【レポート】 TECH PLAY Conference 2017 – 大規模Webサービス #techplayconf2017
はじめに
TECH PLAY主催の事例カンファレンス「TECH PLAY Conference 2017」が、2017年8月20日(日)〜25日(金)の日程で開催されました。
- 【8/20(日) 開催】 クラウド最先端技術 - TECH PLAY Conference 2017 -
- 【8/21(月) 開催】 VRが創り出す世界 - TECH PLAY Conference 2017 -
- 【8/22(火) 開催】日常化されていくIoT - TECH PLAY Conference 2017 -
- 【8/23(水) 開催】デジタルマーケティング - TECH PLAY Conference 2017 -
- 【8/24(木) 開催】急成長する動画市場 - TECH PLAY Conference 2017 -
- 【8/25(金) 開催】大規模Webサービス - TECH PLAY Conference 2017 -
今回は最終日、大規模Webサービス回に参加したレポートです。
今日のイベント、当初は「ビッグデータ」というタイトルでしたが改変したとのことです。ビッグデータを扱う事例が目白押しで紹介されます。
DMM.comのビッグデータ基盤を支える技術
スピーカー:株式会社DMM.comラボ 鈴木 翔太 氏 / 吉田 龍馬 氏
弊社ビッグデータ部では、オンプレミス環境で Hadoop をベースとしたデータ基盤の保守運用を行っており、それに加えアドホック分析には Presto、エンジニア・アナリストが利用するBIツールとして Zeppelin / Re:dash、ETLにワークフローエンジンDigdagなど様々なOSSを積極的に採用し、より快適な分析基盤の構築に努めています。当セッションでは、そんなビッグデータ基盤を支えている技術と活用事例についてご紹介します。
自己紹介

- 鈴木さん(twitter ID: @i_szyn) 写真右
- DMM.com Labo システム本部 ビッグデータ部所属
- Node.js を利用した内製BIツールの開発
- セグメンテーションエンジンの設計・開発
- ミドルウェア検証や導入
- 吉田さん(twitter ID: @ryysud) 写真左
- DMM.com Labo システム本部 ビッグデータ部所属
- Node.js を利用した内製BIツールの開発
- トラッキングシステムの開発、刷新
- AWS を活用した分析基盤の検証
会社紹介
- DMMは1999年からサービス開始
- 最近はVRも手掛けている
- 事業毎にグループ会社に分かれている
- 株式会社DMM.com Labo
- 主にシステム開発・運営を行っている
- 約550人がエンジニア
- ビッグデータ部
- 最近はアナリストとしての役割も担当
- 内製のAPI用意していて、不正ユーザや利用率を調べている
- 対外活動として最近はSpark周りで講演している
- Sparkを活用したアジアパシフィック初のレコメンド基盤実現 | Cloudera
- DMM.comラボとIDCフロンティア、コンテンツレコメンドの精度向上を共同検証 | IDCフロンティア
システム全体図
最初は吉田さんが発表

- 左側:ユーザトラッキング
- Node.js APIでユーザの行動を取得
- Aerospikeはアクション経由
- Consumer部分は可用性重視してErlangを採用
- 中央:分析基盤(Hadoop)
- Cloudera社のCDH(Cloudera's Distribution including Apache Hadoop)を利用
- Cloudera Managerで運用コストを削減
- 動的リソースプールを使用して、昼はアドホック、夜はバッチ集計に編成
- Jenkinsを利用していたが、現在は利用していない(経緯は後述)
- この分析基盤には課題があった
- CDHクラスタのリソース不足
- アドホッククエリが遅い
- 日次バッチがJenkins依存
- これらの課題を以下の取り組みで解消した
課題解決の事例紹介
現在のシステム全体図

CDHクラスタ移行
- 課題
- ログの増加で会員数が増加
- 会員数の増加に伴う行動ログなどの増加
- 改善
- 最新CDH採用(5.7.1 → 5.10.0)
- ディスク増強(57.5TB → 1.4PB)
- メモリ増強(1.7TB → 5.1TB)
- クラスタ移行
- 並行稼動は2週間
- 障害テスト、チューニングも実施
- 障害試験実施
- バッチ処理中に構成要素を停止
- チューニング実施
- OSのパラメータを変更
- 一番効果的だったのは、Mapの処理の効率化
- ファイルフォーマットの見直し
- 圧縮をBzip2からSnappyに変更
- 圧縮形式を見直したことで高速化に成功
- バッチの処理時間が約半分に短縮
- CDHのバージョンアップ
- Sparkのバージョンも上がったことでAPIが充実
- エラーメッセージが賢く
Presto導入
ここから発表を鈴木さんに交代
- 課題
- Hive on MapReduceが遅い
- バッチ処理に時間がかかってしまう
- 解決策としてPrestoに目をつけた
- Prestoとは
- Facebook社が開発したクエリエンジン
- 標準SQLを採用
- Amazon Athenaも裏で使っている
- 構成のポイントはPresto環境を2つ用意したこと
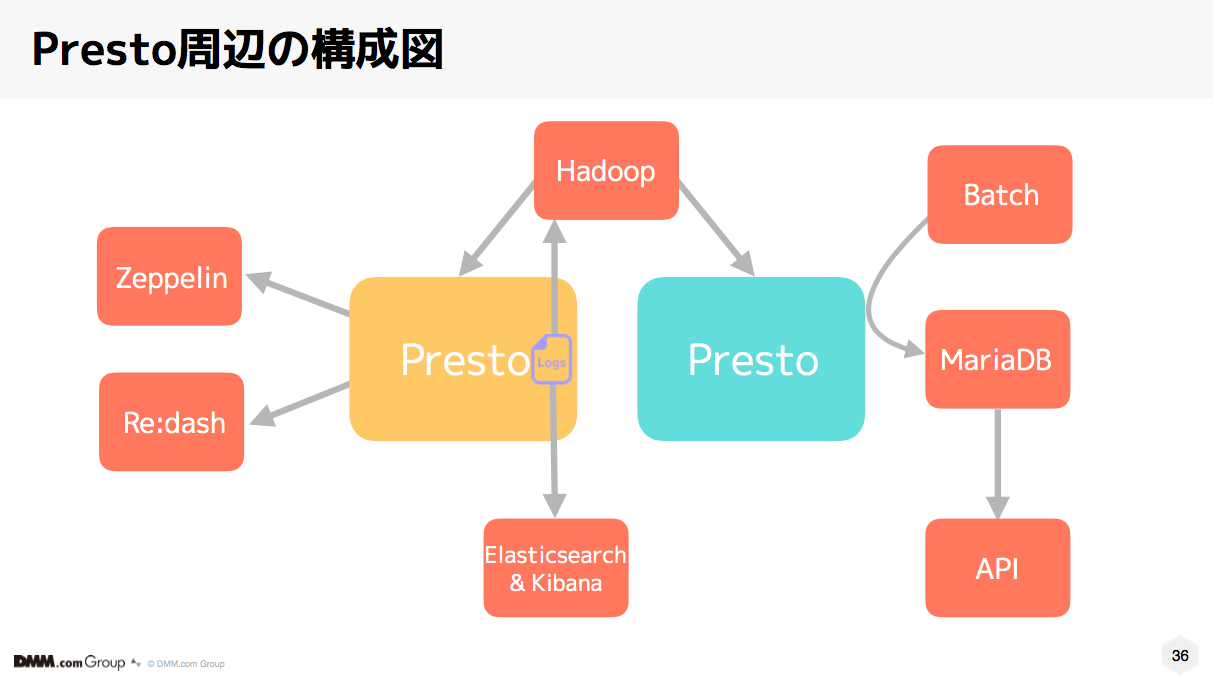
- 黄色は分析環境
- Re:dash、Zeppelinから実行
- 沢山のクエリが流れるので長時間のクエリはキャンセル
- Coodinator 1 + Worker 20の21台構成
- 青はバッチ用
- APIから他システムに抽出して連携する
- 抽出データはMariaDBに格納してAPIから参照
- 冗長化の為Coodinator2台
- Workcer 6台と合わせて8台構成
- HiveとPrestoのパフォーマンス比較を行った
- 1テーブルに対するクエリを3つのパターンで比較
- 結果、圧倒的にPrestoが速かった
- ここが良くなった
- Hiveと比較しアドホックな集計が速くなった
- バッチ処理もPrestoで高速化
- Prestoを使用した事例の発表
Digdagへのリプレイス
- 課題
- 日次バッチがJenkins依存
- フローがコードで管理できていない
- 依存関係が見れないのでリトライが大変
- Digdagとは
- Treasure Data社が開発するワークフローエンジン
- YAMLのDSLで管理できる
- タスクの状態はPostgreSQLに永続化して可用性維持
- タスクの分散、並列実行も可能
- 日次バッチの内容
- ETLが主
- 23の日次ワークフロー
- 保持しているデータ
- Hadoop上に集約
- 40以上のサービス向けのデータ
- 個人情報は除いている
- Digdagの構成
- Serverを冗長化のために2台
- Watchdogで仮想IPを制御
- PostgreSQL2台
- タスクが分散して実行されるのでLsyncd + rsyncでタスクログを双方向同期
- ETLの概要
- Hadoop DataNodeから事業部のDBに接続&データ取り込み(E)
- Hiveでデータ加工、集計(T)
- MariaDBへ転送(L)
- 良くなったこと
- 処理フローもGitでコード管理
- 依存関係の見通しが良くなった
- Web UIからリトライ簡単になった
- Digdagを利用した事例の発表
まとめ
- 得られた成果
- CDHクラスタ移行により
- リソース増強&チューニングによるジョブの高速化
- Presto導入により
- アドホック分析が高速に
- 高速なバッチ集計処理を実現
- Digdag導入により
- 日次バッチの見通しが改善
- 並列処理により処理が高速化
- 今後の展望
- ユーザ行動ログが利用できるまで最短1時間
- リアルタイム性を重視したアーキテクチャへ
- 全社利用の際のオンプレリソース不足をAthena等AWS利用で解決へ
Applying Machine Learning: 機械学習の力でヤフートピックスのタイトルを予測する
スピーカー:ヤフー株式会社 村尾 一真 氏
参考記事
AIで13.5字要約に挑むヤフトピ、過去10年分30万件を機械学習 | 日経トレンディネット
パーソナライズニュースを支えるML業務のまわしかた@Yahoo! JAPAN | SlideShare
自己紹介

- 2012年ヤフー株式会社入社
- 入社時から一貫して機械学習系、言語処理系のプロダクトに携わる
- 主な開発プロダクト
- 短文投稿のネガポジ分析アルゴリズム
- スマホ版トップページタイムラインの機械学習アルゴリズム
- (本セッションで紹介) Yahoo!ニュース トピックスのタイトル生成支援ツール
DEEP Lerning

- ここ数年において「AI」「人工知能」という言葉が世間を席巻している
- DeepMind社(Google傘下)のAlphaGoが世界最強の棋士に勝利
- 人工知能はどういうイメージ?
- ブラックボックスのイメージ
- 問い合わせれば答えてくれる
- しかし、魔法の箱ではない
- Deep Lerningなどはエンジンであり、それだけでは動かない
- 機械学習だけではサービス改善できない
- エンジンを動力に変えてユーザに届ける仕組みが必要
Applying(Applyする)

- 「Applyする」とは、エンジンやアルゴリズムを、サービス改善に繋げるための仕組みやシステムとして実装すること
- データサイエンスのプロダクトを業務に生かす為の非常に重要なフェーズ
簡単な例「2015年にリニューアルされたスマホ版のトップページ」

- 左が旧、右が新
- 機械学習に寄るパーソナライズを実施
- サービス実装には色々考えなければならないことがある
- 新規ユーザに何を表示するか?
- コンテンツの偏りは?
- 災害時などアクセス集中時にはどうあるべきか?
- 機械学習のエンジンは強力だが、システムを利用するユーザに一番いい形で届ける事が不可欠である
直近の「Applyすること」への取り組み

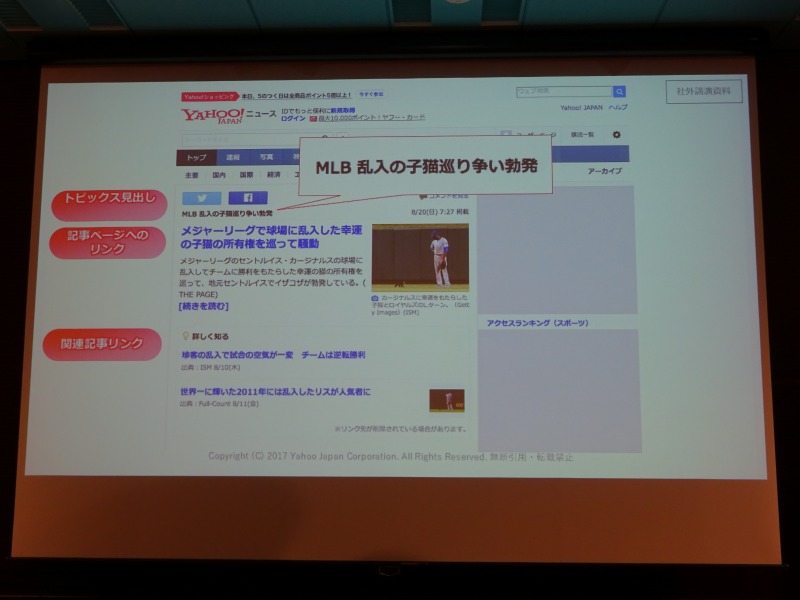
- Yahoo! Japanの編集ページの例
- 編集者は記事ページ、関連記事へのリンクを作成する
- タイトルを考え、トピックス見出し(Yahoo!トピ)を作成し、トップページに掲載する
- トピックス見出しは13文字 + 半角1つの制約があるので、編集者はその制約の中で、内容を的確に表しつつ興味を引く文言にする必要がある

- トピックス見出しはニュースの記事見出しから作られる
- 短いタイトルに色んな要素を埋め込むため編集者の手により変えられる
- マー君(3文字)が田中(2文字)に
- 実際にはより工夫されたタイトルが作成される
- 編集者やユーザの知識、世間で何が流行っているか
- 見出しの作成をルール化するのは大変
- 以前取り組みがあったが、ルール化の実現は非常に厳しかった

- 深層学習に注目
- 正解が付いている学習データを元に、想定した回答が得られるようアルゴリズムのパラメータを調整
- 新しいデータにそれらしい出力を得ることができる
- 一定の制約の中で文字列がペアとなる場合に広く使われる
- これを見出しの作成に適用

- 新しいデータを入れると幾つかの候補
- 左が元ネタ、真ん中が編集者、右が機械で出力したもの
- 必ずしもすべての例でうまくいくわけではない

- 一般の人に見てもらった
- 可読性(左)は表現が文法的に間違っているか
- 有用性(右)は内容を適切に表現しているか
- その後上手くいかないケースがある
- 編集者の想像していたレベルと違っていた
- 想定シーンが異なっていた
Applianceへの5つの取組み

1. 課題の把握
- ユーザ(編集者)の課題の聞き込みを徹底的に行う
- トピックス作成業務を効率化したい
- 熟練編集者のノウハウを新人に早く獲得させたい
- 誤った見出し作成のリスクを回避したい
2. 解決法とシステム考案
- アルゴリズムまでにらみながら考える
- どこをターゲットにするか
- どの編集フローに組み込むと効率化できるか
- その方法で将来性はあるか
3. アルゴリズムの実験・開発
- 論文を読んでキャッチアップ
- 現在の課題に適用できるか考える
- 柔軟性のあるアルゴリズムにするか、コンサバ化(誤った記事を作成する可能性を低く)するか
- 検討の結果、編集者の支援ツールとしてアルゴリズム導入を決定
4. システム化・効果検証
- トピックス作成支援ツールとして活用
- 複数の候補を表示(ダイバーシティを意識)
- 記事と異なる表記は自動で注意表示
- 短縮語辞書機能
- 最後は人(ユーザ)の手と目で確認
5. チームとしての距離感の重要性

- 中心となるアルゴリズムを知っているデータサイエンティストが果たす役割
- チームの中でお互いに役割を補う
- スモールチームの距離感で(物理、会話)が重要
- 両方の強みを生かす(編集のプロ + データサイエンス)
- 今後の知見やモデルを社内展開
- ニュース以外のサービスについては完全自動化もテスト始めたい
まとめ

リクルートにおけるビッグデータ活用:A3RTのご紹介
スピーカー:株式会社リクルートテクノロジーズ 薬師寺 政和 氏
リクルートテクノロジーズでは、これまで個々のサービスニーズに沿ってスクラッチ開発していた機械学習ソリューションを、より早く、簡単にグループ内のサービスに展開するためのAPI群である「A3RT(アート)」として構築しました。この「A3RT」の中でもChatbotプロダクトを例に、リクルートテクノロジーズにおけるビッグデータ・AIのビジネス活用についてお話します。
参考記事
リクルートが展開する機械学習API「A3RT」と基盤としてのクラウド活用について | SpeakerDeck
A3RT -The details and actual use cases of“Analytics & Artificial intelligence API via Recruit technologies" | SlideShare
自己紹介

- 株式会社リクルートテクノロジーズ ITソリューション統括部 ビッグデータプロダクト開発グループ
- ビッグデータソリューションの提案・開発・導入
はじめに
リクルートについて

- リクルートのビジネスモデル
- マッチングモデルに基づいたビジネスを展開している

- ユーザ-クライアントを結びつける
- 例えば教育、就職活動、出産、転職
- ライフイベントの選択をサポート
リクルートテクノロジーズについて

- グループ全体で7つの主要事業会社と3つの機能会社でできている
- リクルートテクノロジーズは機能会社の一つ
- 事業会社にITソリューションを提供
- システム開発、Web、インフラ、セキュリティ、ビッグデータなど
ビッグデータ解析部門について

- 各事業に特化したソリューションを提供
- ソリューションを軸として、横断的にプロダクト導入している
- 行動ログのデータを扱っている
- 最近は行動ログ以外の、テキストや画像も積極的に取り組んでいる
A3RTについて
A3RTとは

- A3RTとは、社内で統一、整理したAI系ロジックのブランド
A3RTの中のプロダクト

- A3RTの中には色々なプロダクトが含まれる
- レコメンド・推薦API
- 過去のユーザ履歴に基づいたレコメンド提供
- 決まったフォーマットでデータを置くと類似データを出力
- 中身のロジックもケースに併せて選択可能
- 画像解析API
- 汎用的なロジックを採用
- クライアントから入稿される画像の内容を判断
- 文章サジェストAPI
- 原稿の学習と自動作成
- 熟練者の文書作成を新人ができるようサポート
- 自動校閲API
- ルールベースと機械学習のハイブリッド
- 誤字脱字の自動検出
A3RT導入の経緯
- 機械学習ソリューション活用の敷居はまだまだ高い
- 活用をスピードアップ、スケールする為に工数を多く必要としている
- 最新のアルゴリズム、ソリューションでもビジネスの課題にピタッとはまらないと活用されない
- 案件毎のフルスクラッチではコストが掛かる、全てのケースに対応できない
- 外部APIはそのままでは機能が足りなかったりする
- リクルートグループに適したサービスをAPI化
- 導入のハードルを下げる
- 選択の幅を広げる
- 最新のソリューションを継続的に提供
Chatbotについて
Chatbotとは
- チャットインターフェースで動くBot
- 挨拶を返す
- 「ログインできない」などの質問に対応
活用例(ゼクシィ恋結)
導入の背景
- サービスの拡大に伴う問合せ件数の増加
- 5000件(/日?)以上
- 問合せ内容はログイン忘れ、パスワードなど簡単な質問が多い
- Bot導入で簡素化
Chatbot導入後
- 問合せ率34.1%削減
- Chatbotに対する苦情はなし
- 利用時間帯
- 深夜(22:00〜23:00)がピーク
- 休日など営業時間外に応答可能なのはUX向上に効果的
裏側

- 検索エンジンと機械学習のハイブリッド
- 会話ログを学習データに還元して回答精度を半自動的に向上
- CNN(Convolutional Neural Networks)によるテキスト分類
- カテゴリとテキストを準備
- 分類モデルを学習させる
- 新しい質問に該当するカテゴリを推測
- 質問後のユーザに対するアンケート「この回答は、お役に立ちましたでしょうか?」で質問を評価し、学習データに還元
- 「サイトに入れません」のような用意していなかった質問にも自動で対応させる
- 機能をパーツのように組み立てることが可能になるよう設計
横展開の展望
ユーザ向けだけでなく、下記全てにBot導入の余地がある
- リクルート - クライアント間
- リクルート - ユーザ間
- ユーザ - クライアント間
- リクルート内部
さいごに

- A3RTの一部のサービスの一部機能をAPIを社外公開しているので使ってください
フリマアプリ「メルカリ」の多様なデータと機械学習
スピーカー:株式会社メルカリ 山口 拓真 氏
メルカリでは、多様で大量のデータが日々増え続けています。出品時に入力される、商品説明文やタイトルのテキストデータ、商品カテゴリやブランドのカテゴリカルデータや商品画像データ、さらには、お客さまの商品検索・閲覧・購入といった行動の時系列データ、お客さま同士の価格交渉や商品取引の対話データなど、多岐にわたります。当セッションでは、これらのデータを活用したサービスの改善事例や取り組みについて紹介いたします。
自己紹介

- 学生時代から、画像解析、パターン認識の研究を行っていた
- 研究内容に関連する業務に従事
- OCR、音声認識
- 画像認識、改札、駐車場、監視カメラ
- 2011年頃、この分野のビジネスの展開がなさそうと思い、Web系の企業へ転職
- データ分析基盤の開発、運用
- Hadoop、Spark、Hive、Presto
- 2016年、メルカリに入社
- サーバーサイド
- 画像認識を中心とした機械学習
メルカリとは

- フリマアプリ
- 1日あたり100万出品
- 毎日200〜300万枚の写真
- ラベル(教師データ)付きでホント学習しやすい
メルカリのデータ

- 出品データ
- 商品画像
- 商品説明
- 行動データ
- 商品検索
- タップ
- いいね
- 交渉
- 問合せ
- 通報
- 最近はライブフリマ(動画データ)
- 今後は動画データの認識や分析も必要になる
商品検索とタップ
- 「mac」と入れたらPC?化粧品?
- 検索結果にカテゴリ(PC or コスメ)を出してあげれば機械学習を使わなくても良い
- 検索アルゴリズムの改善
- 本体と付属品問題(付属品ばかりで本体が表示されない)

- 付属品の方が本体より出品件数が多い
- アルゴリズム改善で対応
- 本体と付属品問題(付属品ばかりで本体が表示されない)
デモグラフィック情報、趣味嗜好の推定
- 女性男性のタイムラインの出し分け

- (USでは先月インターフェースを大幅に更新)
- 性別が分かるユーザの行動を比較
- タップ順のページタイトルを単純に文字列化 → TF-IDFでベクトル化
- 趣味嗜好の推定

- タップ順をクラスタリング
- プッシュ文言の出し分けに便利
- 関連ワードの抽出

- Word2Vecで文字の距離を抽出
- [ワンワン, うーたん]、[ダウン, ダウンジャケット]など
- 商品のIDを並べてベクトル化
- 運営側がグルーピングしなくても、行動ログでグループ化される
カスタマーサポートへの機械学習の適用(商品通報)
- 商品通報機能
- 通報を問合せと勘違い、興味本位で押されるなどがある
- 今はスタッフが対応
- カスタマーサポートへの機械学習の適用
- CtoCだと何が起きるかわからない
- 普通はコスト削減だが、プロアクティブなサポートに使いたい
- 取引を揉める前に発見し、スタッフが間に入る
- USでテスト中
画像認識・画像検索の取り組み
画像認識の取り組み

- Convolutinal Neural Networkを使うだけで結果が出る
- かなり高い確度
- 中間層を特徴ベクトルとすることで類似画像検索も可能
カテゴリ認識

- Inception-v3というネットワークのモデルを使用
- 220万枚の画像を入力
- 1108カテゴリ(出品数が少ないカテゴリは除外)
- GPU8枚の環境で60時間学習
- 1108カテゴリから正解を当てた率44.7%、5位までで70.7%
- カテゴリ分類が非常に細かいので、実際には概ね当たっている
- 人形の写真は"ハンドメイドの服"
- 米も高い精度で判断
ブランド認識

- ブランド画像の認識は難しいが、メルカリなら膨大な教師付きデータで学習しているので認識できる
- ロゴを見つけるより画像の雰囲気で判別している
- 靴底見せても判断できる(スコアは落ちる)
- バッグ
- 布地に特徴がある(モノグラムなど)とかなり高い識別率
- ロゴがなくても、ポケットの蓋の形に特徴があれば判別
類似画像検索


- 全結合相の数値ベクトルを取り出して比較
- 1000万枚であればMBPで10msで処理できる
色認識

- 色データはInspection-v3モデルの初期で失われる
- 10層以下のモデルを使って対応する
- 背景と前景と分離して、前景の色を抽出
今後の取組(まとめ)
- 機械学習、画像認識楽しい
- いかに機械学習を使ってサービスを良くするかを考える
今週MAISONZをリリース

- ブランドに特化したC to Cサービス
- 機械学習使っている
- 画像を撮ればブランド(CHANEL, LOUIS VUITTON)を自動判別
まとめと感想
TECH PLAY Conference 2017の最終日、大規模Webサービス回に参加したレポートをお伝えしました。
経営活動の中で得られる膨大なデータを元に、分析や自動処理の精度を上げ、サービスをどんどん進化させている企業の取り組みを見ることができました。この取り組みのサイクルが次にどのような変化をもたらしてくれるのか、とても楽しみです。
また、ビッグデータを扱える技術者という職種が、企業の中で必要性を増している状況も見ることができたような気がしました。日頃ユーザとして使っているサービスの裏側に回り、膨大な生データで世の中を知り、またそのデータを使って世の中に影響を与えていくのは、システム開発とまた異なる面白さがあると思いました。
次回のTECH PLAY Conferenceは、半年を目標に1年以内の開催を予定しているとのことです。楽しみにしておきましょう。それでは、また。
<執筆者>
クラスメソッド株式会社
甲木 洋介
おすすめイベント


関連するイベント

【8/25(金) 開催】大規模Webサービス - TECH PLAY ...
2017年08月25日 (金)おすすめの記事