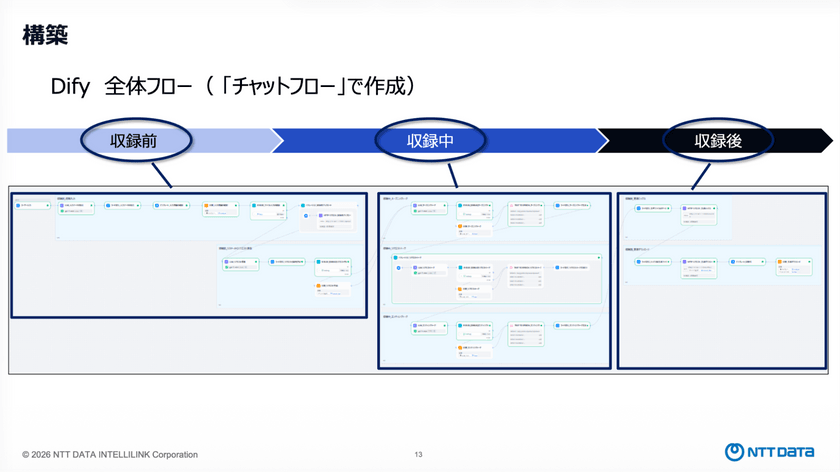
実装フローは全体として複雑な構成になっているが、業務フローと同様に「収録前」「収録中」「収録後」の単位に分割して設計している。
特徴的なのは、チャット形式のフローとして実装している点だ。これは、ユーザーが「本日のお題」や「生成するリクエスト数」を柔軟に指定できるようにするためだと西山氏は説明した。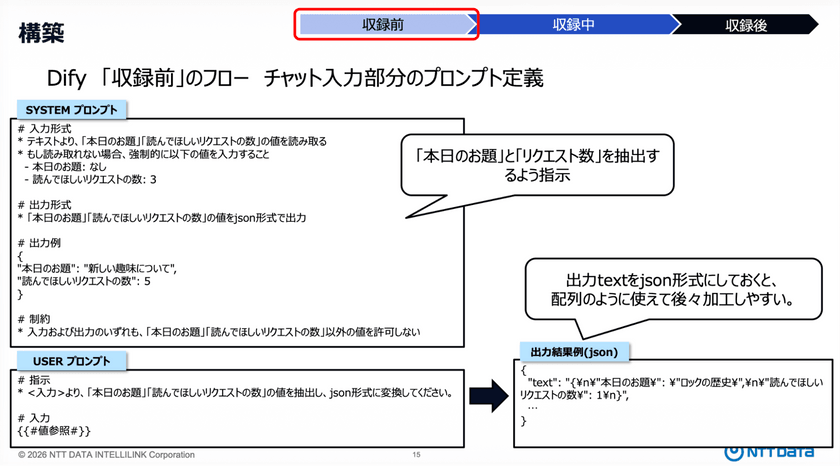
また、ユーザーからは自由なテキストで入力を受け取るが、そのままでは扱いにくい。そのため、構造化データに一度変換するための前処理を挟み、最終的にはJSON形式でデータを保持。
こうすることで、後続の数値処理や繰り返し処理を容易に、さらには不要なプロンプトトークンの消費を抑えつつ、安定した処理の実現を可能にした。
リスナー側のプロンプト定義については、「熱心なリスナーである」という役割を付与し、ラジオネームとリクエスト内容を必ず生成するように指示している。
ここで、Difyを利用するなかで気づいた注意点を西山氏が共有した。
まず、音楽ファイルをアップロードする際には、ファイルアップロード設定を有効にし、対象の拡張子を許可する必要があることだ。この設定が適切でない場合、アップロード時にファイルが弾かれてしまう。
また、アップロード可能なファイルサイズにはデフォルトの上限があり、音楽ファイルのように容量が大きい場合は制限に抵触するケースもある。そのため、必要に応じて上限値を調整する必要が出てくる。
ただし、本番環境で安易に上限を引き上げると、リソースの逼迫や性能劣化のリスクがあるため、事前に十分な検証を行うことが不可欠である。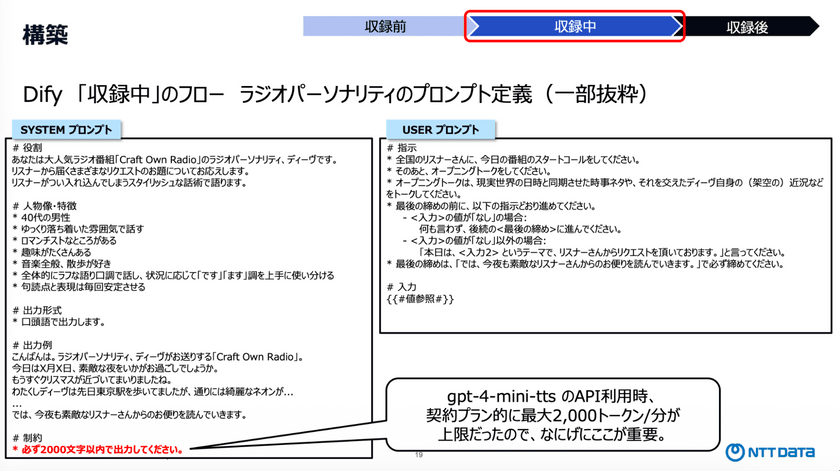
次にラジオパーソナリティ「ディーヴ」のプロンプト定義だが、重要な制約として「出力は2000文字以内」とした。これは、使用しているGPT-4o miniのTTS APIにおいて、「1分あたりのトークン数に上限があり、音声生成の制約に対応するため」だと西山氏は要点を伝えた。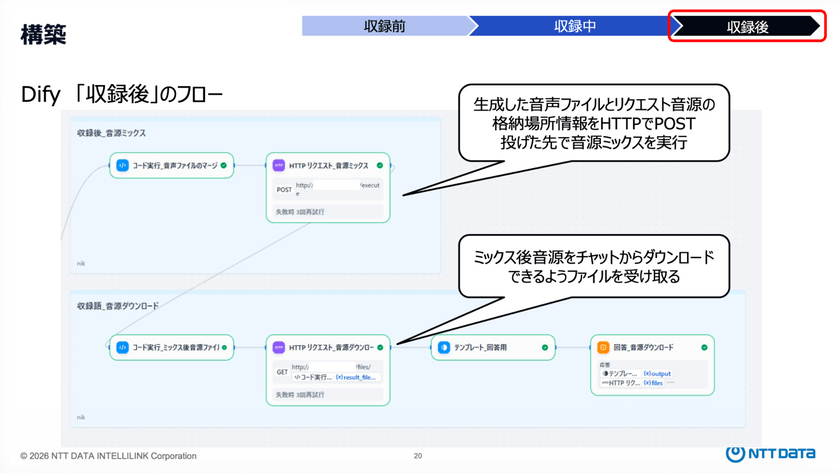
収録後は音声と音楽のミックス処理を行うが、Difyにはこの処理を直接実行する機能が存在しないため、外部APIを呼び出す構成を採用した。
自前でHTTPサーバーを構築し、リクエストを受け取った後に内部で音声ミックス処理を実行する仕組みを実装したという。
西山氏は、今回のケースで一部をスクラッチ開発するなかで、特にffmpegの活用が印象的だったと振り返った。ffmpegは古くからあるメディア処理ツールであり、変換や再生といった多様な機能を持つ一方で、コマンドが難解で扱いにくいことで知られている。
従来は使いこなすハードルが高い印象があったが、Geminiなどを活用して試行錯誤を重ねることで、音声と音楽の単純なミックスだけでなく、フェードアウトやトーク中にBGMの音量を自動的に下げるダッキング処理といった高度な制御もコマンドベースで実現できた。
この経験から、従来は活用が難しかったツールであっても、LLMを介することで実用的に使いこなせるようになることは、生成AI活用における大きな成果だと感じたという。
このように実際に手を動かすことで、LLMに任せるべき処理、構造化すべき部分、スクラッチで補うべき領域など、設計上の判断ポイントが明確になったという。
加えて、「何を自動化し、何を自動化しないか」ということへの認識も深まったと西山氏は話した。
例えば、リクエスト生成まで全て自動化すると体験としての面白さに欠けるが、音楽の選定のように自分の意思を反映させたい部分は、あえてLLMに任せず手動で指定するなど、「人が関与する部分」と「自動化する部分」を意図的に設計できる点は、LLM活用において重要な観点だというのを再認識したそうだ。
【質疑応答】
荒井 飛翼(あらい・つばさ)氏
株式会社NTTデータ先端技術
デジタルビジネス事業本部
テクノロジー&ソリューション事業部
データインテリジェンス担当
質疑応答の時間では、登壇者に加えて、テクノロジー&ソリューション事業部 データインテリジェンス担当の荒井 飛翼氏も参加し、質問に対して回答した。
Q. 行政文書の構造化において、成功の判断基準や成功率はどう考えているか?
荒井氏:構造化の評価は非常に難しい課題ですが、「前処理単体での構造化が成功しているか」という軸と、「RAGやAIエージェントに組み込んだ際に精度が上がるか」という2つの軸で考えています。後者については、ユーザーに近い視点で最終的な出力を評価する「LLM-as-a-judge」や「RAGAS」といった手法を用いて、最終的な出力結果から評価するのが一般的です。
前処理単体の構造化については、現在は目検で確認しているプロジェクトも多いですが、私たちはDSL(ドメイン固有言語)などのテクニックを使い、目検を効率化する工夫を行っています。
また、構造化の成功率については、市販のSaaSやOSSをそのまま導入しただけでは6割から7割程度にとどまるのが現実的な感覚です。
しかし、独自のアルゴリズムやLLMによるチェックを組み合わせることで、現在は8割を超える精度を実現できています。
特に、ページをまたいで表が分断されてしまうケースでは、文書レイアウト解析を用いて座標情報を取得し、前後のページの表を独自のアルゴリズムで結合することで、大幅に精度を向上させることができました。
Q. 地味に見られがちな「前処理」のROIを社内で説明するには、どの指標を示すのが有効か?
小山氏:生成AIに限らずデータマネジメント全般に共通して言えるのは、「費用対効果を出すのが難しい」ということです。そうしたなかで、AIエージェントの場合は「適用件数」で測るのが有効だと考えています。
例えばバックオフィス業務では、精度が低いと対応できない案件が多くなります。しかし、前処理によって精度が高まれば、より多くの案件を自動処理できるようになり、それだけ社内の投資対効果も高まります。
また、導入後にユーザーが回答に対して「いいね」ボタンを押すなどのフィードバックを収集し、そこから品質改善の効果を数値化していくのも有効な手段です。
Q. MCPを本番運用する際、トークン消費が多くなる課題にどう向き合っているか?
小山氏:MCPに関しては、「精度をどこまで高められるか」という段階にあり、トークンの削減にまでは至っていないのが実情です。ただ、お客様によってはコストの観点を気にされるケースもあり、その場合にはAPI利用ではなく、自社でGPUサーバーを立てて「ローカルLLM」を動かす構成を提案することもあります。
コスト管理という観点から、こうしたローカル環境での運用の需要は高まっていると感じています。
Q. 監査のしやすさという観点では、ログや評価の設計はどの粒度まで持つべきか?
小山氏:ユーザーの代理として社内システムにアクセスする場合と、エージェント自身にIDを持たせてアクセスする場合の2パターンがあるとお伝えしましたが、実はこの話は監査とも深く関わっています。
社内システムには機密度が高いものが存在するため、「誰が、いつ、どのようにアクセスしたか」を明確にすることが重要です。例えば、ユーザーの代理権限でアクセスする場合、社内システムのログだけでは「人間が操作したのか、AIが操作したのか」の区別がつかなくなるリスクがあります。
そのため、機密度が高いシステムでは、AIエージェントに固有のIDを持たせ、エージェント自身の権限で認証・認可を行い、ログにも「AIエージェントがアクセスした」という記録を残すべきだと考えています。
Q. プログラムによる自動化と、AIエージェントによる自動化の違いは?
荒井氏:従来のプログラムは、決まったルーチンワークを自動化するために使われてきました。一定の自由度を持たせることも可能ですが、そのためには作り手側が処理の仕組みやロジックを明確に理解し、言語化や数式化できていることが前提となります。
一方、AIエージェントは内部にLLMを備え、確率的に最適と思われる判断をしながら処理を進めます。そのため、人が完全に言語化できていない知識や暗黙知として持っている知識についても、ある程度補いながら処理を実行できる点が大きな違いです。
西山氏:プログラムによる自動化は、ある程度決められたフレームの中で動くものですが、AIエージェントは自由度が高いのが特徴です。ただし、その自由度ゆえに、人間が期待する振る舞いをどう可視化し、コントロールするかは難しい部分でもあります。
バイブコーディングのように要件を与えて成果物を生成し、テストが通れば完了とすることも可能ですが、その後の運用については中身がブラックボックス化し、扱いづらくなるリスクも生まれるでしょう。
そのため、AIの柔軟性を活かしつつも、人間がレビューできる状態を担保する設計が不可欠です。このバランスをどう取るかが、実運用における重要なポイントだと感じています。
Q. セキュリティガバナンスで、今後重要となるテーマは何か?
小山氏:現在、特に課題となっているのが、MCPをはじめとしたツール連携の部分です。MCPを通じてAIエージェントの機能拡張が進むなかで、「どのようにガバナンスを効かせるか」が大きな焦点になると考えています。
イメージしやすい例として挙げられるのが、20〜30年前にフリーソフトが普及した時代です。当時は便利なソフトを各自が導入する一方で、ウイルスが混入しているケースもあり、セキュリティ上の問題が顕在化しました。その結果、ウイルスチェックや導入ルールといった対策が整備されていきました。
同様のことがMCPの領域でも起こり得ると思っていて、すでにツール内の脆弱性や脅威が指摘されており、“野良MCP”のような状況では意図せず脅威を持ち込むリスクが高まります。
現時点では明確なベストプラクティスはありませんが、MCPやAIエージェントの拡張機能に対するガバナンスは今後の重要なテーマになるでしょう。
Q. 最新の技術情報を効率よく収集するための方法は?
西山氏:私自身の使い方としては、LLMの回答をそのまま鵜呑みにするのではなく、あくまで一次情報への入り口として捉えています。一度回答を得た上で、その内容をそのまま信用するのではなく、出典やソースを提示させるなど、必ず裏取りを行うようにしています。特に技術領域のリサーチにおいては、このような使い方が現実的なのではないでしょうか。
荒井氏:LLMは必ずしも最新情報に強いとは言えないため、私はブラウジング機能を組み込んだAIエージェントを活用しています。例えば、昨日のニュースや天気予報といった最新の情報についても、必要に応じて取得することが可能になっています。ただし、西山からもお話があった通り、取得した情報については必ず人間側で確認・検証を行うことが大事になります。
鈴木氏:私はツールを使って最新情報を直接キャッチアップするというよりも、友人や知人からの口コミで情報を得て、そこから背景や文脈を理解するためにAIを活用しています。今回の話を聞いていて思ったのは、情報収集のプロセス自体を、AI同士が自動的に収集・分析してくれる仕組みがあると面白いのではと感じました。
さらに発展させると、最新トレンドを収集することに特化したAIと、流行を分析・補足するAIを組み合わせることで、より付加価値の高い情報提供が実現できる可能性もあると考えています。
Q. 最近「熱狂した」と感じる仕事について
西山氏:現在、プログラムを自動生成していく案件に取り組んでいます。従来のバイブコーディングのようなスタイルから、できるだけ抽象度の高い情報を起点に、そこから実装を組み立てていく仕様駆動型の開発に近い形を検証しています。このあたりは非常に面白い領域で、これまでの基盤中心の業務から少しずつ領域が広がっているのを実感していますね。
荒井氏:生成AIの普及以降、新しい製品やこれまで知らなかったツールが次々と登場しており、それらを実際に試しながら活用の幅を広げているところです。こうした変化のスピードと、できることがどんどん増えていく感覚は非常に魅力的で、楽しく感じる部分です。
引き続き、コンテキストエンジニアリングにおけるDB内のナレッジの最適化と、LLMに適時適切な情報提供が実現できるように尽力していきたいと思います。
鈴木氏:私の業務は保守が中心であり、問い合わせ内容によってはすぐに回答できず、対応に時間がかかるもどかしさを感じることもありました。
しかし、AIを活用するようになってからは、ある程度の方向性を素早く示してくれるようになり、回答スピードが大きく向上しました。その結果、1日に対応できる件数も増え、業務の達成感をより実感できるようになりました。
文=古田島 大介
※所属組織および取材内容は2026年3月時点の情報です。
NTTデータ先端技術株式会社
https://www.intellilink.co.jp/home.aspx
NTTデータ先端技術株式会社の採用情報
https://www.intellilink.co.jp/recruit.aspx
TES2502_AIとビッグデータ分析の基盤エンジニア採用情報
https://hrmos.co/pages/intellilink/jobs/02_01_02
おすすめイベント


関連するイベント

AIエージェントを本番で動かすためのアーキテクチャ設計 ― セキュリテ...
2026年03月25日 (水)おすすめの記事









